TBIE in Practice: Designing Resilient AI Pipelines That Recover, Reconcile, and Re-run

Abstract
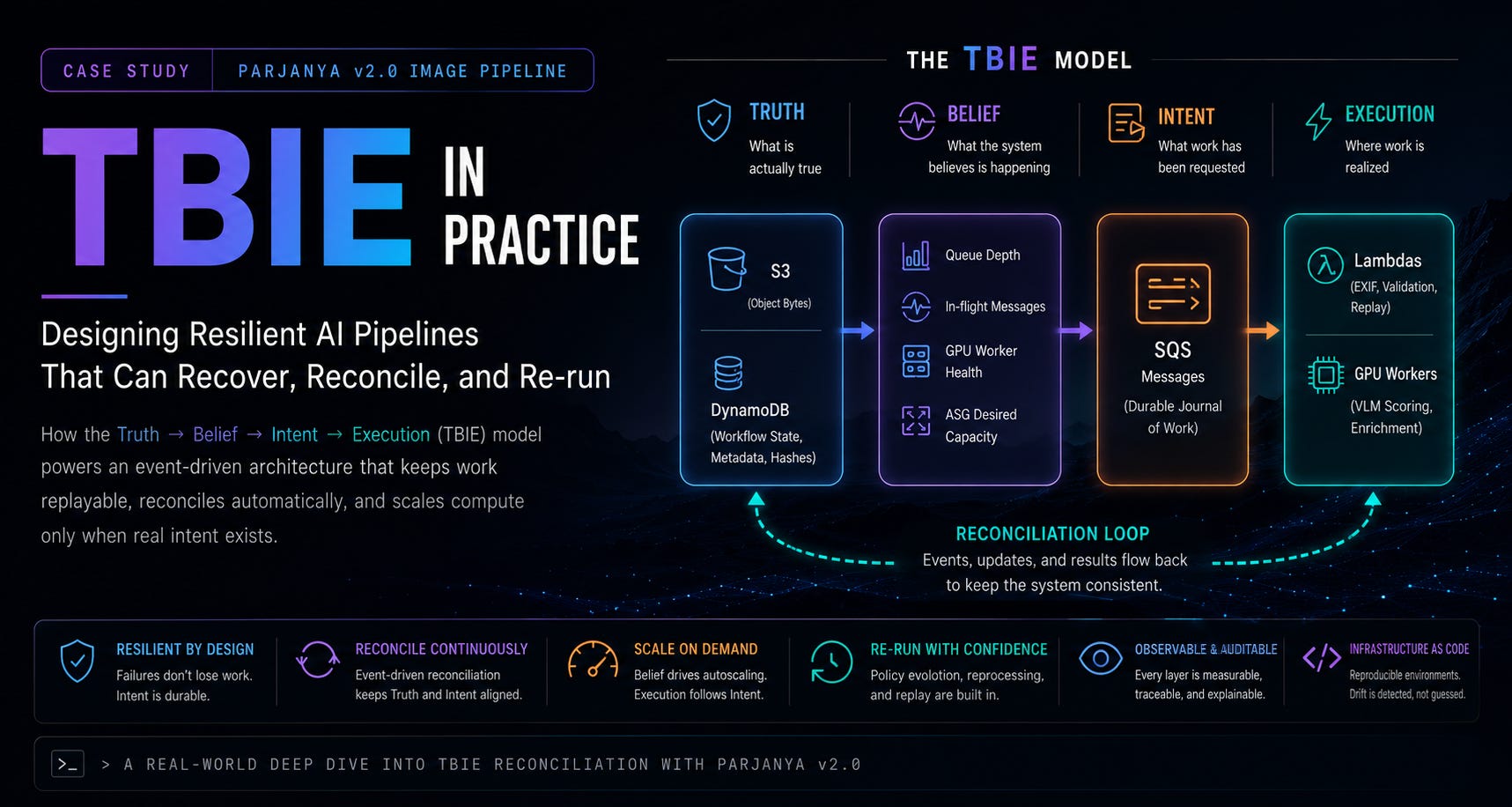
Resilient AI infrastructure is not defined only by model quality, throughput, or scaling efficiency. In production, the harder problem is reconciliation: keeping durable state, requested work, and actual execution aligned when workers fail, queues drift, storage paths change, policies evolve, and control planes become blind. Let me present TBIE, a practical operating model for distributed systems: Truth, Belief, Intent, and Execution. TBIE separates the authoritative record of what is true from the operational view of what seems to be happening, the replayable journal of work that should occur, and the stateless workers that realize side effects.
I have used Parjanya v2.0, an image ingestion and GPU-based visual scoring platform, as a detailed case study. Parjanya’s architecture spans immutable uploads, DynamoDB workflow state, SQS-based intent, event-driven replay, GPU autoscaling, browser-side uploads, policy regrading, and infrastructure drift. Across these layers, TBIE proved useful not as a slogan but as a diagnostic and design framework. It clarified why transient worker failure should not destroy replayable work, why pending state without corresponding intent is a reconciliation gap, why wrong-bucket routing can be deterministically wrong, why policy changes should be handled as controlled replay, and why control-plane blindness is more dangerous than isolated worker failure.
The central claim of this is that resilient AI platforms should be designed as reconciliation systems rather than one-way pipelines. A pipeline moves data forward. A reconciliation system continuously repairs the alignment between truth and work until intended outcomes are actually realized. That distinction changes how we design queues, retries, autoscaling, observability, IAM boundaries, tenant onboarding, model packaging, browser uploads, and recovery runbooks.
1. Introduction
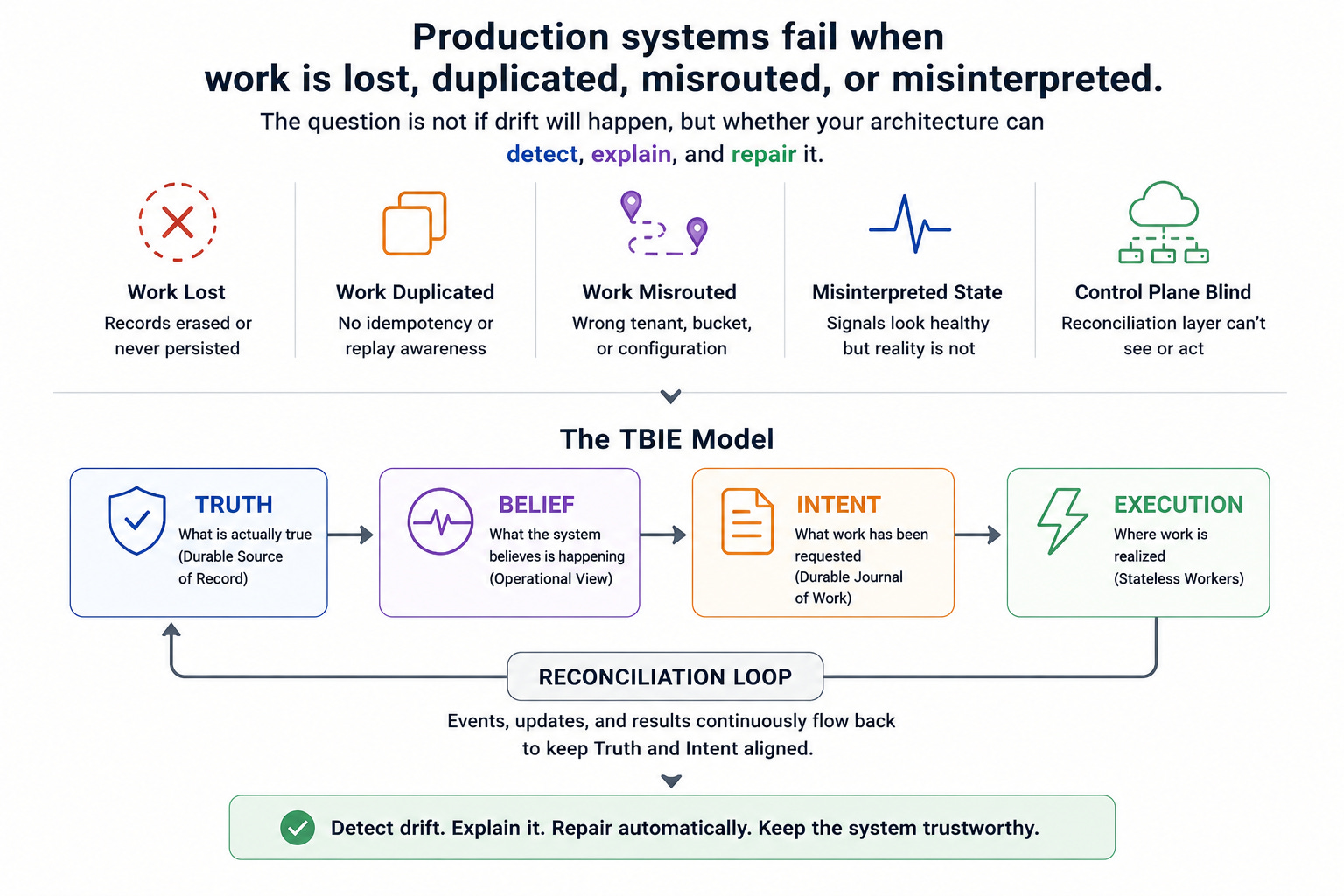
Modern AI systems are often described in terms of model choice, hardware selection, vector stores, and inference efficiency. Those concerns are important, but they are not usually what breaks production systems. In practice, systems fail because they lose work, duplicate work, misroute work, or misinterpret what is actually happening. A queue may look healthy while the underlying work has already vanished. A worker may crash without leaving a replayable record. A browser upload may fail after the backend has already committed a pending state. An autoscaling group may be configured correctly while the reconciliation control plane that should activate it is blind.
