Sonnet 4.6 Became My New Benchmark for Building an Infra-Heavy VLM Platform

A few months ago, I wrote about why I believed in a Haiku-first strategy: start with the cheapest and fastest model possible, then escalate only when the task genuinely becomes harder. That idea still makes sense in principle.
But over the last few weeks, while working deeply on my VLM control plane / IQA platform, I realized something important:
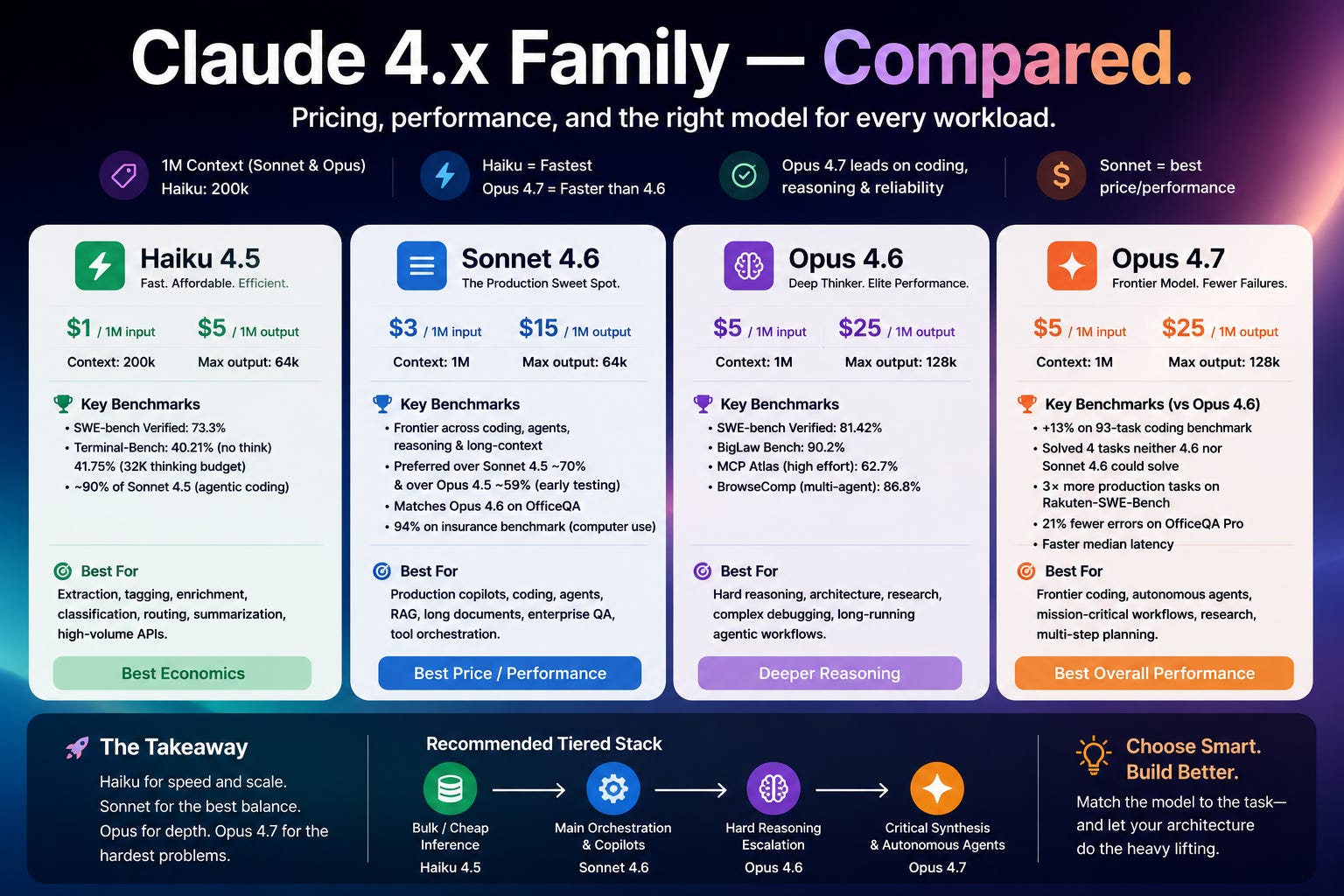
The benchmark itself had changed. Probably, the models are sitting across 4.5, 4.6 and 4.7 versions and found it hard to compare (Haiku 4.5 vs Sonnet 4.6 vs Opus 4.7 1M), I meant, gap is widened!
