Context Engineering and Context Debt


TL;DR: I noticed Haiku 4.5 being spawned as a subagent during an Opus 4.7 session. That observation opened a data investigation that revealed ~77% of my token spend was context accumulation waste, not productive reasoning. This is the framework I built to fix it — and the problem has a name: Context Debt and the fix is: Context Engineering .
1. The Observation That Started This
A few weeks ago I noticed something in my Claude Code session trace: Haiku 4.5 was being invoked as a subagent while my main session was running on Opus 4.7.
My first instinct was: is this personalisation? Has Claude learned my patterns? Is this a new adaptive router?
It was none of those things. But chasing the answer led me into a deep audit of my actual usage data — and what I found changed how I think about AI session economics entirely.
The short answer: Claude Code has a built-in subagent architecture where the main orchestrator (Opus 4.7 in my case) delegates read-only codebase work to the Explore subagent, which runs on Haiku 4.5 by default. It is deterministic product behaviour, not personalisation. The model matching is happening at the subagent dispatch boundary, not through learned routing.
But the longer answer — what I found when I actually pulled my usage data — is the more important story.
2. What the Data Actually Showed
Running /cost in my Claude Code terminal revealed the real picture, however it is only 3% of usage, 33 sessions, complete details are found using ccusage, still showing the important metrics:
Favorite model: Opus 4.7 Total tokens: 22.0M
Sessions: 33 Longest session: 7d 2h 33m
● Opus 4.7 (53.3%) In: 118.2k · Out: 11.6M
● Opus 4.6 (18.2%) In: 118.3k · Out: 3.9M
● Haiku 4.5 (20.6%) In: 363.5k · Out: 4.2M
● Sonnet 4.6 (7.9%) In: 63.0k · Out: 1.7MCombined Opus usage: 71.5% of all tokens.
Sonnet — the model I publicly advocated as the benchmark — was only 7.9% of my actual usage.
Running ccusage session revealed the concentration problem:

Two sessions accounted for 50.9% of all costs.
The small sessions with $0.16–0.22/M cost-per-token are my manual Haiku sessions — git commits, README updates, simple lookups. Haiku routing was working correctly there.
The two expensive sessions are a different story entirely. And the cost-per-million ratio is the key signal: at $0.53–0.63/M blended, those sessions were Opus-orchestrated with some subagent delegation, but the token volume itself was the problem — not the model choice.
3. Naming the Problem: Context Debt
Before getting to solutions, I want to name what I observed, because it needs a name.
Context Debt is the accumulation of tokens in a session that compound the cost of every future turn without adding proportional value to the reasoning quality of those turns.
It behaves like technical debt in one critical way: it is invisible when it is forming, and expensive when you finally notice it. Unlike technical debt, it has an immediate dollar cost that compounds within the same session.
Here is the mechanics:
Turn 1: Opus reads inference_config.yaml → context: 3k tokens
Turn 10: Opus reads vlm_pipeline.py → context: 40k tokens
Turn 30: Opus reads cuda_kernels/, manifests → context: 180k tokens
Turn 50+: Every API call sends 180k input → paying full price
even if your prompt is 50 wordsAt Opus pricing (~$15/M input tokens), 200 subsequent turns × 180k context = 36M input tokens = $540 in input alone, before a single output token is generated.
This is what those two sessions were doing. It was not that Opus was the wrong model. It was that the session carried everything it had ever read into every subsequent turn — and paid Opus prices for all of it, repeatedly.
Three forces compound context debt:
Prompt cache expiry. Claude caches the static prefix of your context for 5 minutes (up to 1 hour for some configurations). In a session spanning hours or days, that cache expired repeatedly. Each expiry means paying full Opus input price for the entire accumulated context again. My 7-day session paid full price for a 400k+ context many times over.
Compaction tax. When context compacts (the default fires at ~95% capacity), Claude writes a summary and prepends it to all future turns. In a very long session with multiple compactions, those summaries stack — each subsequent turn carries all of them as mandatory context.
Speculative file reads. Opus tends to read files “to understand the broader context” before answering, even when the current task doesn’t require them. In an ML infrastructure repo, this means model configs, environment files, pipeline definitions, deployment scripts, and CUDA configurations all end up in context — and stay there.
