Parjanya’s Polyrepo Architecture: Building Scalable AI/LLM Products with Organizational Autonomy (Part 1)
After shipping Parjanya v1.0 through v1.3 (with 17+ patch releases), we’ve evolved from monolithic friction to a deliberate five-repository polyrepo architecture aligned with team structure and technical boundaries. This post documents our research-driven thought process, the specific tech stack (Nx frontend, FastAPI microservices, PyTorch + MIT-licensed DepictQA + Smriti RAFT LLM), our 4-tier ML inference scaling strategy (Lambda → ECS Spot Instances), and storage architecture (S3 objects + DynamoDB metadata)—before sharing production learnings in Part 2.
From Monolith Pain to Polyrepo Clarity
Parjanya v1.0-1.3: The Breaking Point
Parjanya 1.0 shipped as a monorepo: frontend React app, FastAPI backend, PyTorch ML inference, Terraform infra, and database schemas all in one Git repository. This worked for our initial three-person team, enabling rapid iteration through v1.2. But v1.3’s patch releases exposed fatal flaws:
1. Release coordination hell: Frontend UI updates waited weeks for ML model retraining
2. Ownership diffusion: Database schema changes created “not my job” finger-pointing
3. Dependency bloat: PyTorch/CUDA dependencies slowed frontend developer onboarding by 40+ minutes
4. Deployment waste: Image quality assessment (IQA) hotfixes redeployed unchanged frontend assets
The final straw: a DepictQA IQA model update required coordinating frontend, backend, ML, and infra changes simultaneously. We needed a structure where teams could ship independently without chaos.
Research Findings: The Middle Path
Industry analysis revealed most discussions pit Google-style monorepos against fragmented polyrepos. But high-velocity teams (Spotify, Snyk, PayPal) use **intentional polyrepos**—bounded repositories aligned with Conway’s Law. For AI/LLM products with diverse cadences (frontend weekly → ML monthly → infra rarely), we needed **exactly five repositories**:
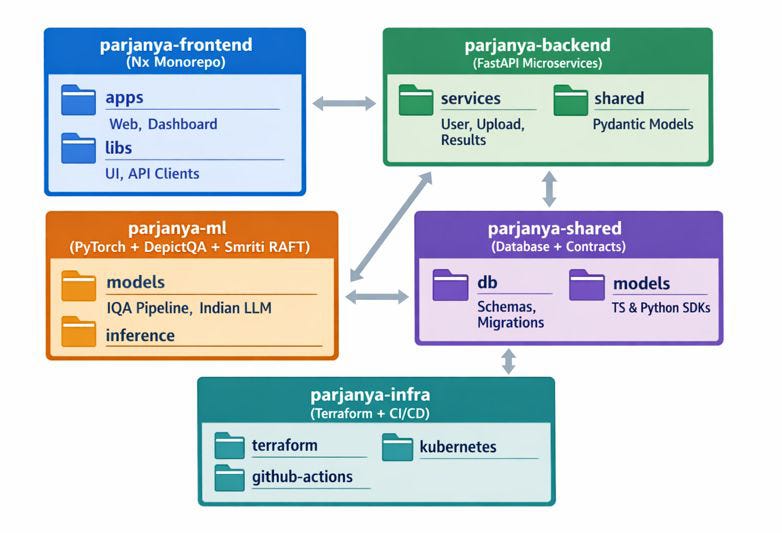
This isn’t “many repos.” It’s the **minimum viable separation** for team autonomy.
Tech Stack: Frontend → ML → Storage → Infra
1. Frontend: Nx Monorepo (Independent Apps, Shared Libs)
parjanya-frontend/
├── apps/
│ ├── web/ # React + TypeScript
│ ├── dashboard/ # Partner admin
│ └── sdk/ # Embedded JS SDK
├── libs/
│ ├── ui/ # Headless components
│ ├── api-clients/ # OpenAPI generated
│ └── features/ # Auth, upload flows
└── nx.json # Affected builds
Nx advantages:
- `nx affected` rebuilds only changed apps (frontend CI: 2min → 30s)
- Module Federation for independent deployments
- Type-safe API clients auto-generated from FastAPI OpenAPI specs
2. Backend: FastAPI Microservices
parjanya-backend/
├── services/
│ ├── api-gateway/ # Auth, routing
│ ├── user-service/ # Profiles, billing
│ ├── upload-service/ # S3 presigned URLs
│ └── result-service/ # Query results
└── shared/ # Pydantic models
Each service deploys independently via ECS. Async SQS decouples services—upload-service triggers ML inference without waiting.
