Prompt Debt: How We Doubled Throughput Without Changing the Model
A Parjanya v2.0 field note on inferencing, information waste, and why deleting things sometimes creates more value than adding them

In May 2026, I found myself staring at a familiar engineering problem.
Parjanya’s Image Quality Assessment pipeline was approaching the limits of what our infrastructure could comfortably handle.
Inference workloads were growing.
Batch sizes were increasing.
Memory utilization was climbing.
And eventually, the system hit a wall.
A larger image.
A slightly bigger batch.
A little more context.
And then:
CUDA Out of Memory.
The obvious answer was straightforward.
Upgrade the hardware.
Move to larger GPUs.
Increase the budget.
Scale vertically.
That’s what I almost did.
Instead, I opened the prompt.
And that decision ended up saving far more money than a hardware upgrade would have.
The Assumption I Didn’t Question
By this point in the Parjanya v2.0 journey, I had spent months thinking about infrastructure.
The previous two posts in this series covered:
Multi-account AWS architecture
Terraform and operational discipline
CI/CD pipelines
IAM boundaries
Infrastructure scaling
So when inference started becoming expensive, my instinct was predictable.
I looked at the hardware.
That’s what engineers do.
We assume the bottleneck lives where the graphs are red.
GPU memory usage was high.
Throughput was flattening.
Batch sizes were constrained.
The diagnosis seemed obvious.
But infrastructure metrics were only showing symptoms.
They weren’t showing the cause.
The Audit That Changed Everything
Instead of pricing larger GPUs, I decided to audit the prompt itself.
At that point our VLM-based IQA system had evolved through multiple versions.
Each release added new capabilities:
Better composition evaluation
Improved wildlife classification
More robust defect detection
Additional structured outputs
More nuanced confidence handling
Every version added knowledge.
Almost nothing removed knowledge.
The prompt had become a living document.
Like most living documents, it accumulated debt.
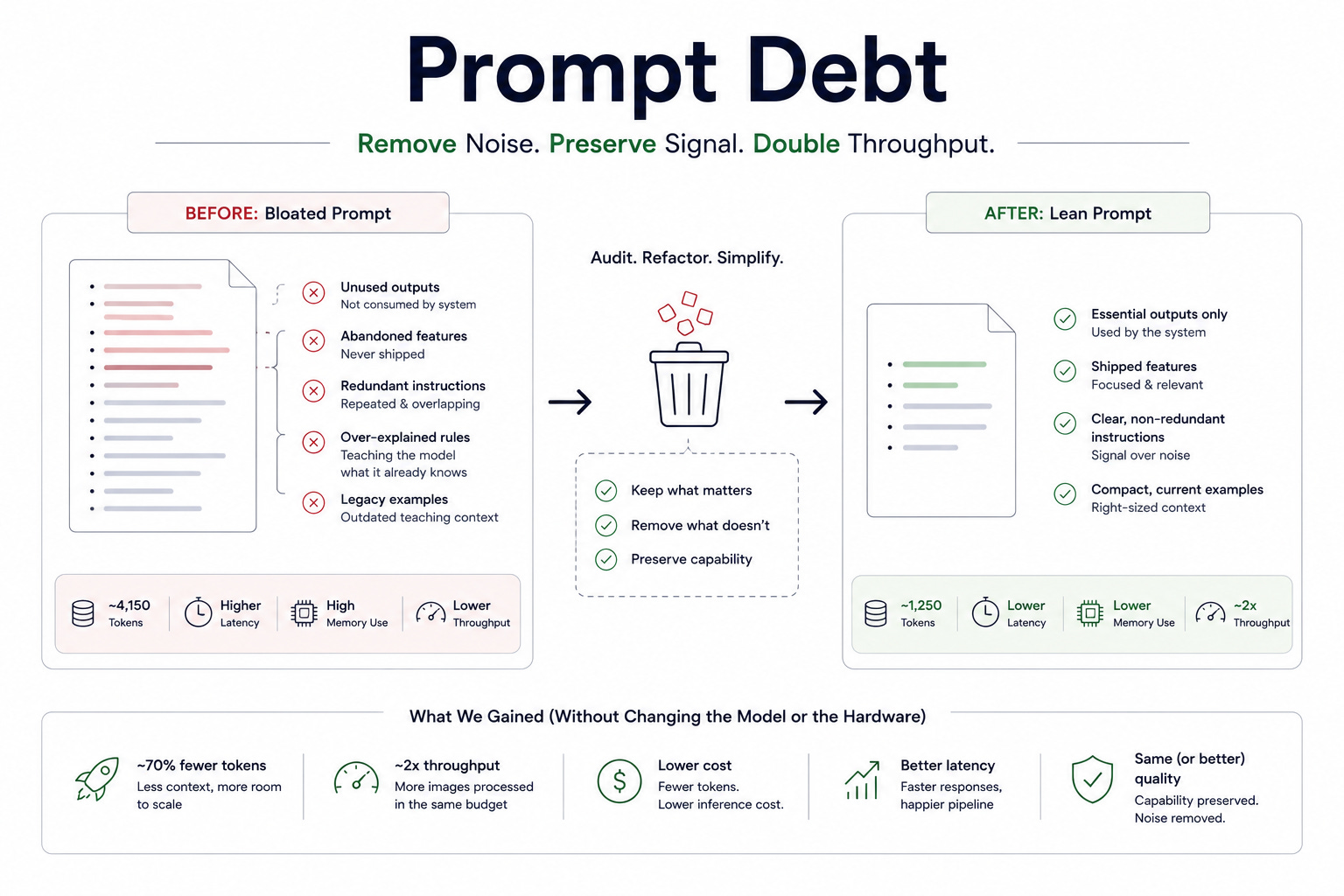
When I finally measured it, the numbers surprised me.