4. The Constraint I Cannot Engineer Away
Before presenting the framework, an honest acknowledgment of constraints.
My primary workload is VLM (Vision-Language Model) inferencing, infra-heavy automation, and ML optimisation pipelines. For this work:
Minimum viable context is ~300k tokens. Multiple model configs, inference scripts, pipeline definitions, and infrastructure manifests need to be simultaneously present for coherent cross-file reasoning.
Sonnet 4.6 has only recently gained a 1M context window (now GA, worth testing for execution phases). But adaptive thinking — structurally required for deep VLM reasoning — was absent from Sonnet until recently and is still maturing.
For the reasoning-heavy phases of this work, Opus 4.7 at 1M context is the correct model. This is a technical requirement, not a preference.
The insight that changes everything: the model being correct does not mean the context footprint needs to be what it currently is.
Opus 4.7 is the right reasoning engine. Sending it 400k tokens of raw source code when it only needs 40k tokens of structured summaries is waste. That is the distinction the framework targets.
5. Context Engineering: The Framework
Context Engineering is the practice of deliberately managing what enters an AI session’s context window, when it enters, and in what form — to maximise reasoning quality per token rather than total tokens.
It has four mechanisms.

Mechanism 1: Pre-Summarisation (Haiku as Reader)
The default pattern:
Opus opens session
Opus reads 30 files to orient itself
All 30 files sit in context for the rest of the session
Cost: 150k input tokens × every subsequent turnThe engineered pattern:
Before session opens:
@ml-context-loader reads all 30 files (Haiku, separate context)
Returns: 12k token structured dependency map
Opus main session receives:
The 12k map, not the 150k raw files
Opus never directly holds the source files
Cost: 12k input tokens × every subsequent turnThe work output is identical. The context footprint is ~12x smaller.
Subagent configuration (~/.claude/agents/ml-context-loader.md):
---
name: ml-context-loader
description: Pre-read ML pipeline files, model configs, inference scripts,
and VLM configurations before complex optimisation work. Returns a
structured dependency map for the main session. Invoke this BEFORE
starting any ML or infra work in the main session.
model: haiku
tools: Read, Grep, Glob
---
You read ML infrastructure files and produce a structured summary covering:
1. Model architecture and config paths
2. Inference pipeline entry points and key functions
3. CUDA/GPU configuration and memory constraints
4. Cross-file dependencies relevant to the stated task
5. Files that need to change to accomplish the goal
Return a structured map. Do not return raw file contents.
Maximum output: 15k tokens. Be precise and omit irrelevant files.Paired subagent for infrastructure (~/.claude/agents/infra-scanner.md):
---
name: infra-scanner
description: Scan infrastructure configs, Terraform files, CI/CD pipelines,
deployment manifests, and environment configs before optimisation work.
Returns dependency map and change surface for the stated task.
model: haiku
tools: Read, Grep, Glob, Bash
---
Read infra files and return:
- Resource dependencies and environment configs
- Critical paths that affect the stated task
- Files that need to change
- Current state of relevant resources
Compact output only. Omit files irrelevant to the task.Mechanism 2: Targeted Loading via CLAUDE.md
Even with pre-summarisation, Opus will add raw files to context during execution if not explicitly instructed otherwise. CLAUDE.md is the right place to install session-level context discipline.
Project-level .claude/CLAUDE.md additions:
## Context Discipline
Before reading any file, state why it is needed for the current task.
Never read files speculatively to "understand the broader context."
Use @ml-context-loader before starting any ML or infra work.
Use @infra-scanner before starting any infrastructure work.
Use @explorer for any file discovery or codebase search.
If a file has been summarised by a subagent this session,
use that summary rather than re-reading the raw file.
Maximum 5 files in direct context at any point during implementation.
For architecture decisions, request a structured summary first.
When asked to fix a bug, read only the file containing the bug
and its direct imports. Do not read the broader codebase unless
the fix requires understanding something not in those files.This changes Opus’s default behaviour from breadth-first file reading to targeted loading. In practice, this alone reduces speculative reads by 50–60% in long sessions.