For my current workload, Sonnet 4.6 has become the model I now measure everything against.
Not because it is the smartest model Anthropic offers. Not because it is the cheapest. But because it currently sits at the most practical intersection of:
reasoning quality
long-context reliability
infra-heavy debugging
ML-heavy orchestration
coding consistency
operational cost
and sustained throughput
That combination matters a lot when you are building systems where the model is not simply “answering questions,” but continuously operating across orchestration, debugging, inferencing workflows, infrastructure decisions, and large-context reasoning.
The original Haiku-first thesis still holds
I still believe the core idea behind the earlier post was correct:
Default to the cheapest model that can reliably complete the task.
Anthropic’s pricing still makes that logic compelling.
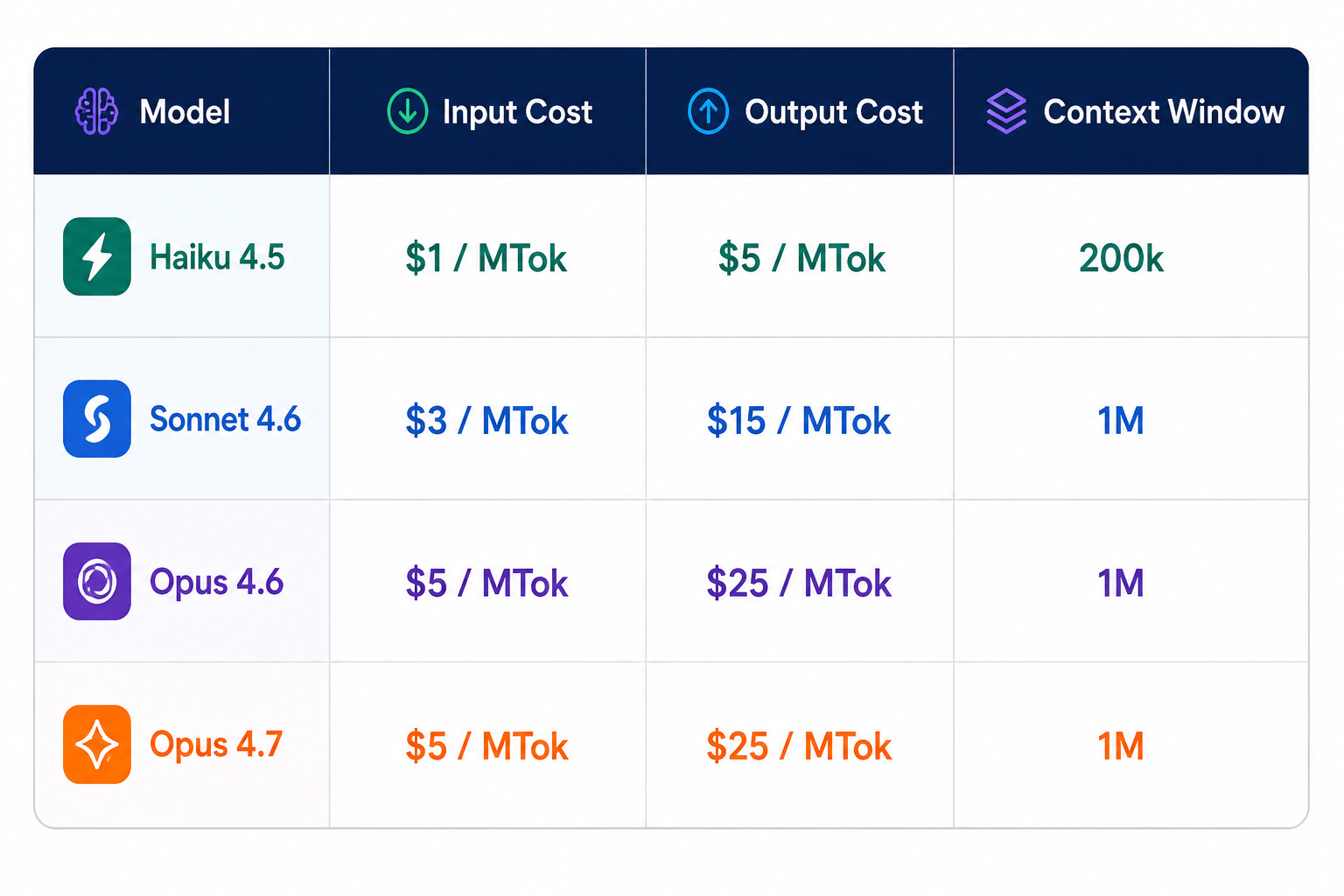
At scale, these economics matter enormously.