These failures are not unusual edge cases. They are the normal shape of distributed systems under stress. The question, then, is not whether a system will experience drift between state and execution, but whether the architecture is built to detect, explain, and repair that drift. TBIE was developed as a response to that question.
TBIE stands for Truth, Belief, Intent, and Execution. It is a practical decomposition of distributed systems that helps separate durable facts from operational signals, requested work from realized work, and recoverable failures from terminal ones. The model is especially useful in asynchronous AI pipelines, where storage, metadata, queues, workers, and control planes all operate independently and can fail independently.
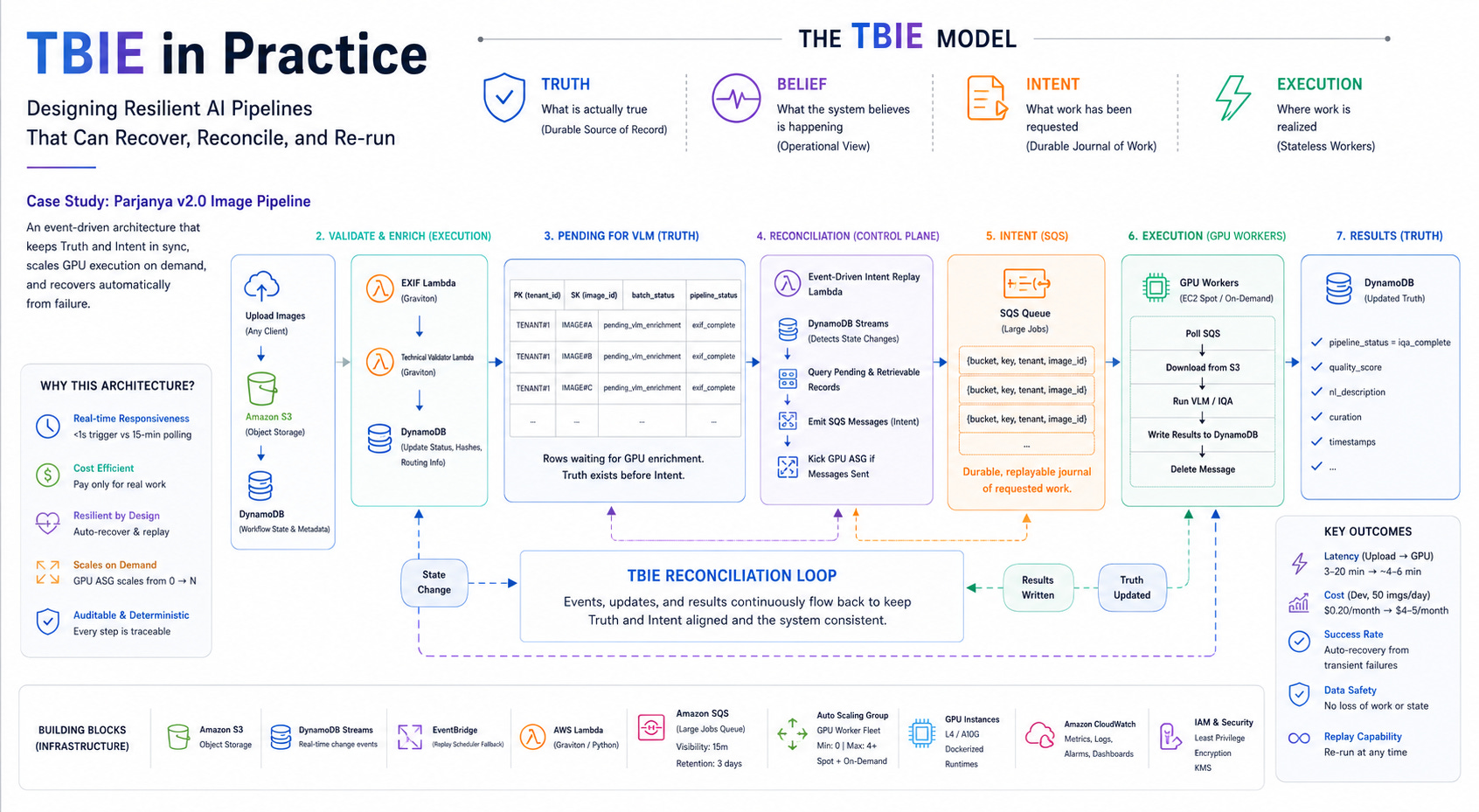
Parjanya v2.0 is an ideal case study because it combines all of those surfaces in a single system. Images are uploaded to S3. Metadata is written to DynamoDB. GPU work is performed asynchronously through SQS. Lambda functions handle technical validation and replay orchestration. GPU workers consume intent, perform visual-language inference, and write enriched truth back to the database. Autoscaling responds to queue depth. Browser uploads interact with tenant-specific buckets and CORS policies. Policy changes require historical reprocessing. Infrastructure drift can occur in launch templates, AMIs, model packages, and endpoint configuration.
Let’s deep dive how TBIE behaves in practice.