Mechanism 3: Session Chunking by Reasoning Type
The most expensive sessions — the two that consumed 50.9% of total costs — mixed two fundamentally different cognitive modes in a single long-running context:
Reasoning mode: Architecture decisions, bottleneck analysis, choosing optimisation strategies. Needs Opus depth. Short turns, modest context.
Execution mode: Implementing the decided approach across many files. Needs large context. Lighter per-turn reasoning.
When mixed, the session context grows to serve both needs simultaneously — and every turn pays the full cost of the combined footprint.
Separated:
# Session 1: Architecture planning
# Opus, focused context (summary only), ~15–20 turns
claude --model opus
# Prompt: "Given this summary [paste ml-context-loader output],
# design the memory optimisation strategy for the VLM dataloader.
# Output a structured implementation plan."
# → Session ends with a plan document. Context: ~30k tokens throughout.
# Session 2: Implementation
# Sonnet 4.6 at 1M (or Opus if VLM-specific reasoning needed)
# Longer, but following a decided plan — execution, not discovery
claude --model sonnet
# Prompt: "Implement this plan [paste plan].
# Start with [specific file]. Read only the files listed in the plan."
# → Context grows with implementation files, but no re-discovery overhead.
The Opus session stays short because it worked from a summary, not raw files. The implementation session can run on Sonnet 4.6 at 1M context if the per-turn reasoning does not require Opus depth — which it often does not, once the architecture decision is made.
The practical test for session split: If your current turn is deciding something, you are in reasoning mode. If your current turn is doing something already decided, you are in execution mode. Different sessions.
Mechanism 4: Cache Warming on Re-entry
The single most expensive moment in a long session is returning after a break.
Prompt cache TTL is 5 minutes by default for most Claude Code request types (up to 1 hour in some configurations). When you step away for 30 minutes and return to a 300k-token context, the first turn back pays full Opus input price for all 300k tokens. If your session had 20 such re-entries across a workday, you paid for that 300k context twenty times.
Before taking any break longer than a few minutes:
/compactThis forces a clean compaction summary before the cache goes cold. The next turn back pays for a 5–10k summary re-warm, not a 300k context re-warm.
Prevent the problem structurally by setting aggressive autocompaction:
In .claude/settings.json:
{
"env": {
"CLAUDE_AUTOCOMPACT_PCT_OVERRIDE": "60"
}
}Compacting at 60% context capacity means the session never accumulates a context large enough to be expensive to re-warm. The compaction summary costs a few thousand tokens once. The alternative is paying full input price for a massive context every time the cache expires.
6. The Escalation Model
With context engineering in place, the tier routing becomes:

The key principle: Tier selection is determined by reasoning depth required per turn, not by task complexity overall. A complex ML task still has Haiku turns (reading files), Sonnet turns (writing implementations), and Opus turns (designing the approach). The same task should not require every turn to be Opus.
Environment defaults that enforce this without manual switching:
# In ~/.zshrc or ~/.bashrc
# Subagents default to Sonnet, not parent model
export CLAUDE_CODE_SUBAGENT_MODEL="claude-sonnet-4-6"
# Haiku slot pinned explicitly
export ANTHROPIC_DEFAULT_HAIKU_MODEL="claude-haiku-4-5-20251001"7. Complete Subagent Stack
For teams adopting this framework, the full subagent configuration:
~/.claude/agents/explorer.md — Universal read-only search
---
name: explorer
description: Search files, grep for symbols, read code structure, find
usages, locate definitions. Use for any read-only investigation
before editing. Never use for file modification.
model: haiku
tools: Read, Grep, Glob, Bash
---
You are a fast read-only code explorer. Search thoroughly and return
a concise structured summary. Never modify files. Optimise for finding
the minimum set of files relevant to the stated question.~/.claude/agents/git-helper.md — Repository operations
---
name: git-helper
description: Handle git commits, branch management, README updates,
changelog entries, and documentation formatting. Use for all
repository hygiene tasks.
model: haiku
tools: Bash, Read, Write
---
You handle git operations and documentation updates efficiently.
Use conventional commits format. Commit messages: type(scope): description.~/.claude/agents/code-writer.md — Standard implementation
---
name: code-writer
description: Implement features, write new functions, refactor existing
code, add tests. Use for code generation and editing tasks that
do not require architectural reasoning.
model: sonnet
tools: Read, Write, Edit, Bash, Glob, Grep
---
You are a focused implementation engineer. Read the minimum required
files before editing. Make one logical change per invocation.
