Databases, Caches and Queues: A universal Rule for Distributed Systems
Why truth, belief, and intent must never be mixed — from SaaS to ML/AI platforms

Modern distributed systems fail not because of scale, but because of misplaced responsibility. As systems grow asynchronous, replicated, and fault-tolerant, confusion often arises over what represents reality, what represents optimization, and what represents future action.
This article introduces the Truth–Belief–Intent Rule, an architectural principle that cleanly separates system responsibilities:

🗄️ Databases define truth — the authoritative, durable record of reality
⚡ Caches represent belief — optimized, temporary approximations of truth
📬 Queues express intent — asynchronous requests for future work under uncertainty
By enforcing this separation, architects can design systems that remain correct under retries, partial failures, stale reads, and scale. The rule applies universally across SaaS platforms, event-driven systems, CQRS and event sourcing architectures, and modern AI/LLM pipelines.
This post explores the principle, explains why violations lead to systemic failures, and shows how adopting the Truth–Belief–Intent model results in systems that are easier to reason about, recover, and evolve.
1. The Problem: Confused Responsibility in Modern Systems
Distributed systems fail not because of lack of technology, but because of misplaced authority.
Common failure patterns include:
Treating cached data as authoritative
Treating emitted events as completed outcomes
Treating model outputs or projections as facts
Binding irreversible decisions to non-durable systems
These failures manifest as:
Inconsistent user state
Phantom payments
Data corruption under retries
Irrecoverable operational ambiguity
The root cause is almost always the same:
Truth, belief, and intent are mixed in the same layer.
2. Diving in..
🗄️ Databases store truth
What “truth” means (technically)
A database is the system of record.
It owns durable, authoritative state
It survives restarts, crashes, deployments
It’s where invariants are enforced
Examples of truth
User balance = ₹12,450
Order #8472 is
PAIDSubscription expires on
2026-03-01
If the DB says it didn’t happen → it didn’t happen
Why this holds
ACID guarantees (or controlled eventual consistency)
Write-ahead logs, replication, backups
Clear ownership of data
Architectural implication
Anything that matters legally, financially, or semantically must end up in the database.
If your system can’t reconstruct reality from the DB alone → you don’t have truth.
⚡Caches store lies that expire
Why caches are lies
Caches are:
Derived
Stale by definition
Not authoritative
A cache says:
“This was true recently enough that we’re willing to believe it.”
Common lies caches tell
User profile that’s 2 minutes old
Feature flag before rollout propagation
Inventory count that might be wrong
And that’s okay.
Why expiration matters
TTL is not a performance hack — it’s a truth repair mechanism.
Without expiry → lies live forever
With expiry → lies self-destruct
Architectural implication
Never make irreversible decisions based only on cache.
Good pattern:
Cache → fast read
DB → final authorityBad pattern:
Cache → payment decision → irreversible damage 📬 Queues store intentions
What “intentions” means
A queue does not mean something happened.
It means:
“Someone intends for this to happen.”
Examples:
“Send welcome email”
“Charge the card”
“Generate invoice”
“Rebuild search index”
The queue says nothing about:
Whether it already happened
Whether it will succeed
Whether it will happen once or twice
Why queues exist
Because time, failure, and scale exist.
Queues decouple:
Request from execution
Speed from reliability
Success from acknowledgement
Architectural implication
Queue messages must be idempotent and replayable.
If replaying a queue message breaks your system → design flaw.
3. The Core Principle
A correct distributed system must strictly separate truth, belief, and intent.
Violations of this principle create systems that appear to work under normal conditions but fail catastrophically under retries, scale, or partial outages.
4. Architectural Applications
4.1 🧩 Traditional SaaS Systems
How this maps to real SaaS architecture
Example: “User upgrades plan”
Correct flow
API receives request
DB: Transaction updates subscription → truth
Queue: “Provision premium features” → intention
Cache: Subscription status refreshed → temporary lie
If step 4 fails → system still correct
If step 3 retries → system still correct
If cache is wrong → DB still wins
🔥 Where people get this wrong
❌ Treating cache as truth
Feature flags only in Valkey/Redis
Auth state only in cache
Rate limits without DB fallback
Result: ghost bugs
❌ Treating queues as facts
Assuming “message sent” = “email delivered”
Assuming “event emitted” = “state changed”
Result: phantom consistency
❌ Letting DB absorb everything
Synchronous email sending
Long-running jobs in transactions
Blocking workflows
Result: slow, fragile systems
DBs answer “what is true?”
