Terraform at Scale: What Actually Worked, What Didn’t, and the Cost of Trusting AI with Infrastructure
A Parjanya v2.0 field note from migrating a real platform across AWS accounts, repositories, and automation layers

When people talk about Terraform, they often talk about Infrastructure as Code.
What I learned while building Parjanya v2.0 is that Terraform is really about something else:
forcing operational discipline.
Terraform didn’t magically simplify our infrastructure. It exposed assumptions, surfaced hidden dependencies, and forced us to formalize decisions we had previously gotten away with making informally.
As Parjanya evolved from a collection of scripts, console clicks, and one-off configurations into a multi-tenant image processing platform, Terraform became the backbone that allowed us to scale infrastructure without losing control.
It also introduced new challenges.
And when I layered AI-assisted engineering into the workflow, I discovered an entirely different category of problems worth documenting.
This post is the implementation companion to my previous article on why we chose a three-account AWS architecture for Parjanya v2.0.
That post explained the boundaries.
This one explains how we turned those boundaries into code.
The Reality of Operating Across Five Repositories
Parjanya today spans five repositories.
Each exists for a reason.
parjanya-ml handles inference and model serving.
parjanya-ops owns infrastructure and platform operations.
parjanya-backend manages orchestration and APIs.
parjanya-frontend serves tenant-facing experiences.
parjanya-shared-libraries contains contracts and shared abstractions.
The separation works well organizationally.
Parjanya’s Polyrepo Architecture: Building Scalable AI/LLM Products with Organizational Autonomy (Part 1)