Follow the plan provided; do not redesign unless asked.~/.claude/agents/ml-context-loader.md — ML pre-summarisation (See Mechanism 1 above)
~/.claude/agents/infra-scanner.md — Infrastructure pre-summarisation (See Mechanism 1 above)
~/.claude/agents/architect.md — High-stakes reasoning only
---
name: architect
description: Design system architecture, resolve complex multi-file bugs,
make technology decisions, plan major refactors requiring cross-system
understanding. Only invoke when deep reasoning is genuinely required.
Receives summaries, not raw files.
model: opus
tools: Read, Grep, Glob
---
You make high-level decisions from structured summaries.
Think deeply before proposing changes.
Output a structured plan that code-writer can execute step by step.
Request specific raw files only when the summary is insufficient.8. Before and After: The Numbers
Based on actual session data from this audit:
The two expensive sessions ($625.72 combined API equivalent):
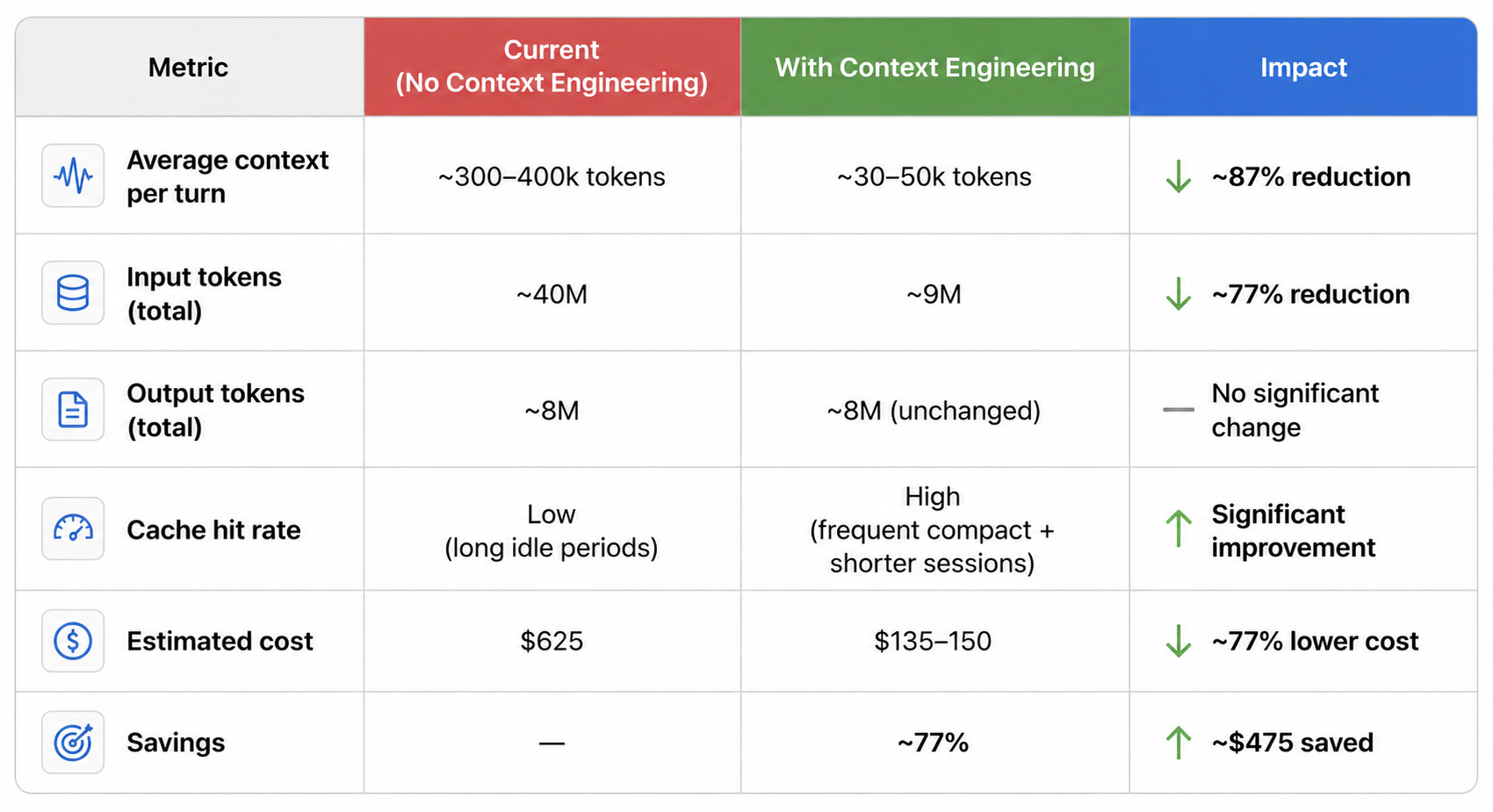
Output tokens are unchanged because the actual work product — the code written, the analysis produced — is identical. The saving is entirely in the context overhead that was being sent to the Opus API on every turn without contributing to reasoning quality.