3. ML Repository: Single Source of Truth for IQA + Smriti RAFT
Architectural Decision: All ML libraries (PyTorch, MIT-licensed DepictQA, Smriti RAFT LLM) live in one repository to enable ML team to manage development, training, and production deployment with specialized infrastructure.
Why single ML repo:
- Unified dependency management: PyTorch 2.1+, CUDA 12.1, DepictQA (MIT-licensed IQA), Smriti RAFT components
- Team ownership: ML engineers control complete stack without backend/frontend coordination
- Infra specialization: GPU Spot instances, ECS Fargate scaling separate from CPU workloads
- IQA pipeline consistency: DepictQA as **single source of truth** for image quality assessment
4-Tier Inference Scaling (object size + compute needs):

ML Repository Structure:
parjanya-ml/ # Single source of truth
├── models/
│ ├── depictqa/ # MIT-licensed IQA (single source of truth)
│ │ ├── model.pt # Pre-trained weights
│ │ ├── inference.py # Core IQA pipeline
│ │ └── metrics/ # Quality scoring logic
│ └── smriti/ # Indian heritage RAFT LLM
│ ├── raft/ # Retrieval-Augmented Fine-Tuning
│ ├── prompts/ # Sanskrit/cultural templates
│ └── embeddings/ # Knowledge graph vectors
├── tiers/
│ ├── tier1_lambda.py # Lightweight DepictQA
│ ├── tier2_lambda.py # Full DepictQA
│ ├── tier3_ecs.py # DepictQA + Smriti lite
│ └── tier4_gpu.py # Full RAFT pipeline
├── requirements.txt # PyTorch 2.1, DepictQA, transformers
└── Dockerfile.gpu # NVIDIA CUDA 12.1 + all ML deps
Routing Logic (upload-service → ML):
python
async def route_inference(image_size_mb: float, use_case: str):
if image_size_mb < 1:
return await tier1_lambda_depictqa(image_size_mb) # Quick check
elif image_size_mb < 50:
return await tier2_lambda_depictqa(image_size_mb) # Full IQA
elif image_size_mb < 500:
return await tier3_ecs_depictqa_smriti(image_size_mb)
else:
return await tier4_gpu_raft(image_size_mb) # Heritage-grade analysisCost breakdown (10K users/month):
Tier 1: 60% × $0.0000002 = $0.12 (DepictQA metadata)
Tier 2: 35% × $0.000002 = $1.40 (DepictQA IQA)
Tier 3: 4% × $0.10/task = $16.00 (DepictQA + Smriti)
Tier 4: 1% × $0.50/job = $50.00 (RAFT heritage analysis)
-------------------------------------------------------
Total ML inference: ~$67.52/month
Future flexibility: DepictQA may evolve to training/RAG/RAFT roles, but remains IQA single source of truth. Smriti RAFT components modularised for independent scaling.
4. Shared Libraries: The Contract Layer
parjanya-shared/
├── db/
│ ├── dynamodb/ # Metadata tables
│ │ ├── users.json
│ │ └── results.json # DepictQA scores + Smriti outputs
│ └── rds/ # Relational schemas
├── models/
│ ├── ts/ # npm: @parjanya/models
│ └── python/ # pip: parjanya-models
└── sdk/
├── api-client-ts/
└── api-client-py/
Version policy: `^1.2.0` allows patches/minors, blocks majors. Breaking changes → v2.0.0.