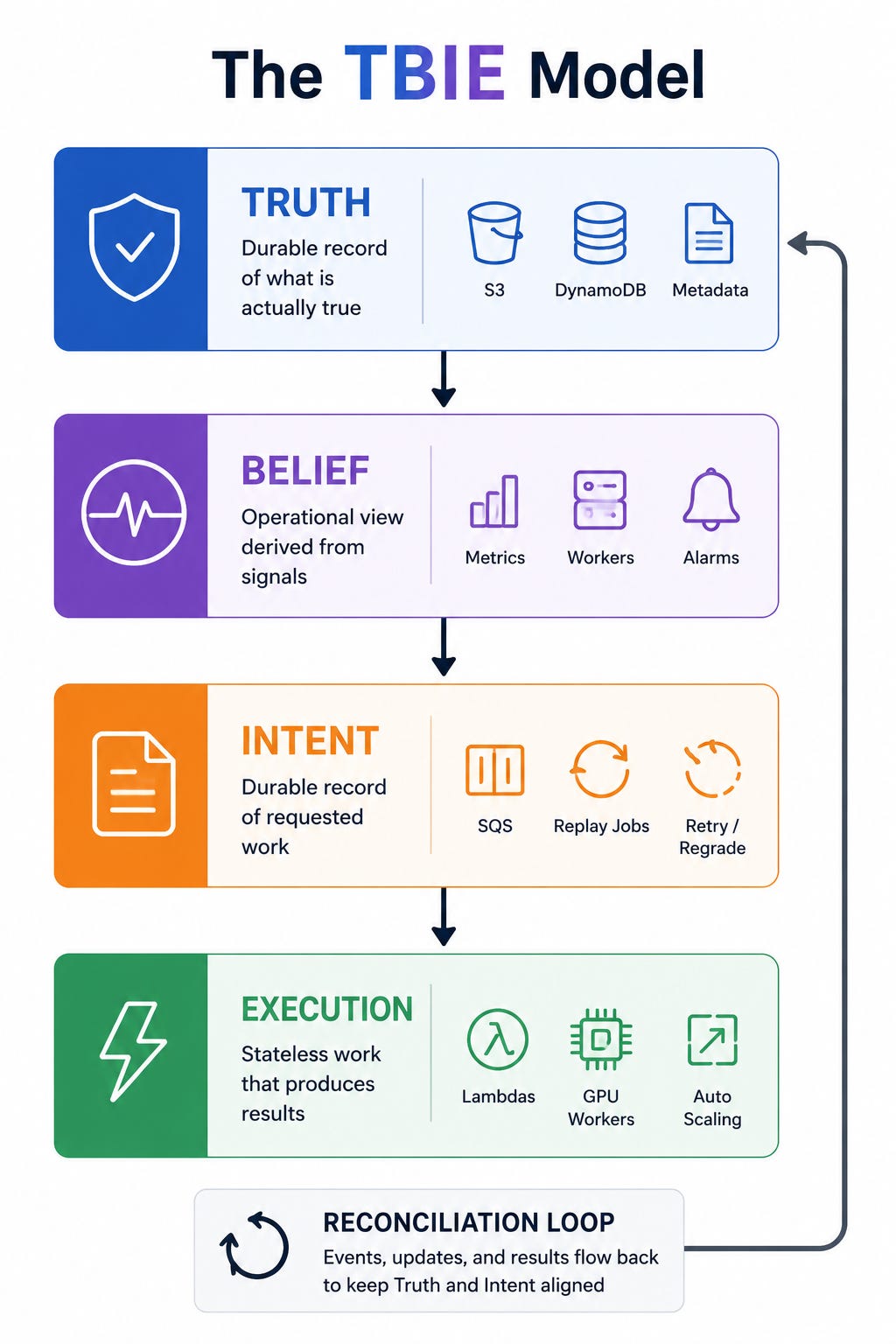
2. The TBIE Model
TBIE divides a distributed system into four layers that must remain conceptually distinct.
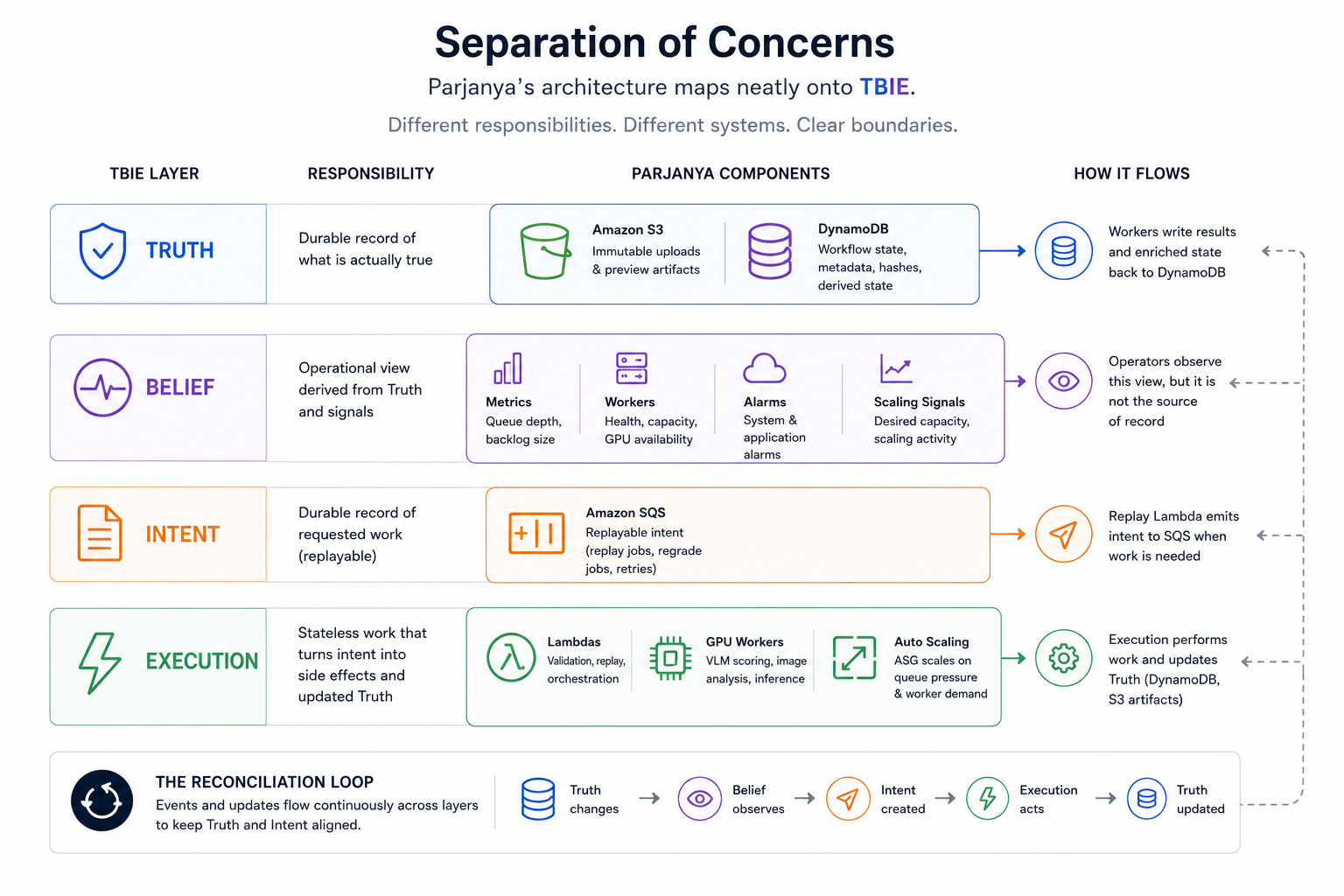
2.1 Truth
Truth is the durable record of what is actually true. It should survive worker restarts, deploys, transient outages, and runtime drift. In Parjanya, Truth lives in immutable S3 objects, DynamoDB workflow rows, hashes, status fields, curation metadata, and derived state that has been durably committed. Truth answers questions such as: What object exists? What stage of the workflow is this image in? What has already been computed? What is the authoritative record of the tenant, batch, or image?
2.2 Belief
Belief is the operational view of reality. It is derived from Truth and current signals, but it may lag, be partial, or be noisy. In Parjanya, Belief includes queue depth, in-flight message counts, worker health, GPU availability, desired ASG capacity, scaling activity, and alarm state. Belief is what operators see first, but it must not be confused with source-of-record truth.
2.3 Intent
Intent is the durable record of work that has been requested. It is the journal of “please do this work.” In Parjanya, SQS messages represent Intent. Replay jobs, regrade jobs, and retry workflows are all forms of Intent. The critical property of Intent is replayability. If Intent can be lost too early, then transient failures become permanent failures and manual rescue becomes necessary.
2.4 Execution
Execution is the stateless work that turns Intent into side effects and updated Truth. In Parjanya, Execution includes Graviton Lambdas for EXIF extraction and technical validation, GPU workers for VLM inferencing and image quality analysis, replay jobs that reconstruct missing Intent, and autoscaling actions that wake the worker fleet when work appears. Execution is where work happens, but in a resilient system it must never be allowed to erase the record of what was supposed to happen.
3. Why Reconciliation Matters
The key insight behind TBIE is that a distributed system is not healthy merely because its components are running. Health depends on reconciliation. A system can be superficially alive while still being functionally stuck. A database row may say pending_vlm_enrichment while no SQS message exists. A queue may be empty while worker work is still pending in truth. A control plane may be scheduled while unable to read the signals it needs to act.