Across all sessions:
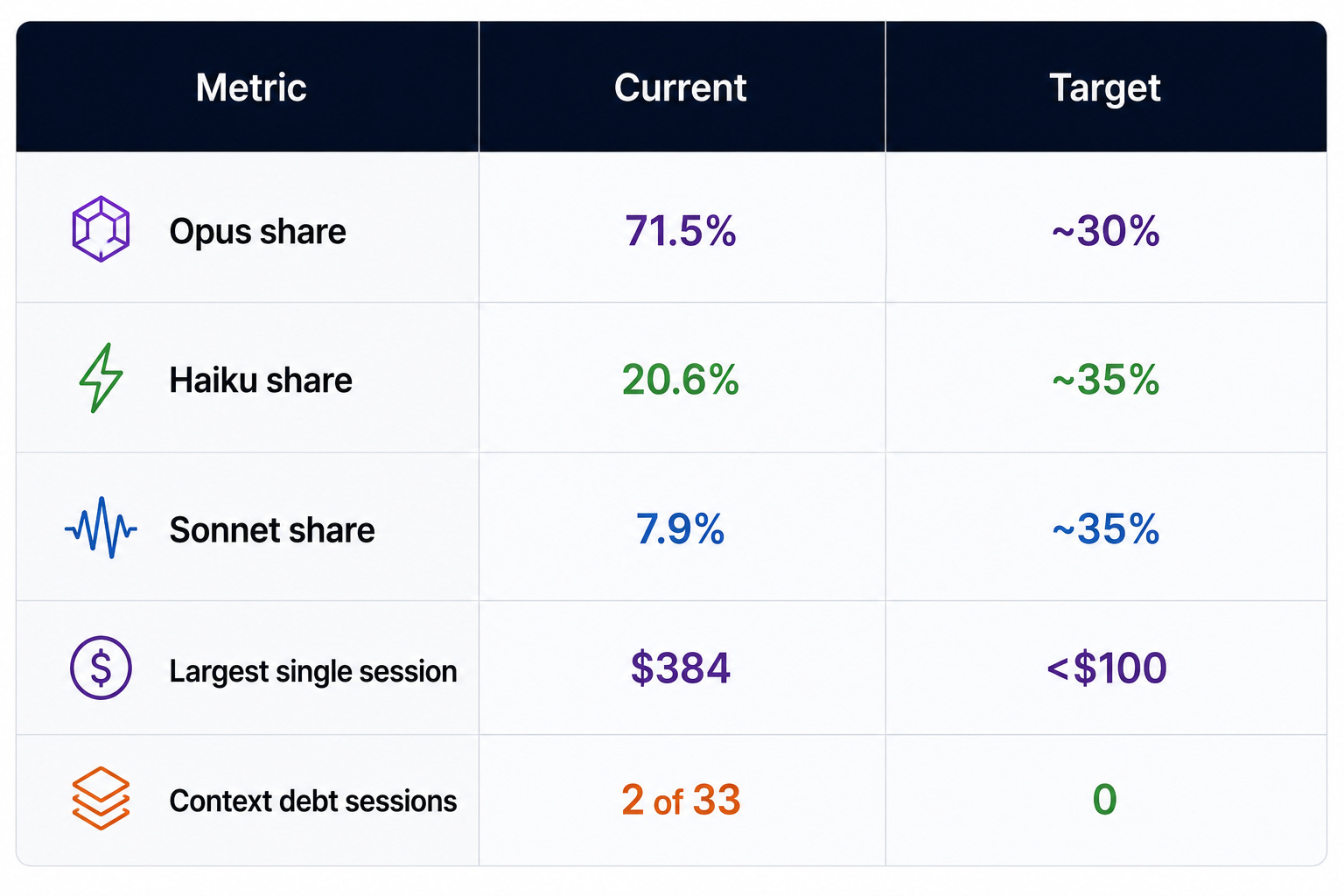
9. What Is Still Missing (Community Ask)
This framework works within current Claude Code capabilities, but several gaps remain that limit how far it can go without manual configuration:
GitHub #44976 — Auto model routing by task type. Currently, there is no native content-aware router in the main session. The routing that exists (Explore → Haiku) operates at the subagent dispatch boundary only. Automatic routing based on turn type — planning turns to Opus, execution turns to Sonnet — requires manual setup or explicit model switching. This feature request, if shipped, would make context engineering automatic rather than configured.