5. Infrastructure: ML-Optimized Deployments
parjanya-infra/
├── terraform/
│ ├── s3.tf # Object storage
│ ├── dynamodb.tf # Metadata (GSI: user_id+quality_score)
│ ├── lambda.tf # Tier 1+2 (DepictQA lightweight)
│ ├── ecs.tf # Tier 3 Fargate (DepictQA + Smriti)
│ ├── ec2.tf # Tier 4 Spot GPU (g4dn.xlarge RAFT)
│ └── iam.tf # ML service roles
├── github-actions/
│ ├── deploy-ml-tier1.yml
│ ├── deploy-ml-tier4.yml # GPU Spot orchestration
│ └── terraform-plan.yml
└── monitoring/
├── cloudwatch.tf # Tier-specific DepictQA/Smriti alarms
└── grafana.json # IQA pipeline cost dashboard
Storage: S3 Objects + DynamoDB Metadata
Workflow:
1. Frontend → S3 presigned URL (upload-service)
2. S3 Event → Lambda → DynamoDB metadata + Tier routing
3. ML Tier → DepictQA IQA → Smriti RAFT (if needed) → S3 results
4. DynamoDB update: {quality_score, smriti_insights, tier_used}
5. Frontend queries DynamoDB → fetches S3 objects
DynamoDB Schema:
results_table:
- PK: result_id
- SK: user_id#timestamp
- quality_score (DepictQA)
- smriti_raft_score
- GSI1: user_id + quality_score (top heritage images)
Deployment: Independent Cadences
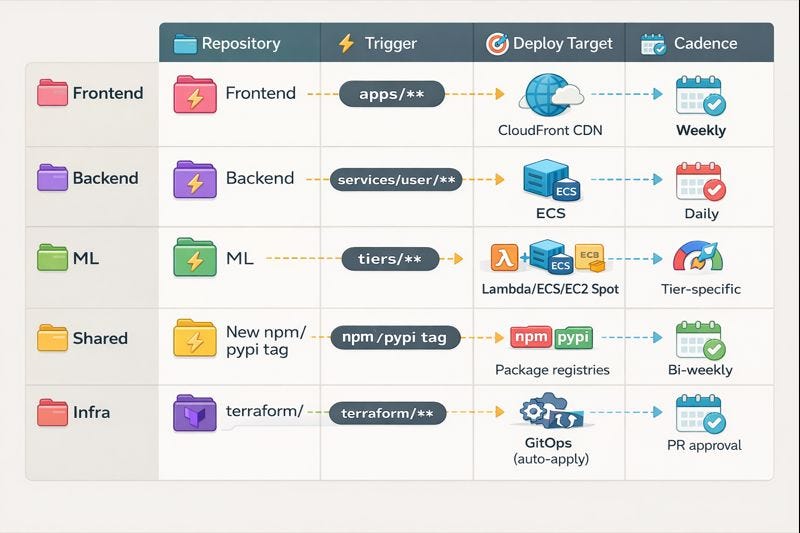
ML Tier 4 GPU Deployment:
yaml
name: Deploy RAFT GPU Tier
on:
push:
paths: [’models/smriti/**’, ‘tiers/tier4_gpu/**’]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Test DepictQA + Smriti RAFT
run: docker run --gpus all parjanya-ml pytest
- name: Deploy Spot GPU cluster
run: aws ec2 run-instances --spot --image-id gpu-ami \
--instance-type g4dn.xlarge --count 2
Why This Architecture? The Principles
1. ML Team Autonomy: Single ML repo = PyTorch/DepictQA/Smriti ownership
2. Cost Intelligence: 4-tier routes 95% to Lambda ($1.52) vs GPU ($50)
3. IQA Consistency: DepictQA single source of truth across all tiers
4. Indian Heritage Focus: Smriti RAFT purpose-built for cultural context
5. Infra Specialization: GPU Spot/ECS separate from CPU workloads
Risks We’re Watching
- ML dependency conflicts: PyTorch/DepictQA/Smriti version alignment
- Tier promotion logic: When Smriti RAFT needs Tier 3 vs Tier 4
- DepictQA evolution: Training/RAG/RAFT expansion while maintaining IQA truth
Part 2 will answer: Did 4-tier + single ML repo deliver? DepictQA/Smriti scaling? Cost savings?
Sources
https://depictqa.github.io/
https://depictqa.github.io/depictqa-wild/
https://depictqa.github.io/deqa-score/
https://arxiv.org/abs/2403.10131
https://docs.opencv.org/4.x/d2/d96/tutorial_py_table_of_contents_imgproc.html
https://phagyul.ai/