Caches answer “what’s probably true?”
Queues answer “what should happen next?”
This rule:
Aligns with distributed systems theory
Survives failure scenarios
Encourages idempotency, retries, and resilience
Prevents subtle production disasters
It’s not just a saying — it’s a design compass 🧭
4.2 🧾Event Sourcing — “Truth is a log, not a table”
How the rule maps
| Golden Rule | Event Sourcing Interpretation |
| ----------------------- | ----------------------------- |
| Databases store truth | Event log is the truth. |
| Caches store lies | Read models / projections |
| Queues store intentions | Commands → events |Key shift
In event sourcing:
State is derived
Events are immutable truth
Example:
UserRegistered
PlanUpgraded
PaymentFailed
PlanDowngradedThose events are reality.
Everything else:
Current plan
Account status
UI state
…are cached interpretations.
Why the rule still holds
Projections can be stale → lies
Events are append-only → truth
Commands represent intent (“please do X”)
If you lose projections but keep the event log → you can rebuild reality
If you lose the event log → history is gone forever
📌 Architect lesson
Event sourcing is just “DB as ultimate truth” taken to its logical extreme.
4.3 🔀 CQRS — “Separate knowing from doing”
CQRS is basically this rule formalized.
Command side (write path)
Validates intent
Enforces invariants
Writes truth
Query side (read path)
Optimized for speed
Often cached
Eventually consistent
| Component | Role |
| ----------- | ------------- |
| Write DB | Truth |
| Read models | Cached belief |
| Command bus | Intent |Why CQRS exists
Because truth is expensive and belief is cheap.
You don’t need:
Strong consistency
Transactions
Locks
…to answer most reads.
But you absolutely do for writes.
📌 Architect lesson
CQRS is the explicit admission that reads and writes live under different laws of physics.
4.4 🧠 RAG pipeline through the Rule
Truth
Source documents
Grounded datasets
Versioned corpora
Human-verified content
Usually stored in:
Object storage
Databases
Data lakes
Belief (Caches)
Embeddings
Vector indexes
Prompt caches
Retrieved chunks
These are:
Approximate
Heuristic
Time-sensitive
Two identical questions can retrieve different chunks tomorrow.
That’s fine.
They are belief systems, not facts.
Intent (Queues)
Inference jobs
Embedding refresh
Fine-tuning tasks
Re-ranking pipelines
A queue message means:
“We intend to compute intelligence.”
Not:
“The answer exists.”
Retries, failures, duplicates are expected.
Why hallucinations happen (architecturally)
Because people treat:
Vector DBs as truth
Cached prompts as facts
Model output as state
That violates the rule.
📌 Architect lesson
LLMs must never be a system of record.
They are reasoning engines over belief, grounded by truth.
4.5 Indian LLM Ecosystem — grounded, local, sovereign
🇮🇳 Context-specific truth
Government data
Legal texts
Regional language corpora
Cultural / historical records
These must live in:
Auditable storage
Versioned datasets
Human-curated pipelines
Because:
Cultural nuance ≠ statistical average
Legal interpretation ≠ probability
Truth must be traceable.
Belief layer (safe to approximate)
Regional embeddings
Dialect-normalized text
Cached translations
Summarized interpretations
These will be wrong sometimes.
That’s acceptable only because they expire.
Intent layer
Training jobs
Evaluation pipelines
Public inference endpoints
Model governance workflows
Queues here represent:
“We intend to generate knowledge responsibly.”
Not guarantees.
📌 Strategic lesson
If India builds LLM infra without respecting:
Truth ownership
Belief expiration
Intent replayability
…it will inherit opaque, un-auditable AI systems.