The system prompt plus user context had grown to roughly:
4,150 tokens
Not because we needed 4,150 tokens.
Because nobody had challenged whether we still needed them.
What I Found
The easiest way to describe it is this:
The prompt looked less like a carefully engineered system and more like a codebase that hadn’t been refactored in years.
There was useful logic.
There was historical baggage.
And there was a lot of dead code.
Unused Outputs
One section calculated an overall quality score.
The model spent tokens reasoning about it.
The downstream system ignored it completely.
The actual acceptance and rejection decisions came from deterministic rules elsewhere in the pipeline.
The score existed because an earlier version needed it.
The current version didn’t.
Yet the prompt still carried the instructions.
Features That Never Shipped
I found sections generating:
search tags
mood descriptions
discovery metadata
These outputs were originally intended for future content discovery features.
Those features never launched.
The instructions remained.
Every inference paid the cost.
Every single time.
Teaching the Model Things It Already Knew
This was the biggest surprise.
Over time we’d added examples.
Then more examples.
Then explanations for the examples.
Then explanations explaining the explanations.
The prompt contained long sections describing:
composition techniques
confidence scoring
framing recognition
classification behavior
At one point those explanations were useful.
But the model wasn’t learning from scratch anymore.
The explanatory scaffolding had become informational overhead.
The rules mattered.
The essays explaining the rules did not.
I Started Thinking About It Like Technical Debt
The moment everything clicked was when I stopped calling it prompt engineering.
This wasn’t prompt engineering.
This was refactoring.
The exact same process we apply to software.
In software we ask:
Is this function still used?
Does this dependency still matter?
Is this abstraction providing value?
Can this code be simplified?
I realized prompts deserve the same scrutiny.
A prompt is infrastructure.
It consumes resources.
It affects latency.
It affects throughput.
It affects cost.
And like any infrastructure, it accumulates debt.
I started calling this:
Prompt Debt.
What Stayed
This is the part that surprised me most.
Almost all of the intelligence survived.
The capabilities remained intact.
The model still knew how to:
recognize deliberate composition
distinguish artistic choices from technical defects
apply confidence-aware wildlife classification
detect focus issues
identify exposure problems
generate structured outputs
evaluate image quality
We didn’t remove intelligence.
We removed repetition.
We removed explanation.
We removed historical residue.
The distinction matters.
The Numbers
After the audit:
System Prompt
~700 tokens → ~360 tokens
User Prompt
~3,450 tokens → ~890 tokens
Total Context
~4,150 tokens → ~1,250 tokens
Approximately:
70% reduction
without changing:
the model
the hardware
the infrastructure
the deployment architecture
Only the prompt changed.
Why 70% Matters
It’s tempting to see this as an academic optimization.
It wasn’t.
Those tokens had real operational consequences.
Every unnecessary token consumes:
memory
compute
latency budget
throughput capacity
On paper, a token looks small.
At scale, thousands of unnecessary tokens become infrastructure.
And infrastructure costs money.
Before the cleanup, our batching limits were constrained by context size.
After the cleanup, we could process roughly twice as many images within similar memory budgets.
The result was effectively:
2x throughput without changing hardware.
The kind of gain most teams expect from an expensive infrastructure project.
We got it from deleting text.
Every Token Has a Cost
This became the biggest lesson of the entire exercise.
Engineers often think about infrastructure costs.
Few think about information costs.
Every token carries a burden.
A token occupies memory.
A token increases inference time.
A token competes for attention.
A token introduces complexity.
The question isn’t:
“Can the model read this?”
The question is:
“Should the model be reading this at all?”
Those are very different questions.
This was a practical reminder of a lesson I explored earlier in Grounding Is Not a Prompt. Models don’t become more faithful simply because we provide more instructions. What matters is the quality and relevance of information available at inference time. A smaller, denser prompt often outperforms a larger one filled with historical baggage and explanatory noise.

The Broader Pattern
The more I reflected on the exercise, the more it felt familiar.
This pattern appears everywhere.
Organizations accumulate meetings.
Software accumulates dependencies.
Infrastructure accumulates services.
Prompts accumulate instructions.
Over time, complexity grows through addition.
Rarely through subtraction.
Most systems become slower because nobody asks what can be removed.
Prompts are no different.
While reviewing the prompt, I kept thinking about a principle we previously discussed in Databases, Caches and Queues: A Universal Rule for Distributed Systems. Systems become resilient when information has clear ownership and purpose. The same principle applies to prompts. Every instruction should exist for a reason. If nobody consumes it, it becomes operational debt.
Databases, Caches and Queues: A universal Rule for Distributed Systems

Modern distributed systems fail not because of scale, but because of misplaced responsibility. As systems grow asynchronous, replicated, and fault-tolerant, confusion often arises over what represents reality, what represents optimization, and what represents
The Connection to Inferencing
This experience fundamentally changed how I think about inference optimization.
Most conversations focus on:
larger models
larger context windows
larger GPUs
more sophisticated hardware
Those matter.
But they’re not always the first lever.
Sometimes the most effective optimization isn’t computational.
It’s informational.
Before changing the model, review the prompt.
Before upgrading the GPU, review the prompt.
Before increasing context windows, review the prompt.
The cheapest token is the one you never generate.
What Comes Next
Prompt reduction was only one layer.
The next frontier involves serving optimization:
prompt prefix caching
KV cache reuse
vLLM batching improvements
quantization strategies
memory-efficient inference
Those areas still offer meaningful gains.
But they sit on top of a more fundamental principle.
Optimize information before optimizing infrastructure.
The Takeaway
When the system first ran out of memory, I assumed we had a hardware problem.
What we actually had was an information problem.
The model wasn’t struggling because it lacked capacity.
It was struggling because we were making it carry unnecessary baggage.
That distinction changed how I think about AI systems.
We often assume progress requires adding something.
A larger model.
A larger GPU.
A larger context window.
A larger budget.
In this case, the breakthrough came from subtraction.
The model already knew enough.
The system simply needed less noise.
And that’s a lesson that extends far beyond prompts.
It’s a lesson about engineering itself.
This concludes the initial Parjanya v2.0 engineering series. Across these three posts—from AWS account boundaries, to Terraform discipline, to prompt debt—the common theme has been surprisingly consistent: systems scale best when boundaries are clear, assumptions are explicit, and unnecessary complexity is removed. The challenge is rarely adding more. The challenge is knowing what to keep.
Further Reading
If this article resonated with you, these related essays expand on the ideas discussed here:
Grounding Is Not a Prompt — Why better information retrieval often matters more than adding more instructions to a model.
VLM Batch Inference - 4 bit quantisation depth — The Hidden Cost of “Almost Fitting”
Context Engineering and Context Debt — a data investigation that revealed ~77% of my token spend was context accumulation waste, not productive reasoning. This is the framework I built to fix it — and the problem has a name: Context Debt and the fix is: Context Engineering .
Databases, Caches and Queues: A Universal Rule for Distributed Systems — The Truth, Belief and Intent framework that inspired how we think about information flow across systems.
TBIE in Practice: Designing Resilient AI Pipelines That Recover, Reconcile, and Re-run - Reconciliation loop and TBIE model with case studies with Parjanya v2.0
Terraform at Scale: What Actually Worked, What Didn’t, and the Cost of Trusting AI with Infrastructure — The previous post in this series, exploring operational discipline and infrastructure boundaries.
Why We Use Three AWS Accounts (Not Two) for Parjanya v2.0 — The architectural foundation that enabled the optimizations described here.
Introducing the Inferencing Series
This article marks the beginning of a new series exploring inferencing as a first-class engineering discipline. Much of the AI conversation today revolves around models, benchmarks, and training. Yet in production systems, the economics and behaviour of AI are often determined long after training is complete—during inference. The choices we make around prompts, context, quantization, batching, memory management, caching, retrieval, and serving architecture frequently have a greater impact on cost, latency, and reliability than changing the model itself.
Throughout this series, I’ll share lessons learned while building and operating Parjanya’s Visual Language Model (VLM) pipelines. Rather than focusing on LLM chat applications, the emphasis will be on real-world image understanding systems: image quality assessment, wildlife classification, structured extraction, multimodal reasoning, and the engineering decisions required to run them efficiently at scale. The goal is not simply to reduce costs, but to understand how information flows through an AI system and where meaningful optimization actually lives.
Why Start With Prompt Debt?
Prompt Debt is an ideal starting point because it reveals a common misconception about AI systems: that performance improvements come primarily from adding more. More instructions. More examples. More context. More hardware. In practice, many mature VLM systems accumulate informational debt in the same way software accumulates technical debt—unused outputs, redundant instructions, abandoned features, and historical assumptions that continue consuming resources long after they stop creating value.
Future articles in the Inferencing Series will build on this foundation by exploring quantization, context engineering, grounding strategies, serving architectures, prompt caching, KV-cache optimization, batching, multimodal pipelines, and the operational realities of running VLM workloads in production. Prompt Debt is simply the first lens. The broader question—and the one that interests me most—is how to maximize signal while minimizing computational waste across the entire inferencing stack.