If you are running:
agentic workflows
multi-step debugging
recursive orchestration
long-context analysis
or VLM-heavy pipelines
…output-token costs become very real very quickly.
That is exactly why Haiku originally made so much sense.
But my workload changed
The problem is not that Haiku became “bad.” (also the gap across the models become evident due to version differences, Haiku is still at 4.5 with 200k context, whereas Sonnet and Opus at 4.6 and 4.7 with 1M Context)
The problem is that my workload evolved into something much more infra-heavy and ML-heavy.
The VLM control plane is no longer just lightweight orchestration or simple extraction work. The workflows now involve:
larger context retention
deeper architectural reasoning
distributed infra debugging
inferencing orchestration
stateful workflows
code + infra + ML reasoning in the same session
long-running debugging loops
and increasingly large operational context
This is where Sonnet 4.6 started to outperform Haiku dramatically in practical usefulness.
Why Sonnet 4.6 became my benchmark
Anthropic positions Sonnet 4.6 as the “best combination of intelligence, speed, and cost,” and honestly, that aligns closely with my own experience.
Sonnet 4.6 currently provides:
1M-token context window
adaptive thinking
fast latency
significantly improved coding quality
stronger instruction following
much better long-context coherence
Anthropic also mentioned that in Claude Code testing:
users preferred Sonnet 4.6 over Sonnet 4.5 roughly 70% of the time
and even preferred it over Opus 4.5 in many workflows
That honestly tracks with what I have seen.
Sonnet 4.6 feels much more stable in:
sustained coding sessions
infra debugging
architectural iteration
and orchestration-heavy workflows
without becoming economically painful the way Opus can become.
Haiku 4.5: still useful, but no longer my default
This is probably the most important nuance in the entire post.
Haiku 4.5 is still:
extremely fast
extremely cheap
very capable for its price tier
excellent for parallelized execution
strong for extraction/tagging/routing
surprisingly good on coding benchmarks
Anthropic reports:
73.3% on SWE-bench Verified
40.21% / 41.75% on Terminal-Bench
Those are genuinely strong results.
But benchmark scores alone do not determine operational usefulness.
In my own experience, Haiku 4.5 now feels degraded for my specific workload.
Not degraded universally.
Degraded for this class of infra-heavy, ML-heavy systems work.
What I started noticing:
unnecessary follow-up questions
command thrashing locally
context drift during debugging
inefficient iteration loops
loss of architectural continuity
excessive operational churn
Sometimes it felt like the model was spending more effort “doing activity” than actually advancing the task.
That was the turning point for me.
Sonnet became the operational center of gravity
So the strategy evolved.
I no longer think in terms of:
“Haiku everywhere unless proven otherwise.”