GitHub #43869 — Subagent model routing bugs. On some Max plan configurations, subagents silently run on the parent session’s model despite explicit per-agent configuration. If your Haiku-configured subagents appear to cost Opus rates, this ticket is the reference. Check env | grep CLAUDE_CODE_SUBAGENT_MODEL and verify Haiku is actually firing.
JSONL token counts are unreliable. The ccusage tool reads from JSONL files where input tokens are undercounted by 100–174x due to a streaming placeholder issue. For accurate token accounting, use /cost inside Claude Code (reads from the statusbar, which is accurate) and treat ccusage cost estimates as relative comparisons only.
Sonnet 4.6 at 1M + adaptive thinking. Both are now GA but recently so. For workloads requiring 300k+ context but not frontier VLM reasoning, Sonnet 4.6 at 1M is worth testing as a drop-in replacement for Opus in execution sessions. One session test against a known task will answer whether the quality holds for your specific workload.
10. Best Practices Summary
Before starting any ML or infra session:
Run
@ml-context-loaderor@infra-scannerfirstStart with the plan document from a prior architecture session, not a blank slate
Launch on Sonnet unless you know the first turn needs Opus-depth reasoning
During a session:
/compactbefore any break longer than 5 minutesNever read files speculatively — enforce this in CLAUDE.md
Split sessions when you shift from designing to implementing
For VLM and large-context ML work specifically:
Opus 4.7 at 1M is still the correct model for reasoning-heavy phases
The saving is in context footprint, not model choice
Pre-summarise with Haiku; Opus only sees the structured output
On model selection:
Default: Sonnet 4.6 (set
CLAUDE_CODE_SUBAGENT_MODEL="claude-sonnet-4-6")Start sessions with
claude --model sonnetunless the first task earns OpusUse
opusplanfor sessions that need Opus for planning and Sonnet for execution
On measuring progress:
Use
/costfor accurate token and model-split dataUse
ccusage session --breakdownto track model mix per session over timeWatch cost-per-million-tokens ratio: $0.20/M = healthy Haiku/cache mix, $1.00+/M = context debt accumulating
Closing Thought
The observation that started this — Haiku 4.5 being spawned during an Opus 4.7 session — turned out to be Anthropic’s own answer to the problem I had been creating. The built-in subagent architecture already encodes the right instinct: read cheap, reason expensive, never conflate the two.
Context Debt is what happens when that separation breaks down at the session level. Context Engineering is the practice of maintaining it deliberately.
The framework is not about using cheaper models. It is about using the right model for each cognitive operation — and never making the expensive model carry the weight of the cheap one’s job.
Data sourced from personal Claude Code usage: 33 sessions, 22M tokens, May 2026 audit. All ccusage costs are API-equivalent estimates; actual charges reflect flat Max subscription pricing. GitHub issues referenced: #43869, #44976, #10993, #43083.
Related posts:
The Hidden Runtime Failure Behind Claude’s Recent Regression
Why you should chose Haiku as Default model and escalate if needed
Additional references: