Grounding Is Not a Prompt
Why Retrieval-Augmented Fine-Tuning matters more than instruction-tuned RAG for rooted LLMs

Source: How Well Do Large Language Models Truly Ground?
To reduce issues like hallucinations and lack of control in Large Language Models (LLMs), a common method is to generate responses by grounding on external contexts given as input, known as knowledge-augmented models. However, previous research often narrowly defines “grounding” as just having the correct answer, which does not ensure the reliability of the entire response. To overcome this, we propose a stricter definition of grounding: a model is truly grounded if it (1) fully utilizes the necessary knowledge from the provided context, and (2) stays within the limits of that knowledge. We introduce a new dataset and a grounding metric to evaluate model capability under the definition. We perform experiments across 25 LLMs of different sizes and training methods and provide insights into factors that influence grounding performance. Our findings contribute to a better understanding of how to improve grounding capabilities and suggest an area of improvement toward more reliable and controllable LLM applications.
Grounding provides the following benefits:
Reduces model hallucinations, which are instances where the model generates content that isn’t factual.
Anchors model responses to your data sources.
Provides auditability by providing grounding support, which are links to sources.
Prompting provides behavioural steering at inference time, retrieval augments generation via late-bound external context, and grounding operates at the system and model level by constraining knowledge through training signals, memory, retrieval semantics, and update paths. Unlike prompting or retrieval, grounding establishes persistent epistemic boundaries, shaping what the model can justifiably assert across interactions.
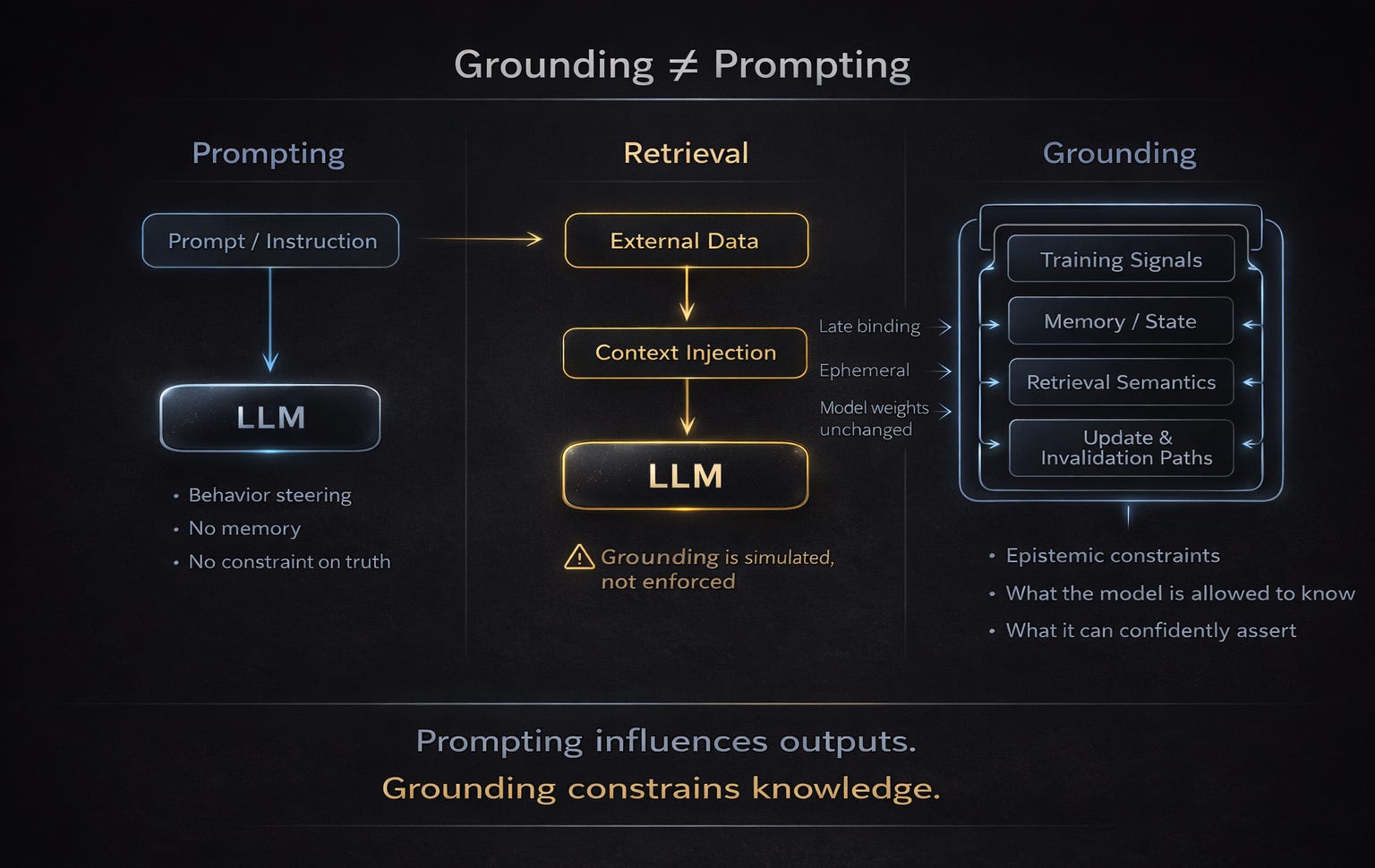
This distinction reframes retrieval not as a grounding mechanism by itself, but as one possible substrate—raising the question of whether grounding can be achieved purely at inference time (RAG), or whether it must be embedded into the training and alignment process itself (RAFT).