Reconciliation is the process of bringing Truth, Intent, and Execution back into alignment. In the TBIE model, reconciliation is not a background nicety; it is the core operating principle. Systems should not rely on humans noticing a stale queue and manually fixing it. They should be able to repair the missing relationship between truth and work on their own.
This is why the distinction between a pipeline and a reconciliation system matters. A pipeline assumes a mostly linear progression from input to output. A reconciliation system assumes that progression can be interrupted, delayed, partially completed, or invalidated by failure. It therefore builds explicit mechanisms to recover the intended outcome rather than merely continue from the last known step.
4. Event-Driven Reconciliation in Parjanya v2.0
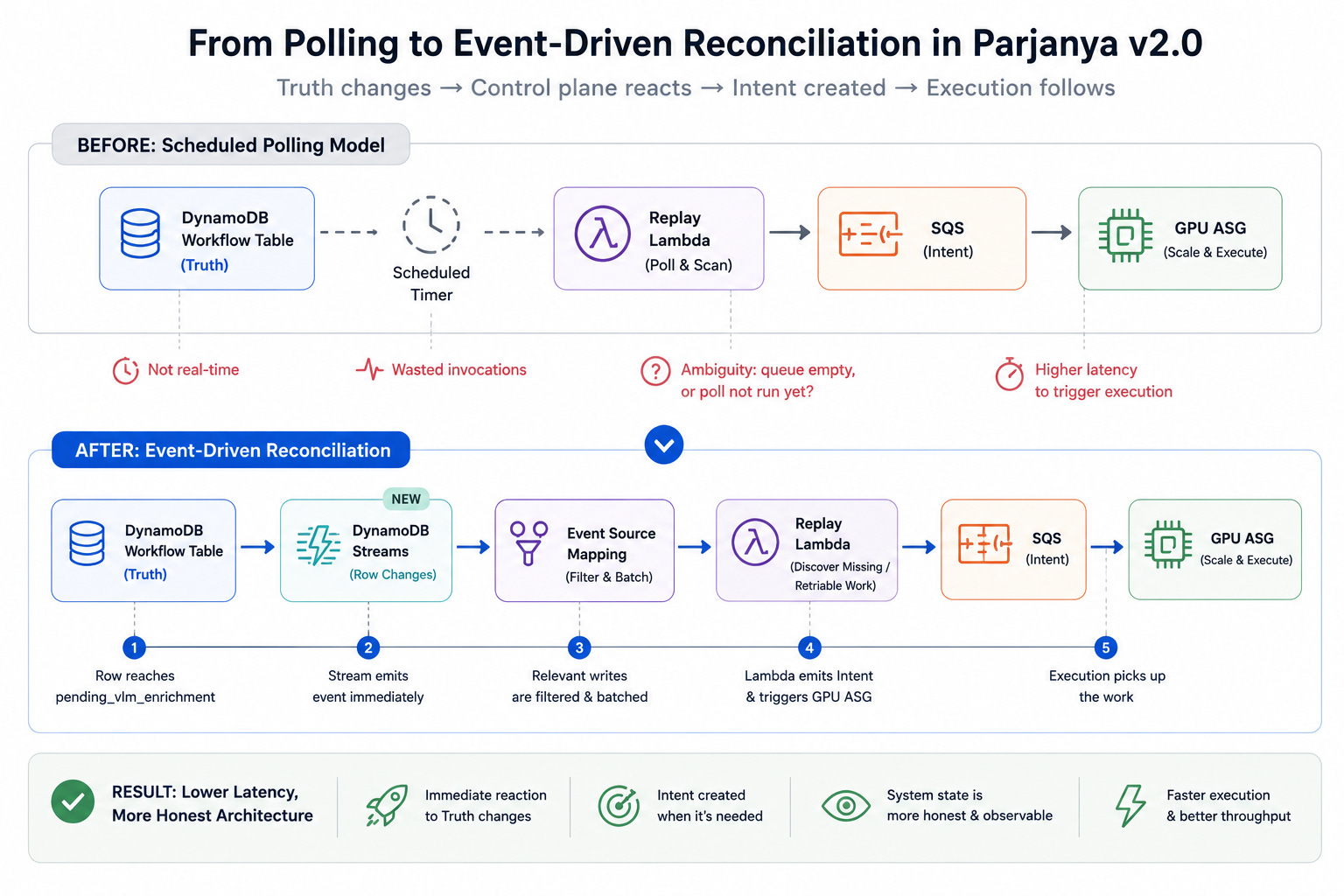
Parjanya initially used a scheduled polling model. A timer would wake the replay Lambda periodically, the Lambda would scan for pending work, and if appropriate it would emit SQS messages and trigger GPU autoscaling. This worked, but it introduced avoidable latency, wasted invocations, and operational ambiguity. The system could not react immediately when Truth changed, and operators had to reason about whether the queue was empty because the system had genuinely caught up or because the next poll had not yet occurred.
The move to DynamoDB Streams changed that architecture fundamentally. Now, when a workflow row reaches pending_vlm_enrichment, the stream emits an event immediately. An event source mapping filters for relevant writes, batches records briefly, and invokes the replay Lambda. The Lambda discovers missing or retriable work, emits Intent into SQS, and kicks the GPU ASG when necessary. This turns reconciliation from periodic discovery into event-driven reaction.
The result is a lower-latency, more honest architecture. Truth changes, the control plane notices, Intent is created, and Execution follows. The system no longer waits for a timer to rediscover what should already be known.
5. Parjanya v2.0 as a TBIE Case Study
Parjanya’s architecture maps neatly onto TBIE. S3 holds immutable uploads and preview artifacts. DynamoDB holds workflow state, curation metadata, and hashes. SQS holds replayable intent. Lambdas handle validation, replay, and orchestration. GPU workers perform inference and write enriched state back to DynamoDB. Autoscaling follows queue pressure and worker demand.
What makes the case study valuable is not the existence of those components, but the failure modes they exposed. Parjanya demonstrated that many production issues are really reconciliation issues in disguise. Some failures were caused by deleting intent too early. Others were caused by truth existing without intent. Some were caused by the wrong bucket being referenced correctly. Others were caused by the control plane being unable to read queue state. Still others came from stale image tags, missing model files, CORS misconfiguration, or API schema drift. TBIE made those failures legible.
5.1 Transient GPU failure should not destroy Intent
One of the earliest and most important incidents involved GPU workers deleting SQS messages before the retry window had been exhausted. A worker could encounter a temporary S3 download failure or an out-of-memory condition, write a failure state, and still remove the only replayable message. At that point, Truth said the work had failed, but Intent no longer existed and the system had no automatic path to try again.
TBIE made the problem obvious. Execution had destroyed Intent prematurely. The fix was to return explicit execution outcomes: retry, terminal_failure, or completed. A retry preserves the message and lets visibility timeout and receive count determine whether the work should be attempted again. A terminal failure writes durable failed truth and then deletes the message. Success writes final truth and deletes the message. That separation preserves replayability while still allowing durable failure when necessary.