After shipping Parjanya v1.0 through v1.3 (with 17+ patch releases), we’ve evolved from monolithic friction to a deliberate five-repository polyrepo architecture aligned with team structure and technical boundaries. This post documents our research-driven thought process, the specific tech stack (Nx frontend, FastAPI microservices, PyTorch + MIT-license…
ML engineers don’t need to understand IAM condition keys.
Infrastructure engineers don’t need to navigate PyTorch dependencies.
Backend engineers don’t need to modify Terraform every time they ship a feature.
But Terraform exposed a challenge that few people talk about:
cross-repository infrastructure dependencies.
The moment one repository depends on infrastructure outputs defined in another, coordination becomes critical.
A renamed Terraform output in one repository can quietly break another repository that references it through remote state.
I’ve been bitten by this more than once.
Terraform didn’t prevent those mistakes.
What it did provide was visibility.
And visibility is often the difference between a recoverable issue and a production incident.
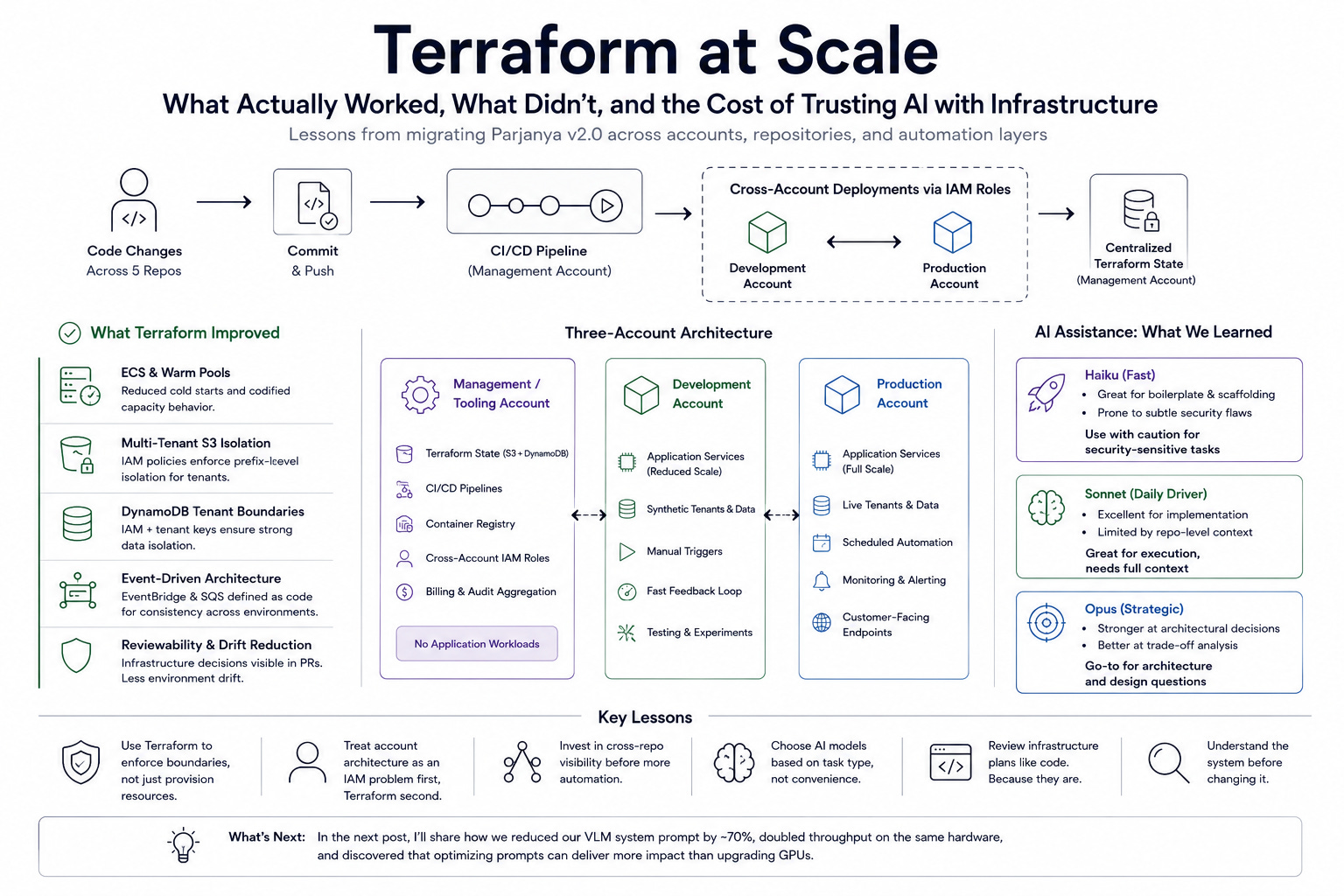
What Terraform Actually Improved
A lot of Terraform discussions stay theoretical.
Here’s what it changed in practice for us.
ECS and Warm Pools
One of the first problems we tackled was cold-start latency.
Inference workloads running on ECS-backed EC2 instances would occasionally wait several minutes for capacity to become available.
To solve this, we implemented Auto Scaling Group warm pools.
The result wasn’t just faster startup times.
It gave us a repeatable way to define capacity behavior for different tenant tiers.
Instead of manually tuning infrastructure across environments, we could express those decisions through variables and deploy them consistently.
That may sound mundane.
But consistency becomes incredibly valuable once multiple environments, tenants, and deployment pipelines are involved.
Multi-Tenant S3 Isolation
Parjanya is a multi-tenant platform.
Tenant isolation isn’t optional.
Terraform allowed us to codify S3 prefix-level isolation directly into IAM policies.
The most important outcome wasn’t the policy itself.
It was the reviewability.
A missing condition that could have exposed tenant object metadata became visible during code review instead of after deployment.
That’s one of Terraform’s underrated strengths:
It turns invisible infrastructure assumptions into visible diffs.
DynamoDB Tenant Boundaries
The same pattern applied to DynamoDB.
Every tenant’s data is partitioned using tenant identifiers, with IAM enforcing access boundaries.
Could application code enforce those rules?
Yes.
Should application code be the only layer enforcing them?
Absolutely not.
Terraform helped us move those guarantees into infrastructure itself.
Even if application logic fails, IAM remains the final gatekeeper.
Event-Driven Infrastructure
Parjanya’s processing pipeline relies heavily on EventBridge and SQS.
Before Terraform, environment drift was a recurring problem.
A queue configuration changed in Production but not Development.
An EventBridge rule existed in one environment but not another.
Over time these differences accumulate.
Terraform gave us repeatability.
The same modules, deployed consistently, dramatically reduced configuration divergence.
The Three-Account Migration
The biggest Terraform project in Parjanya v2.0 wasn’t a service deployment.
It was infrastructure reorganization.
Why We Use Three AWS Accounts (Not Two) for Parjanya v2.0

When you’re building a startup, the default path is obvious:
We migrated from a single AWS account into:
Management / Tooling
Development
Production
Terraform made that migration possible.
It did not make it easy.
Making State Account-Aware
Our original infrastructure assumed everything lived in one account.
Provider configurations were implicit.
Cross-account roles didn’t exist.
Account boundaries didn’t exist.
The first step was making account ownership explicit.
That sounds simple until you realize every Terraform resource suddenly needs to know which AWS account it belongs to.
The work wasn’t intellectually difficult.
It was painstaking.
And this is where I learned an important lesson about AI-assisted engineering:
AI is surprisingly bad at repetitive infrastructure migrations unless it has complete context.
Migrating State Safely
One of the most valuable Terraform commands I encountered during this process was:
terraform state mv
State migration sounds boring.
Until you realize a single mistake can cause Terraform to believe a production resource should be destroyed and recreated.
The migration process became an exercise in discipline:
Move state.
Run a plan.
Review carefully.
Repeat.
Slowly.
The temptation to batch changes is enormous.
Resisting that temptation saved us multiple times.
Cross-Account IAM
The three-account architecture introduced a new category of complexity.
Trust relationships.
The Management account hosts shared tooling.
Development and Production need access to those resources.
Terraform became the mechanism for expressing those trust boundaries consistently.
What surprised me wasn’t the complexity of the IAM policies.
It was how much architectural thinking is required before writing any Terraform.
The tooling faithfully implements your design.
It does not validate whether the design itself is sensible.
Centralized State Management
One decision I remain happy with is keeping Terraform state centralized within the Management account.
Development engineers can operate Development.
Production operators can manage Production.
But neither automatically gains access to every state file.
This separation aligns with the overall philosophy behind the architecture:
Boundaries first.
Convenience second.
Where AI Helped — And Where It Didn’t
Throughout this migration I relied heavily on AI-assisted development.
Claude became part of the workflow.
Over time I learned that different models excel at very different tasks.
The results were revealing.
Sonnet 4.6 Became My New Benchmark for Building an Infra-Heavy VLM Platform

A few months ago, I wrote about why I believed in a Haiku-first strategy: start with the cheapest and fastest model possible, then escalate only when the task genuinely becomes harder. That idea still makes sense in principle.
Haiku: Fast But Dangerous for Infrastructure
Haiku was excellent at generating boilerplate.
Variable files.
Module outputs.
Simple scaffolding.
But infrastructure isn’t just syntax.
Infrastructure is reasoning.
I repeatedly found that Haiku could generate valid Terraform that contained subtle security flaws.
The code looked correct.
The logic wasn’t.
That distinction matters.
A lot.
My conclusion became simple:
Haiku should never be trusted with security-sensitive infrastructure decisions.
Sonnet: The Daily Driver
Most of our Terraform work happened with Sonnet.
For implementation tasks inside a repository, it performed extremely well.
Module structures.
Provider configurations.
Refactors.
General Terraform development.
Where it struggled was context.
A repository rename might affect multiple repositories.
A queue change might impact systems it couldn’t see.
The problem wasn’t model intelligence.
The problem was visibility.
The model can only reason about what you show it.
Opus: Better at Architecture Than Implementation
I brought Opus into the process whenever decisions became architectural.
Questions like:
Should this responsibility live in Management or Production?
How should artifacts flow between accounts?
What’s the cleanest trust model?
These are trade-off questions.
Opus consistently handled them better than implementation-focused tasks.
The irony was that the more strategic the question became, the more useful the model became.
The Biggest Problem Wasn’t Terraform
It Was Context.
This became one of the clearest lessons from Parjanya v2.0.
The hardest infrastructure problems weren’t provider bugs.
They weren’t Terraform limitations.
They weren’t AWS limitations.
They were context problems.
Infrastructure lived in one repository.
ML workloads lived in another.
Shared interfaces lived somewhere else.
Every repository understood part of the system.
No repository understood the entire system.
That’s why we started building supporting tooling and internal agents focused on context discovery and verification.
The challenge wasn’t generating code.
The challenge was understanding the system before generating code.
What Terraform Didn’t Solve
It’s important to be honest about this.
Terraform isn’t a cure-all.
We still accumulated module sprawl.
We still dealt with drift.
We still had to manage secrets separately.
We still needed human judgment when reviewing large infrastructure changes.
Terraform gave us control.
It did not eliminate responsibility.
The Practical Lessons
If I were starting again today, these are the lessons I’d carry forward.
Use Terraform to enforce boundaries, not just provision resources.
Treat account architecture as an IAM problem first and a Terraform problem second.
Invest in cross-repository visibility before investing in more automation.
Choose AI models based on task type, not convenience.
Review infrastructure plans like code. Because they are.
Prioritize understanding the system before changing it.
Most infrastructure failures aren’t caused by bad tooling.
They’re caused by incomplete context.
Looking Ahead
The three-account architecture gave us the boundaries.
Terraform gave us the implementation.
But neither addressed another challenge that emerged as Parjanya’s inference workloads grew:
Cost.
Specifically, inference cost.
While we were optimizing infrastructure, another inefficiency was hiding in plain sight.
Our VLM system prompt had quietly grown to over 4,000 tokens.
Most of it wasn’t doing useful work.
Tomorrow’s post moves from infrastructure into inference engineering.
I’ll share how we reduced prompt size by nearly 70%, doubled throughput on the same hardware, and discovered that some of the most impactful optimizations don’t involve changing models at all.
Context Engineering and Context Debt

TL;DR: I noticed Haiku 4.5 being spawned as a subagent during an Opus 4.7 session. That observation opened a data investigation that revealed ~77% of my token spend was context accumulation waste, not productive reasoning. This is the framework I built to fix it — and the problem has a name:
The Takeaway
Terraform didn’t make Parjanya v2.0 successful.
What it did was force us to be explicit.
Explicit about ownership.
Explicit about trust boundaries.
Explicit about infrastructure decisions.
And perhaps most importantly, explicit about the assumptions we were making.
That’s the real value of Infrastructure as Code.
Not automation.
Clarity.
And clarity scales far better than heroics.
This is part of my ongoing Parjanya v2.0 field notes, documenting the architectural, operational, and engineering decisions behind building a multi-tenant AI platform. In the next post, I’ll move beyond infrastructure and into inference optimization—where a prompt review ended up delivering more value than a hardware upgrade.