Now the stack looks more like this:
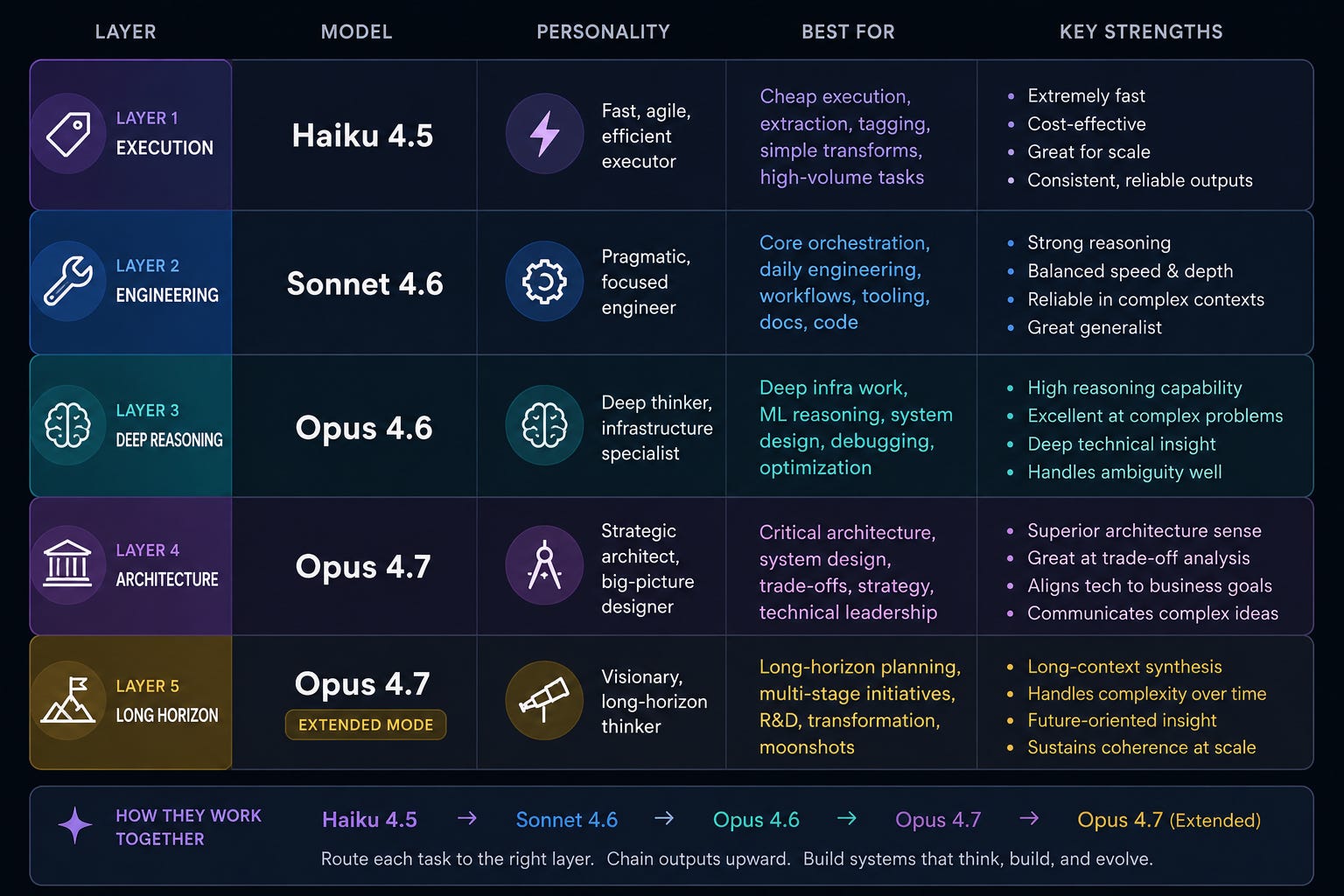
This feels significantly more stable operationally.
Where Opus still matters
I still escalate aggressively to Opus for:
architectural redesigns
distributed systems debugging
ML-heavy reasoning
difficult infra changes
large-context synthesis
high-stakes production decisions
This is where the Opus models still separate themselves.
Anthropic’s published numbers are notable:
Opus 4.6: 81.42% SWE-bench Verified
90.2% BigLaw Bench
strong long-context retrieval
better reasoning across hundreds of thousands of tokens
Opus 4.7 improves further:
13% improvement on a 93-task coding benchmark
solved 4 tasks neither Sonnet 4.6 nor Opus 4.6 could solve
3× more production-task resolutions on Rakuten-SWE-Bench
21% fewer errors on OfficeQA Pro
You can actually feel some of these improvements during long debugging sessions.
Especially:
reduced context drift
better continuity
fewer reasoning collapses
stronger architectural consistency
Adaptive thinking changes the workflow significantly
One under-discussed improvement is adaptive thinking.
Sonnet 4.6 supports it.