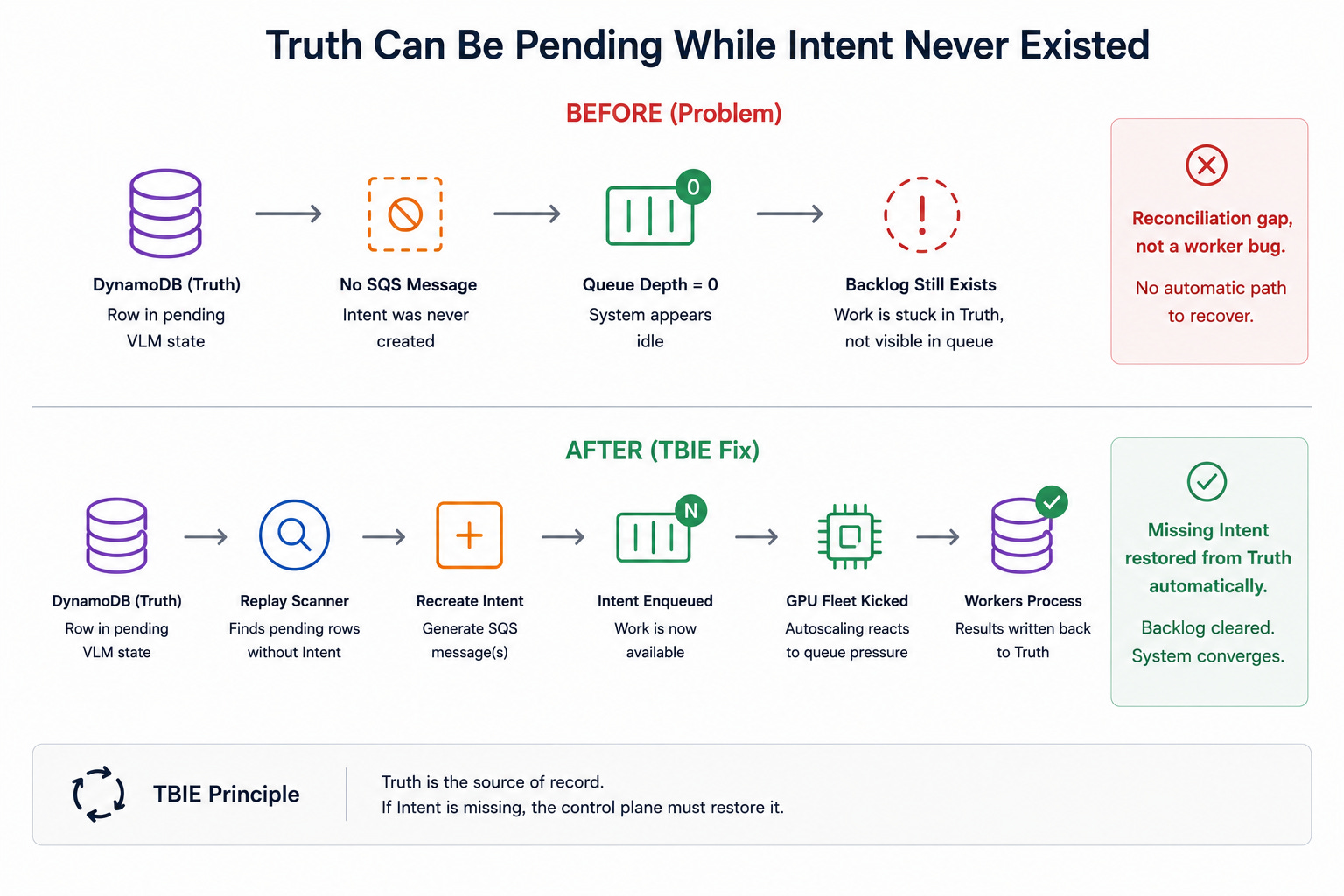
5.2 Truth can be pending while Intent never existed
Another recurring failure mode was the mirror image of the first. Rows in DynamoDB would remain in a pending VLM state, but no corresponding queue message had been created. Queue depth fell to zero and the system appeared idle, yet the backlog still existed in Truth.
This is a reconciliation gap, not a worker bug. The response was to introduce replay mechanisms that scan for pending rows without Intent, regenerate queue messages, and kick the GPU fleet when work is emitted. In other words, the platform needed a control plane that could restore missing Intent from Truth automatically.
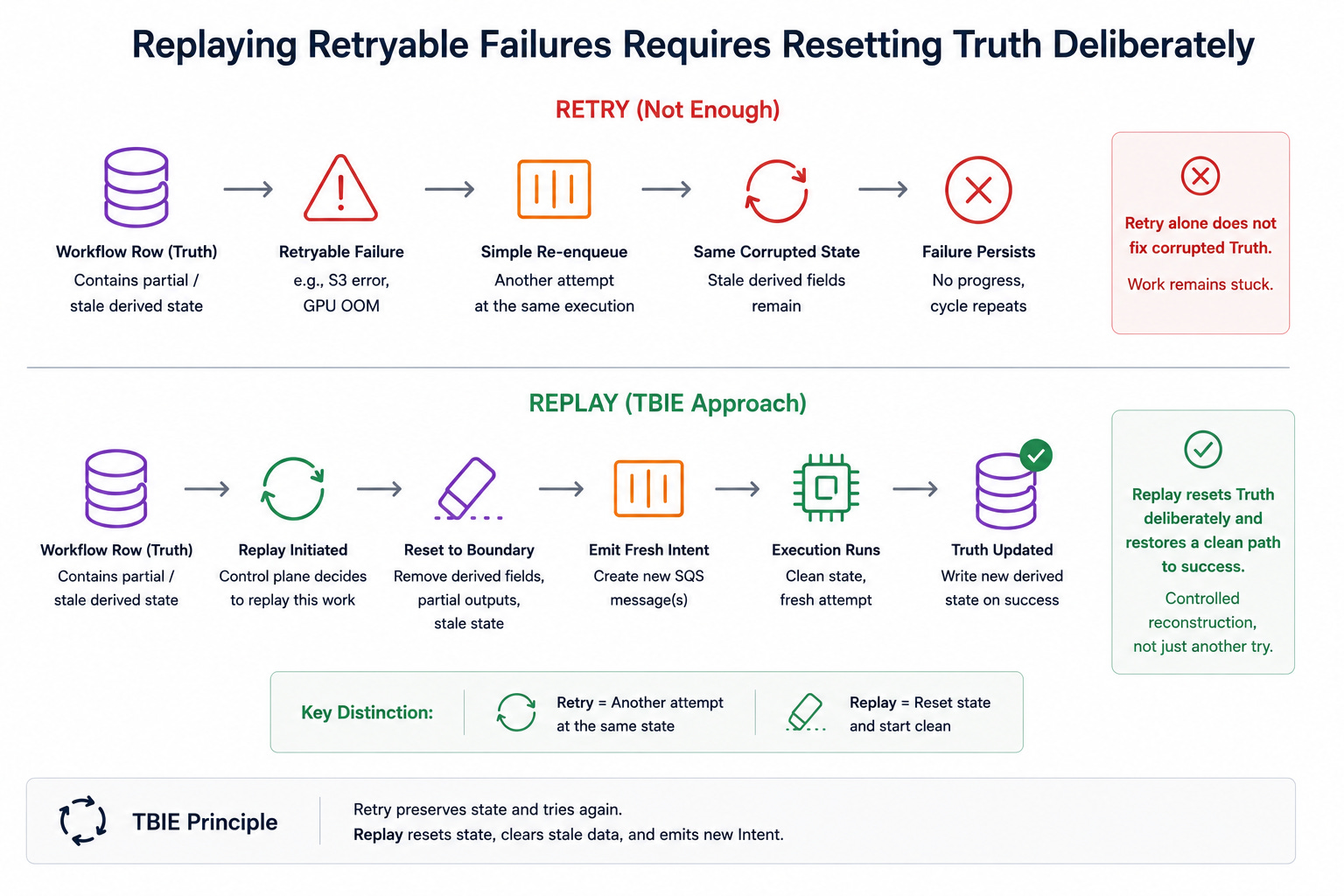
5.3 Replaying retryable failures requires resetting Truth deliberately
Not every failure should be treated as terminal. Some failures, such as S3 download errors or temporary GPU OOM events, are retryable if the underlying condition is corrected. But a simple re-enqueue is not enough when the workflow row itself still contains partial or stale derived fields.
TBIE clarifies the difference between retry and replay. A retry is another attempt at the same execution. A replay is a deliberate reset to a pre-execution boundary, removal of stale derived state, and emission of fresh Intent. This distinction matters because the second form is a controlled reconstruction of the workflow, not merely another attempt on top of corrupted state.