🔁 One diagram to rule them all
┌──────────────┐
│ DATABASE │
│ (TRUTH) │
└──────┬───────┘
│
┌──────▼───────┐
│ CACHE │
│ (BELIEF) │
└──────┬───────┘
│
┌──────▼───────┐
│ QUEUE │
│ (INTENT) │
└──────────────┘5. Failure Modes When the Principle Is Violated
| Violation | Result |
|----------------------------- |---------------------------|
| Cache treated as truth | Silent data corruption |
| Queue treated as fact | Duplicate side effects |
| Belief made durable | Stale reality |
| Intent made synchronous | Fragile systems |
| Truth coupled to performance | Unscalable architectures |These failures are often intermittent, making them difficult to debug and expensive to fix.
When systems fail catastrophically, it is rarely due to scale alone.
Almost always, failure emerges from confusing truth, belief, and intent.
Below are the canonical failure modes that appear when this principle is violated.
⚡ Failure Mode 1: Treating Cache as Truth
What goes wrong
Critical decisions are made based solely on cached data
Cache eviction, replication lag, or partial invalidation introduces silent corruption
Common symptoms
Users see “impossible” states
Feature flags behave inconsistently
Authorization or billing errors appear non-deterministic
Typical examples
Auth/session state stored only in Redis
Feature entitlements cached without DB verification
Rate limits enforced purely in cache
Root cause
Cache is optimized for speed, not authority.
Blast radius
High — because caches fail silently and fast.
📬 Failure Mode 2: Assuming Queues Represent Facts
What goes wrong
Systems assume “message sent” means “action completed”
Retries and duplicates cause side effects to multiply
Common symptoms
Double emails
Duplicate charges
Inconsistent downstream state
Typical examples
Charging a card inside a queue consumer without idempotency
Emitting events without transactional boundaries
Assuming exactly-once semantics without enforcement
Root cause
A queue expresses intent, not completion.
Blast radius
Medium to High — grows with retries and partial failures.
🧾 Failure Mode 3: Allowing Databases to Absorb Asynchrony
What goes wrong
Long-running operations executed inside DB transactions
External calls block commits
Database becomes a bottleneck or deadlock hotspot
Common symptoms
Slow queries under load
Cascading timeouts
Lock contention and deadlocks
Typical examples
Sending emails inside transactions
Synchronous ML inference during writes
Calling third-party APIs before commit
Root cause
Databases are optimized for consistency, not orchestration.
Blast radius
High — failures propagate system-wide.
🔄 Failure Mode 4: Blurring Read and Write Responsibilities
What goes wrong
Read paths assume strong consistency
Write paths optimized for read performance
Systems collapse under mixed workloads
Common symptoms
High tail latency
Overloaded primary databases
Unpredictable performance degradation
Typical examples
Using the same data model for OLTP and analytics
Strong consistency for all reads
No read replicas or projections
Root cause
Reads want speed; writes want correctness.
Blast radius
Medium — but chronic and expensive.
🤖 Failure Mode 5: Treating AI Output as State
What goes wrong
LLM responses stored or reused as authoritative answers
No grounding or re-validation against source truth
Common symptoms
Hallucinated facts persist
Models contradict earlier outputs
Inability to audit decisions
Typical examples
Saving LLM answers as records
Using vector DBs as systems of record
No linkage back to source documents
Root cause
Models reason over belief, not truth.
Blast radius
High — especially in regulated or cultural contexts.
| Layer | Proper Role | When Violated |
| -------- | ---------------- | ----------------------- |
| Database | Defines reality | Truth becomes ambiguous |
| Cache | Optimizes belief | Lies persist |
| Queue | Expresses intent | Actions multiply |
📌 Rule of Thumb
If a system cannot reconstruct reality from its database alone,
it does not have a reliable definition of truth.
Every failure above collapses into one mistake:
Confusing authority, approximation, and intent.