Opus 4.6 supports it.
Opus 4.7 uses it exclusively.
This matters because:
the model dynamically allocates reasoning effort
easier tasks complete faster
harder tasks receive deeper reasoning automatically
For infra-heavy workflows, this is a huge operational improvement.
Especially when the same session moves across:
infra
application logic
orchestration
ML behavior
and debugging
without explicit model switching every few minutes.
Something interesting I noticed about Haiku switching automatically
One thing I still need to investigate further:
I occasionally noticed Claude seemingly switching into Haiku behavior automatically during sessions.
I initially thought this happened only at the beginning of sessions, but after more usage I suspect it can happen mid-session as well.
Anthropic’s Claude Code docs actually support this possibility:
model switching can happen dynamically
subagents can use Haiku automatically
planning/execution layers may use different models internally
That would explain some of the behavior I observed:
sudden increases in unnecessary questioning
lightweight command loops
simplified reasoning paths
or execution-style interactions appearing inside longer workflows
I do not think this is inherently bad.
It actually makes sense architecturally.
But on infra-heavy workflows, it can sometimes become noticeable.
The timing of this shift matters for me personally
This transition is happening at an important moment.
I am currently preparing:
dev + prod environment separation
launch readiness
infrastructure stabilization
ML inferencing orchestration
and final architectural refinement
ahead of launch in roughly two weeks.
That timing matters because the recent Anthropic infrastructure and limit improvements are actually having a practical operational effect.
Anthropic recently:
removed dedicated 1M-context rate limits for supported models
expanded higher-usage limits
improved capacity availability
and publicly discussed large-scale compute partnerships
I do not want to get into commercial details.
But practically speaking:
peak-hour friction has reduced significantly
longer debugging sessions feel more reliable
large-context sessions are more usable
and the additional headroom gives much more leverage for coding and debugging
That matters a lot when your workflows involve:
long-context infra debugging
VLM inferencing orchestration
architecture synthesis
and recursive engineering sessions
Bottom line
My original Haiku-first idea still solid and would try working on enhancing further in future versions. (Plan is to leverage, multiple models across the frontier models, both models like Claude, codex and free versions like Gemma4, Qwen3.6 etc.)
But the center of gravity moved.
Today:
Haiku 4.5 is my narrow execution layer
Sonnet 4.6 is my operational benchmark
Opus 4.6 is my deep reasoning escalation
and Opus 4.7 is the model I reserve for the hardest architectural and ML-heavy problems
The real lesson is not:
“Always use the smartest model.”
And it is also not:
“Always optimize for cost.”
The real lesson is:
The best model is the one that remains operationally useful under your actual workload.
For my current stack, Sonnet 4.6 is now that benchmark.

References & Further Reading
Anthropic Documentation & Official Notes
Anthropic Claude Models Overview
Official model capabilities, context windows, adaptive thinking, latency tiers, and supported features for Haiku, Sonnet, and Opus.Anthropic Pricing Documentation
Current pricing for Haiku 4.5, Sonnet 4.6, Opus 4.6, Opus 4.7, prompt caching, batch processing, and 1M-context usage.Claude Code — Costs & Model Usage Patterns
Useful for understanding model switching, subagents, orchestration strategies, and practical guidance on when to use Haiku vs Sonnet vs Opus.
My Related Notes & Blogs
Why You Should Choose Haiku as Default
My earlier thesis on why a Haiku-first strategy originally made sense economically and operationally.Opus 4.7 — Initial Practical Observations
Early notes on context retention, hallucinations, workflow behavior, and operational observations while testing Opus 4.7.Jagadeesh Rampam — Substack Archive
Broader writing on infra-heavy systems, AI engineering workflows, AWS architecture, ML systems, and long-context operational patterns.
Engineering & Long-Context Best Practices
OpenAI — Prompt Engineering Best Practices
Strong reference for practical orchestration, structured prompting, decomposition, and reliability strategies across long workflows.AWS Well-Architected Framework
Essential reading for scalability, operational excellence, cost optimization, reliability, and architectural trade-offs in infra-heavy systems.Google SRE Workbook
One of the best operational references for debugging culture, monitoring, production reliability, incident management, and long-running system operations.