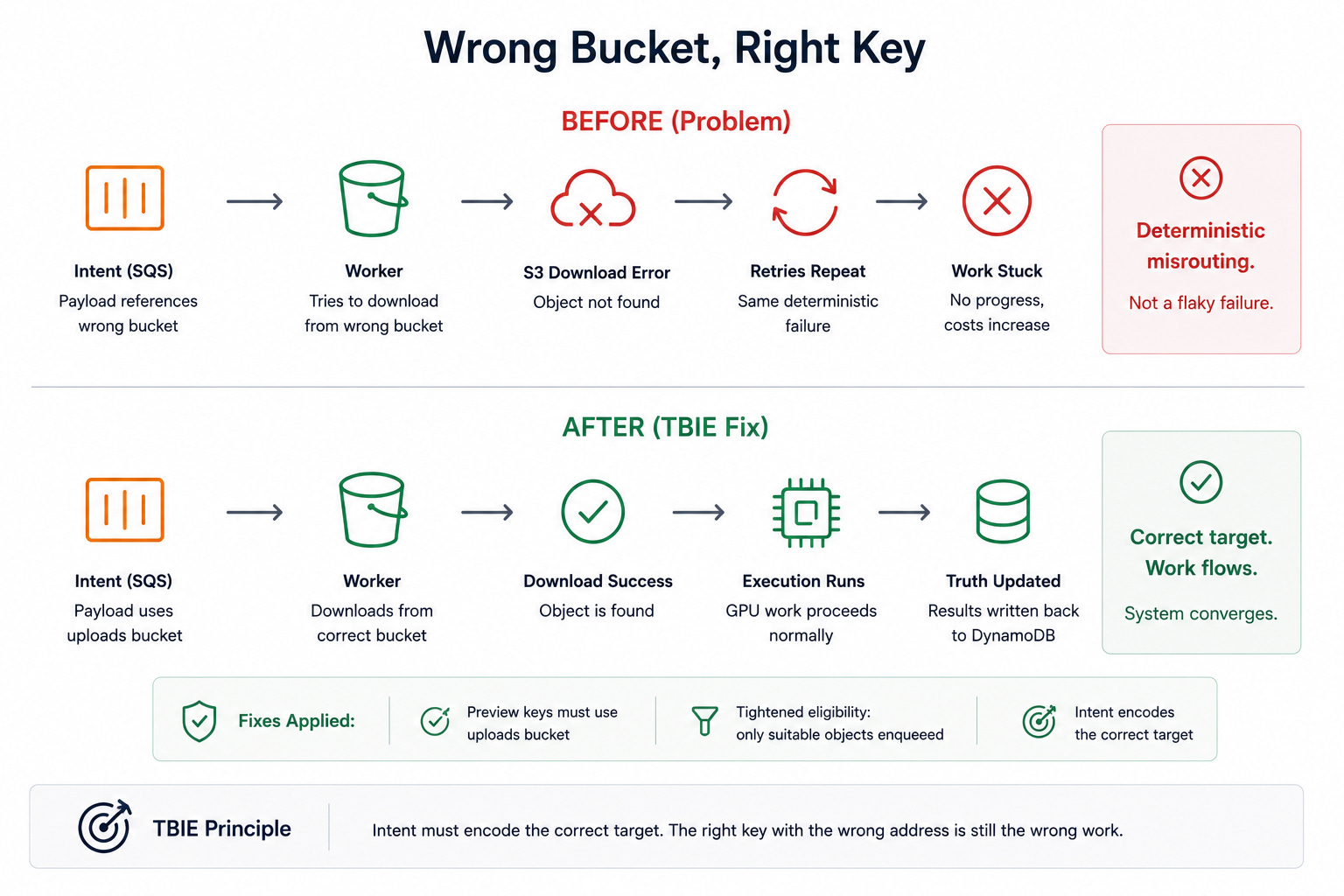
5.4 Wrong bucket, right key
One of the most instructive incidents involved an SQS payload that pointed to a valid preview key but the wrong bucket. The worker repeatedly failed with S3 download errors, even though the preview existed. The issue was not flaky execution. It was deterministic misrouting.
This is a classic distributed systems failure: the object key is correct, but the address is wrong. TBIE makes that failure visible because Intent is not just “some work exists.” Intent must encode the correct target. The fix was to force preview keys to use the uploads bucket as the source of truth and to tighten eligibility so only objects suitable for GPU work are enqueued.
5.5 Policy changes should be handled as replay, not patching
When the content policy changed to more strictly reject non-photographic content such as screenshots, banners, infographics, social cards, slides, illustrations, and mockups, the platform needed to reprocess historical images under the new rules. TBIE made the solution obvious: reset the affected Truth fields to a pre-VLM boundary, set the rows back to pending, and emit new Intent so GPU workers can re-grade under the revised policy.
This is one of the most powerful properties of replay-native systems. They allow policy evolution without manual data surgery. A change in judgment does not require a one-off correction script. It becomes a controlled reprocessing event with clear before-and-after semantics.

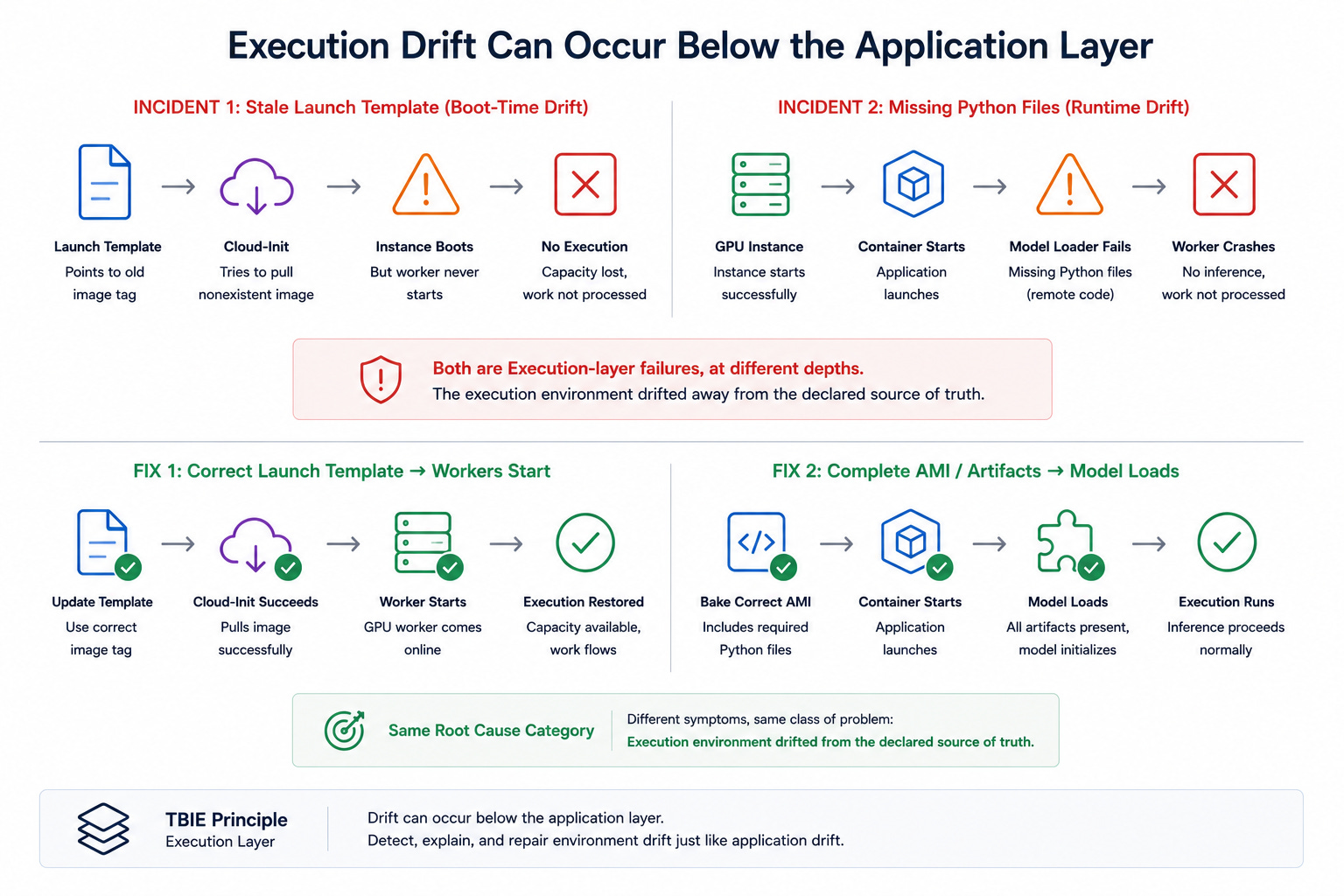
5.6 Execution drift can occur below the application layer
Parjanya also surfaced failures where the application code was correct but the execution environment was stale. One launch template continued to point to an old image tag. Cloud-init failed while pulling the nonexistent container image, and the GPU instance came up without ever starting the worker.
A separate incident involved an AMI missing the Python files required by a model that relied on remote code. The container started, but the model loader crashed because the local artifact was incomplete. These are both Execution-layer failures, but they occur at different depths: one at instance boot, the other at model runtime. TBIE is useful because it keeps both cases in the same conceptual category: the execution environment drifted away from the declared source of truth.
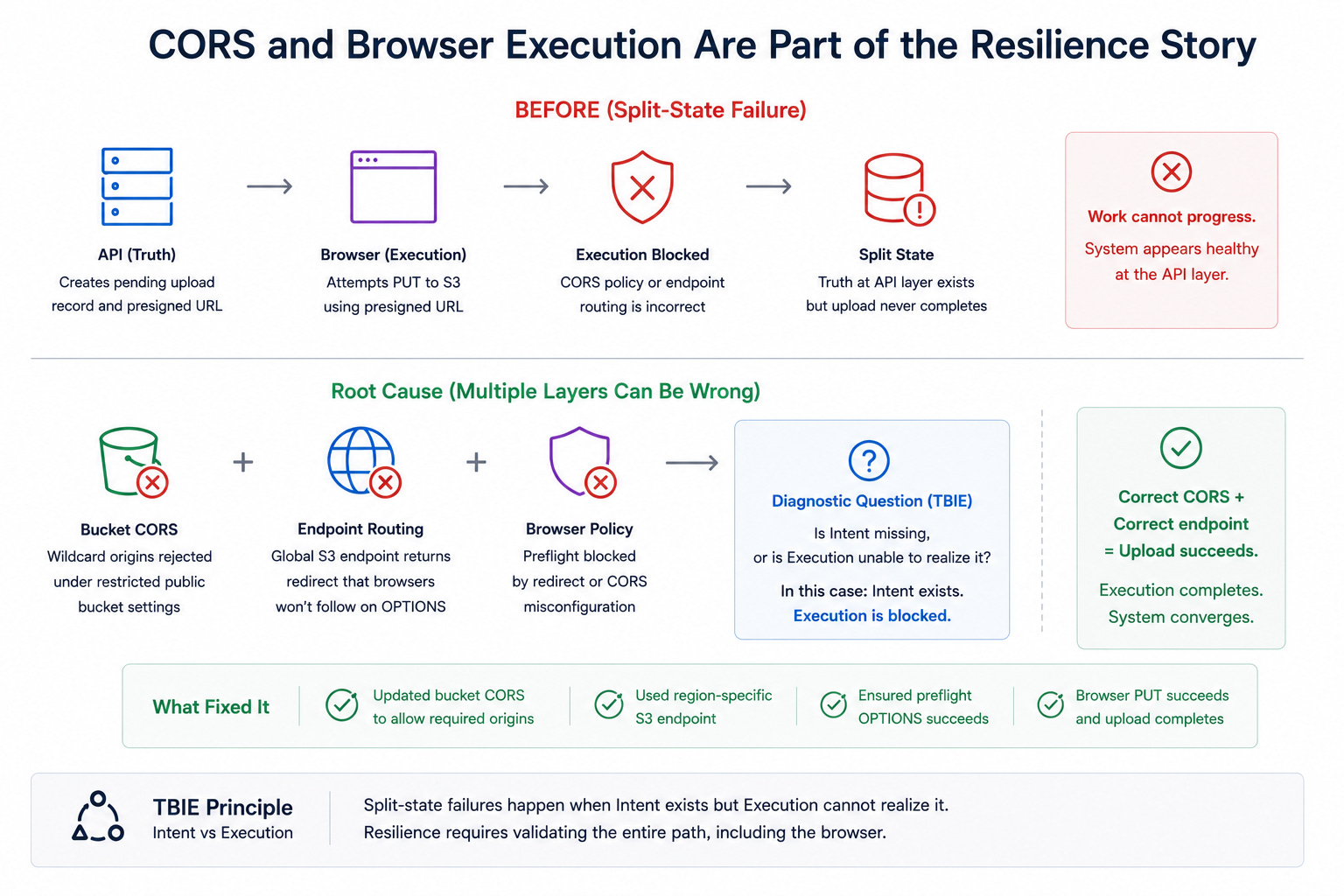
5.7 CORS and browser execution are part of the resilience story
The ingestion path introduced another class of split-state failure. The backend could write a pending upload record and generate a presigned URL, but the browser’s PUT could still fail because the bucket CORS policy or endpoint routing was incorrect. In that case, Truth at the API layer looked correct while Execution at the browser layer never completed.
Later investigations revealed that multiple independent layers could be wrong at once. A bucket might reject wildcard origins under restricted public bucket settings while the client simultaneously used a global S3 endpoint that returned a redirect browsers would not follow on OPTIONS preflight. TBIE helps here by forcing the diagnostic question: is Intent missing, or is Execution unable to realize it? In this case, Intent existed. Execution was blocked by infrastructure and configuration drift.
5.8 The control plane itself can fail silently
One of the most dangerous incidents in the system occurred when the replay Lambda lacked the permission it needed to read queue attributes. The function was still scheduled and invoked, but it could not inspect Belief and therefore crashed before it could emit Intent or kick the GPU ASG. From the outside, everything looked enabled. In reality, the control plane had gone blind.
This is a crucial TBIE lesson. The component that repairs work is itself a first-class reliability surface. If the control plane silently fails, then every other safety net becomes weaker. That is why control-plane observability must be stronger than ordinary worker observability.

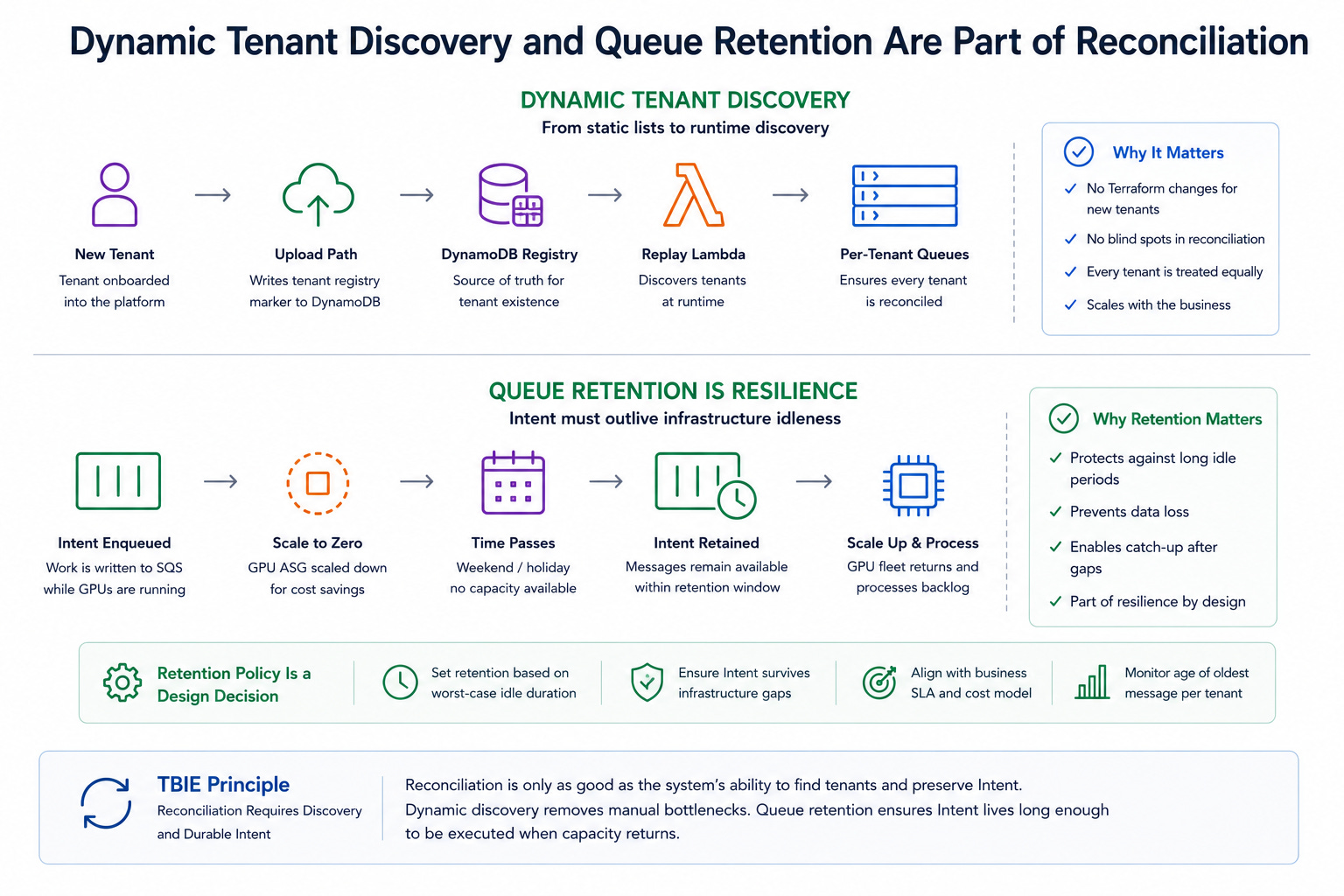
5.9 Dynamic tenant discovery and queue retention are part of reconciliation
As the platform grew, static tenant lists became a bottleneck. Reconciliation could not depend on manually editing Terraform every time a new tenant was onboarded. The control plane therefore moved toward dynamic tenant discovery from DynamoDB, with tenant registry markers written by the upload path and discovered by the replay Lambda at runtime.
Queue retention was another important operational detail. If the GPU fleet is scaled to zero for cost savings, Intent must survive long enough for work to be processed after a weekend or holiday gap. Retention policy is therefore part of resilience design, not a generic queue setting.
6. Operational Model and Runbook Thinking
TBIE becomes truly useful only when it changes how incidents are diagnosed.
By the time Parjanya matured into an event-driven reconciliation system, the debugging approach itself had changed. Operators no longer began by asking whether “the queue is healthy” or whether “the GPU workers are running.” Those signals mattered, but they were no longer treated as authoritative.
Instead, every investigation began with a simpler and much more precise question:
Is the system waiting because Intent is missing, or is Intent present but Execution cannot realize it?
That distinction dramatically narrowed the search space during incidents.
If Truth showed a growing backlog while Intent remained near zero, the issue was usually in reconciliation: replay Lambda failure, queue emission failure, stale tenant discovery, or control-plane blindness.
If Intent existed but Execution failed repeatedly, the problem shifted toward realization: bucket routing, IAM permissions, runtime drift, stale launch templates, model incompatibility, or endpoint mismatch.
The architecture became easier to reason about because TBIE transformed debugging from improvisation into classification.
7. Guardrails and Maintenance as Part of the Architecture
Parjanya’s history shows that resilient systems are built by converting incidents into guardrails. Transient worker failures should not destroy intent. Replay logic should reset truth cleanly before re-emitting work. Dependency drift should be prevented with lockfiles and build assertions. CORS origin drift should be rejected at plan time. Tenant discovery should be dynamic rather than manually maintained. Launch templates should refresh when image tags change. Model artifacts and container versions should be treated as a compatibility pair. API contracts and frontend types should not be allowed to drift silently. Queue retention should match the actual outage window, not an idealized one.
This is the practical meaning of reliability engineering. Incidents become permanent controls. The architecture evolves by accumulating constraints, validations, and replay paths that encode what the system has already learned.
8. Implications for AI Platform Design
TBIE generalizes beyond Parjanya. Any AI platform that spans storage, metadata, asynchronous work, GPU execution, and policy evolution can benefit from the same model. The key is to stop thinking of the system as a one-way pipeline and instead treat it as a reconciliation loop that continuously restores alignment between durable truth and intended work.
That shift affects architecture choices. Queues become journals of intent rather than temporary transport. Replay becomes a first-class product capability rather than an ops workaround. Autoscaling becomes a consequence of work existing, not a heuristic guess. Model packaging becomes part of execution correctness. Browser upload behavior becomes part of the end-to-end reliability model. And policy change becomes a replay event rather than a manual repair task.
When the System Hangs at 02:00 AM
At 02:00 AM, the queue may look empty while customers are still waiting for images to process. GPU instances may exist while no workers are actually running. A replay Lambda may still appear scheduled while silently crashing on every invocation. Dashboards may continue showing green infrastructure while the control plane itself has already gone blind.
This is where TBIE stopped being an architectural abstraction and became an operational model.
The first step was no longer restarting workers or increasing autoscaling limits. The first step became identifying which reconciliation boundary had failed.
The investigation usually began with Truth.
Was DynamoDB accumulating rows in pending_vlm_enrichment? If so, the platform still believed work should exist, regardless of what the queue appeared to show. Truth backlog became the first signal because Truth is the authoritative record of unfinished work.
The next step was Intent.
Did SQS actually contain replayable work items? A high Truth backlog combined with near-zero queue depth usually indicated a reconciliation failure rather than an execution failure. In those cases, the replay Lambda itself became suspect. Either the control plane had stopped emitting Intent, or it had lost the ability to discover the work that needed to exist.
That distinction mattered enormously because the operational response changed completely depending on the answer.
If Intent existed but the backlog still did not move, attention shifted toward Execution health. GPU worker logs became critical. Sometimes the workers were healthy but repeatedly failing with deterministic download errors caused by bucket routing drift. Sometimes GPU instances launched successfully while containers never started because a stale launch template pointed to a nonexistent image tag. In other cases, the instance booted correctly but the model loader crashed because required runtime artifacts were missing from the AMI.
One of the most revealing operational signals turned out to be complete silence.
An empty GPU log group was rarely a good sign. More often, it meant execution had failed before the application layer even started. Cloud-init failures, image pull failures, IAM denial during bootstrap, or launch-template drift frequently surfaced first as absence rather than explicit failure.
The replay Lambda introduced another category of silence.
If queue visibility remained unchanged while pending Truth continued growing, the control plane itself became the focus. One of the most dangerous incidents in the system occurred when the replay Lambda lost permission to read queue attributes. The function was still scheduled. It was still being invoked. But it crashed before emitting Intent or triggering autoscaling. From the outside, everything looked operational while reconciliation had effectively stopped.
That incident permanently changed the operational philosophy of the platform.
Worker failures became treated as recoverable noise.
Control-plane blindness became treated as a systemic risk.
Eventually, the debugging process itself evolved into a TBIE classification exercise:
Truth backlog revealed whether unfinished work existed.
Intent backlog revealed whether reconciliation was functioning.
Queue visibility revealed whether work was flowing.
GPU log silence revealed bootstrap or execution drift.
Replay Lambda silence revealed control-plane failure.
IAM checks validated whether orchestration still had authority to act.
Launch-template validation confirmed whether execution environments still matched declared infrastructure state.
The system stopped being debugged as “a pipeline.”
It began being debugged as a continuously reconciling distributed system.
That distinction changed how incidents were understood, how recovery was automated, and ultimately how the platform itself evolved.
9. Conclusion
Parjanya v2.0 demonstrates that resilient AI infrastructure depends on more than good models or fast workers. It depends on a clear model for distinguishing what is true, what is believed, what work is intended, and what execution can actually accomplish. TBIE provides that model.
The value of TBIE is not just conceptual. It changes how systems are built, how retries are designed, how control planes are monitored, how infrastructure drift is prevented, and how policy changes are reapplied. Most importantly, it turns production failure from a confusing mystery into a structured reconciliation problem.
That is why the right mental model for modern AI infrastructure is not merely “build a pipeline.” It is “build a system that can continuously reconcile truth and intent until intended work is actually realized.”
Appendix A. Maintenance Checklist

That checklist is not a substitute for architecture. It is how architecture remains trustworthy over time.