6. Industry metrics
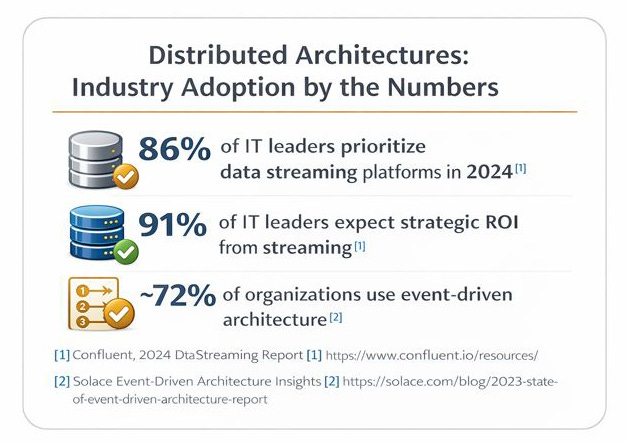
🔁 Key metrics
📈 Investment in data streaming — 86%
“86% of IT leaders are prioritising investments in data-streaming platforms in 2024 — underscoring that streaming (queues/events) has become a strategic backbone for modern architectures.”
Why it matters: supports your point that queues/streams are now core infrastructure, not optional plumbing.
🎯 Data-streaming ROI belief — 91%
“91% of surveyed IT leaders say they’re counting on data-streaming platforms to drive their data goals and business agility.”
Why it matters: reinforces the previous stat with an ROI/priority angle — good for arguing that intent (queues) delivers measurable business outcomes.
⚙️ Event-driven adoption — ~72%
“Event-driven architecture is in widespread use across organisations: roughly 72% report some adoption of event-driven approaches.”
Why it matters: gives a command-level stat to justify recommending event/stream patterns in your architecture guidance.
🗄️ Caching effectiveness (origin load / miss-rate) — up to 60% miss-rate reduction
“Operator experience shows techniques like tiered CDN caching can reduce cache miss-rates by 60% or more — directly cutting origin load and latency.”
Why it matters: concrete proof you can use to defend “caches are performance, not truth” — show real operational savings.
🔁 Redis / cache ubiquity — large share among developers (~mid-to-high-20s%)
“In developer surveys Redis consistently ranks among the top used in-memory/key-value systems (used by roughly a quarter to a third of respondents in recent surveys), reflecting its central role as a caching and fast-state layer.”
Why it matters: backs the “caches everywhere” claim with adoption figures (good for arguing patterns like optimistic UI, feature flags, short-lived session state).
“Modern systems treat databases as the system of record, caches as transient performance optimizers, and queues/streams as the reliable expression of intent — a posture vindicated by industry adoption: 86% of IT leaders prioritise data streaming, 91% expect strategic ROI from it, and mature caching strategies can halve cache miss pressure on origin systems.” - Confluent
7. Design Implications

7.1 For Architects
Identify exactly one source of truth per domain
Make all other representations explicitly disposable
Design all side effects to be idempotent
7.2 For Engineers
Never trust cache without fallback
Never assume message delivery implies execution
Never persist derived state without provenance
7.3 For AI System Designers
Ground all outputs in auditable truth
Version datasets and prompts
Treat inference as probabilistic belief, not fact
🗄️ Authority must be singular
⚡ Approximation must be disposable
📬 Intent must be replayable
⚠️ Quick caveats
Metrics are contextual (industry, org size, workloads) — cite the source next to any quoted stat.
Cache hit-rate benefits depend heavily on access patterns and cache design; blindly maximizing hit ratio can sometimes harm throughput — measure for your workload.
Event-driven adoption maturity varies: many orgs use events, far fewer have fully mature, org-wide EDA practices.
Sources
Confluent — 2024 Data Streaming Report (86% prioritising streaming; 91% ROI/benefits). Confluent
Solace / industry survey — Event-driven adoption statistics (≈72% adoption figure / maturity notes). Solace
Cloudflare blog — Tiered cache / Orpheus: “60%+ reduction in cache miss rate” (operator stat). Cloudflare blog
StackOverflow / industry signals & commentary on Redis usage (developer survey signals, Redis adoption among engineers). Stack overflow
Redis engineering blog / cache strategy warnings (why hit-ratio alone can be misleading). Redis
Hey, great read as always, it’s realy insightful how you frame the confusion in distributed systems, though I wonder how straightforwardly this ideal separation of truth, belief, and intent always translates to the messy reality of production.
I would say, I’m learning. Here is the extended version of “Truth-Belief-Intent” Model. More details follow 🔜 https://substack.com/@jagadeeshrampam/note/c-216525280