RAFT vs Instruction-Tuned RAG (Why the distinction matters)
At first glance, instruction-tuned RAG and RAFT can look similar.
Both use retrieved documents, present those documents to the model, and ask for grounded answers.
But the similarity is superficial.
The difference lies in what the training objective teaches the model to rely on when generating responses.
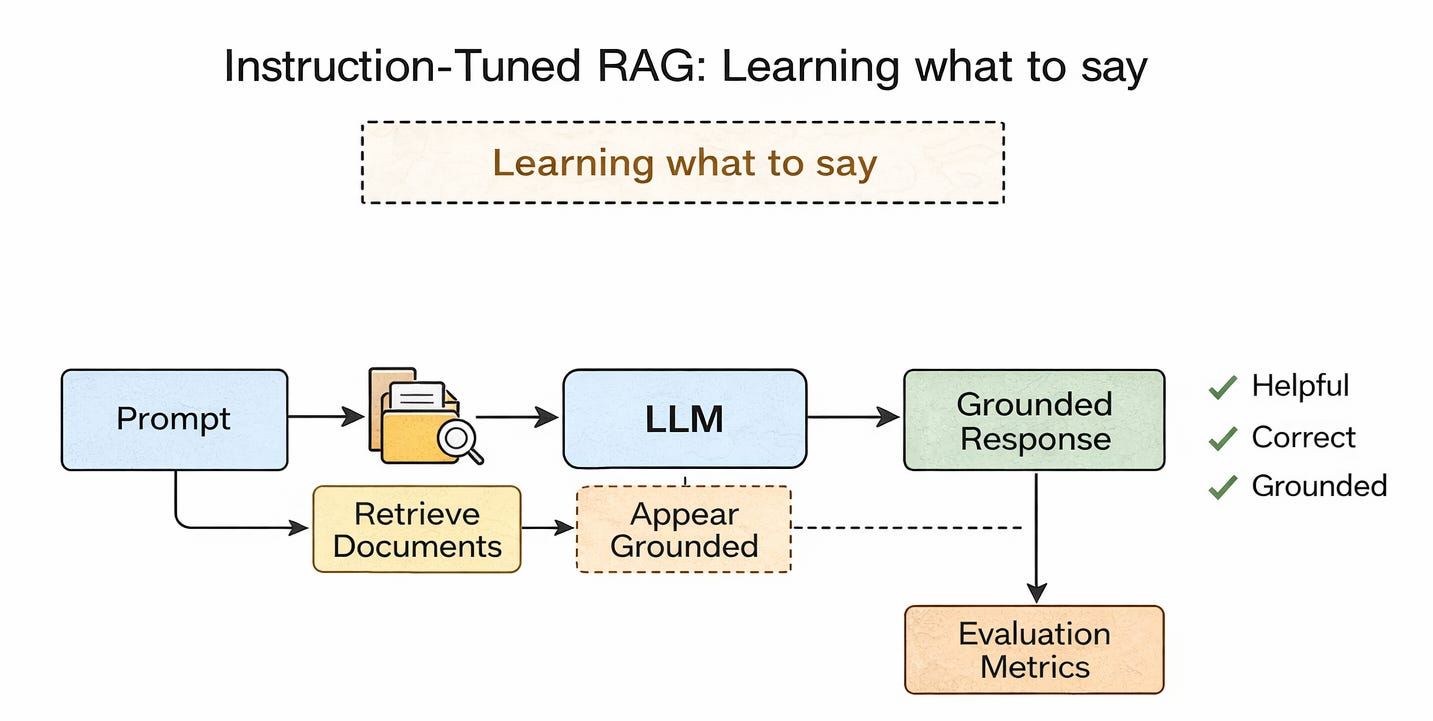
Instruction-Tuned RAG: Learning what to say
Instruction-tuned RAG fine-tunes a model on prompts like:
“Given the following documents, answer the question.”
The training objective focuses on:
following instructions,
producing a helpful response,
sounding grounded.
What the model actually learns:
how to format answers when context is present,
how to appear aligned with sources,
how to satisfy instruction-following metrics.
Crucially:
retrieval is treated as optional context,
the model is not penalised strongly for ignoring parts of it,
hallucination is reduced, but not structurally discouraged.
In practice, instruction-tuned RAG improves obedience, not epistemology.
The model still “believes” its internal knowledge first.
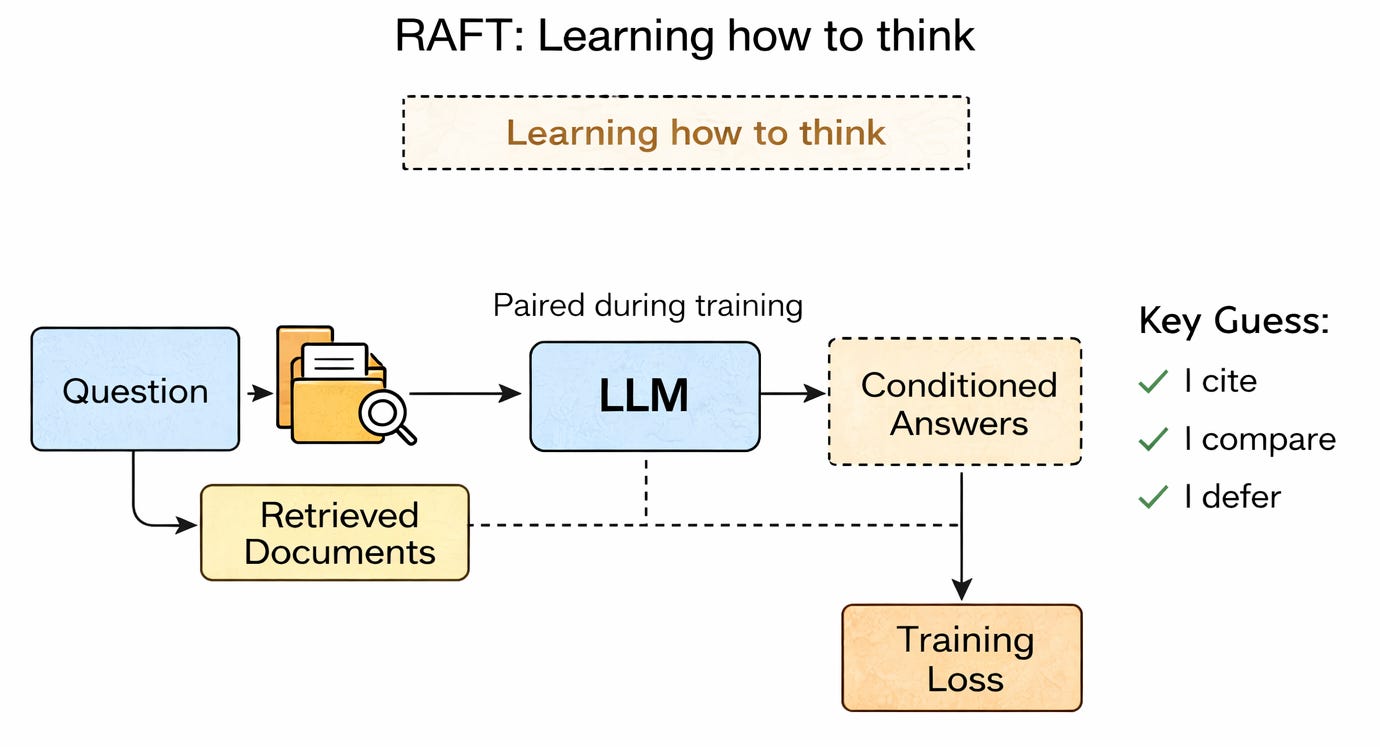
RAFT: Learning how to think
RAFT changes the learning signal.
Instead of teaching the model:
“Answer using these documents.”
RAFT teaches:
“Your answer exists only because these documents exist.”
During RAFT training:
retrieved documents are integral to the task,
answers are evaluated for faithfulness to sources, not just correctness,
loss functions explicitly penalise unsupported generation.
The model learns behaviours like:
deferring when sources are insufficient,
reconciling conflicting texts,
synthesising rather than paraphrasing,
maintaining uncertainty where traditions differ.
Retrieval is no longer a side input. It becomes the structure that supports reasoning.
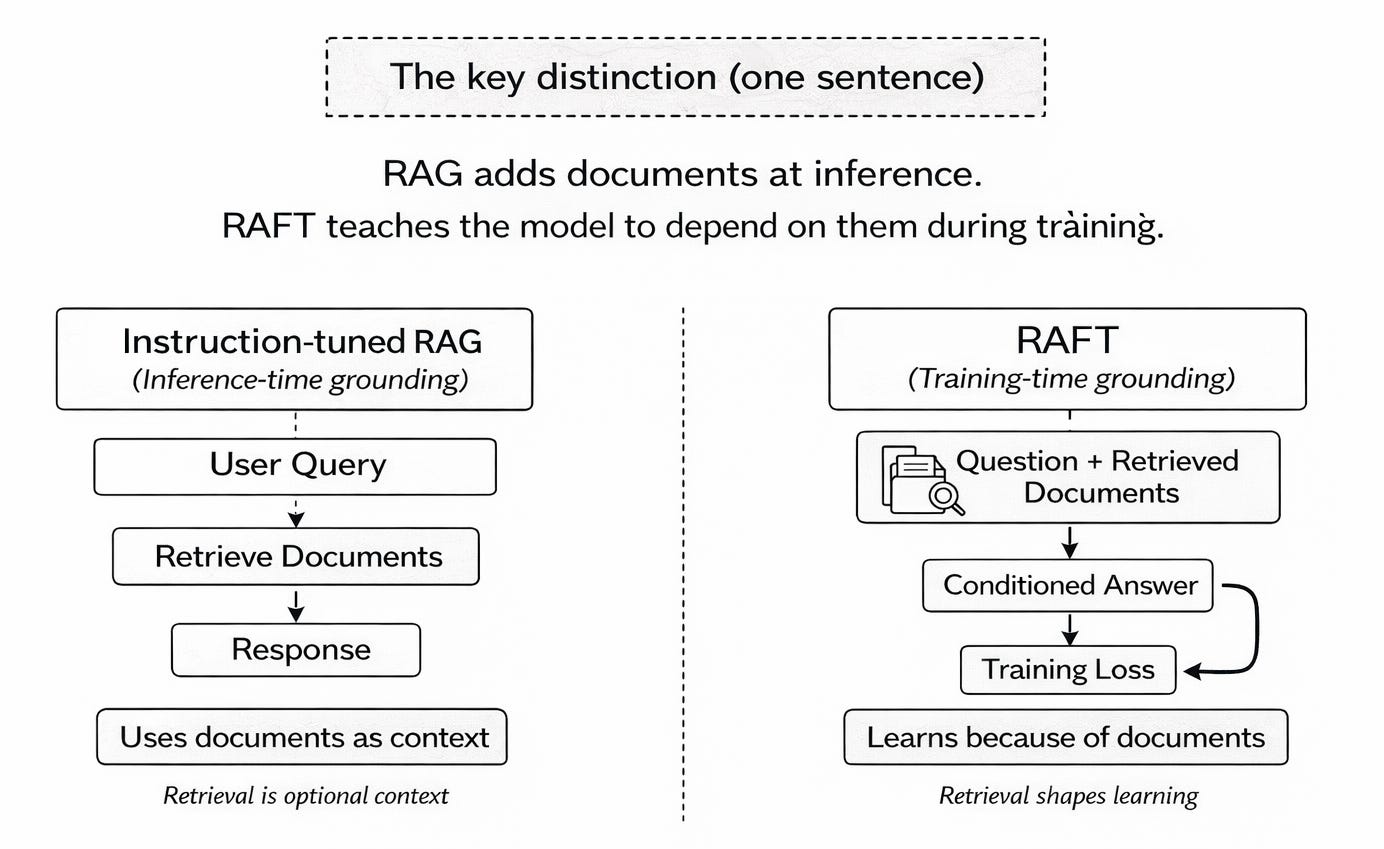
The key distinction
Instruction-tuned RAG teaches the model to talk nicely around documents
RAFT teaches the model to reason because of documents
Why this distinction matters for rooted LLMs
In culturally dense domains (Indian epics, philosophy, ecology):
There is rarely a single “correct” answer.
Authority comes from lineage, source, and context, not confidence.
Silence or qualification is often more correct than completion.
Instruction-tuned RAG tends to:
smooth over differences,
converge to dominant narratives,
and speak with unwarranted certainty.
RAFT allows models to:
preserve plurality,
surface disagreement,
and remain grounded without flattening culture.
RAFT over RAG
Retrieval-Augmented Generation (RAG) has become the default answer to grounding large language models. And for many problems, it works well.
But RAG is an inference-time patch, not a learning strategy.
It assumes the model is already capable of:
respecting retrieved text,
resolving conflicts between sources,
and resisting hallucination when knowledge is incomplete.
In culturally dense domains—like Indian languages, epics, ecology, or philosophy—this assumption breaks down. ❌
The limitation of RAG
RAG introduces retrieval after the model has already learned how to speak.
The model:
retrieves documents,
receives them as context,
and is asked (not trained) to ground its response.
As a result:
retrieval is often ignored or weakly used,
stylistic priors dominate over source intent,
and conflicting traditions are collapsed into a single voice.
RAG helps the model look things up.
It does not teach the model how to reason with sources.
RAFT changes where grounding happens
Retrieval-Augmented Fine-Tuning (RAFT) moves retrieval from inference into training itself.
Instead of asking:
“Can the model answer better if we show it documents?”
RAFT asks:
“Can the model learn how to answer by depending on documents?”
During RAFT training:
questions are paired with retrieved texts,
answers are explicitly conditioned on those texts,
and the loss function rewards faithful synthesis, not confident completion.
Over time, the model internalises behaviours that RAG only hopes for:
citing instead of guessing,
comparing instead of collapsing,
deferring instead of hallucinating.
Why this matters for Indian LLMs
Indian knowledge systems are not neatly structured databases.
They are:
multi-lingual,
multi-traditional,
and often intentionally non-canonical.
A single question may have:
multiple valid answers,
region-specific interpretations,
or textual disagreements across centuries.
RAG treats this as noise at inference time.
RAFT treats it as signal during learning.
This makes RAFT especially suited for:
epics with parallel tellings,
oral + written traditions,
ecological knowledge embedded in practice,
and philosophy where tone and restraint matter as much as facts.
A simple way to think about it
RAG:
“Here are some documents. Please use them.”RAFT:
“This is how you are expected to think when documents exist.”
One is additive.
The other is formative.
Smriti’s position
Smriti uses RAFT not to make models larger or louder, but more grounded.
The goal is not recall at scale.
It is memory with context.
In this framing:
retrieval carries plurality,
fine-tuning shapes judgment,
and the model learns when not to answer.
That is why RAFT is not an optimization choice for Smriti.
It is a foundational one.
Smriti’s stance
Smriti treats grounding not as a UX feature, but as a training principle.
Instruction-tuned RAG asks:
“Can we guide the model better?”
RAFT asks:
“What kind of model should this be?”
For rooted LLMs, that difference is foundational.
Smriti — RAFT for Rooted LLMs
Modern language models are powerful, but they are not neutral.
They inherit what they see, what they read, and—more importantly—what they miss.

For regions like India, this gap is structural.
Languages, epics, ecological knowledge, oral traditions, inscriptions, commentaries, and living culture are either underrepresented, flattened, or treated as folklore rather than first-class knowledge systems. Scaling models alone does not fix this. Memorization does not fix this. Prompting does not fix this.
What is required is grounding. Smriti is an exploration of that idea.
At its core, Smriti uses Retrieval-Augmented Fine-Tuning (RAFT) as a way to teach models how to remember, not just what to answer. Instead of treating retrieval as an external crutch at inference time, RAFT integrates retrieval directly into training—so the model learns to reason with sources, compare traditions, and stay anchored to text.
This matters deeply in the Indian context:
where knowledge exists across multiple versions, not a single canonical source
where oral and written traditions coexist
where puranas, history, ecology, and philosophy are intertwined
where “culture” is not content, but context
Smriti does not aim to compress this complexity into weights.
It aims to respect it, by letting retrieval carry plurality and letting fine-tuning shape tone, restraint, and synthesis.
This work is being developed as part of Phagyul AI Systems, where we are experimenting with infrastructure, data pipelines, and training strategies for culturally grounded, region-first language models.
Details on datasets, architecture choices, and evaluation will be shared incrementally—once they are ready to stand on their own.
For now, Smriti is a name for a direction:
Memory over memorization.
Grounding over generation.
Rooted intelligence over borrowed scale.
More soon..
Smriti is an ongoing research and systems effort within Phagyul AI Systems, exploring retrieval-augmented training methods for regionally grounded LLMs.