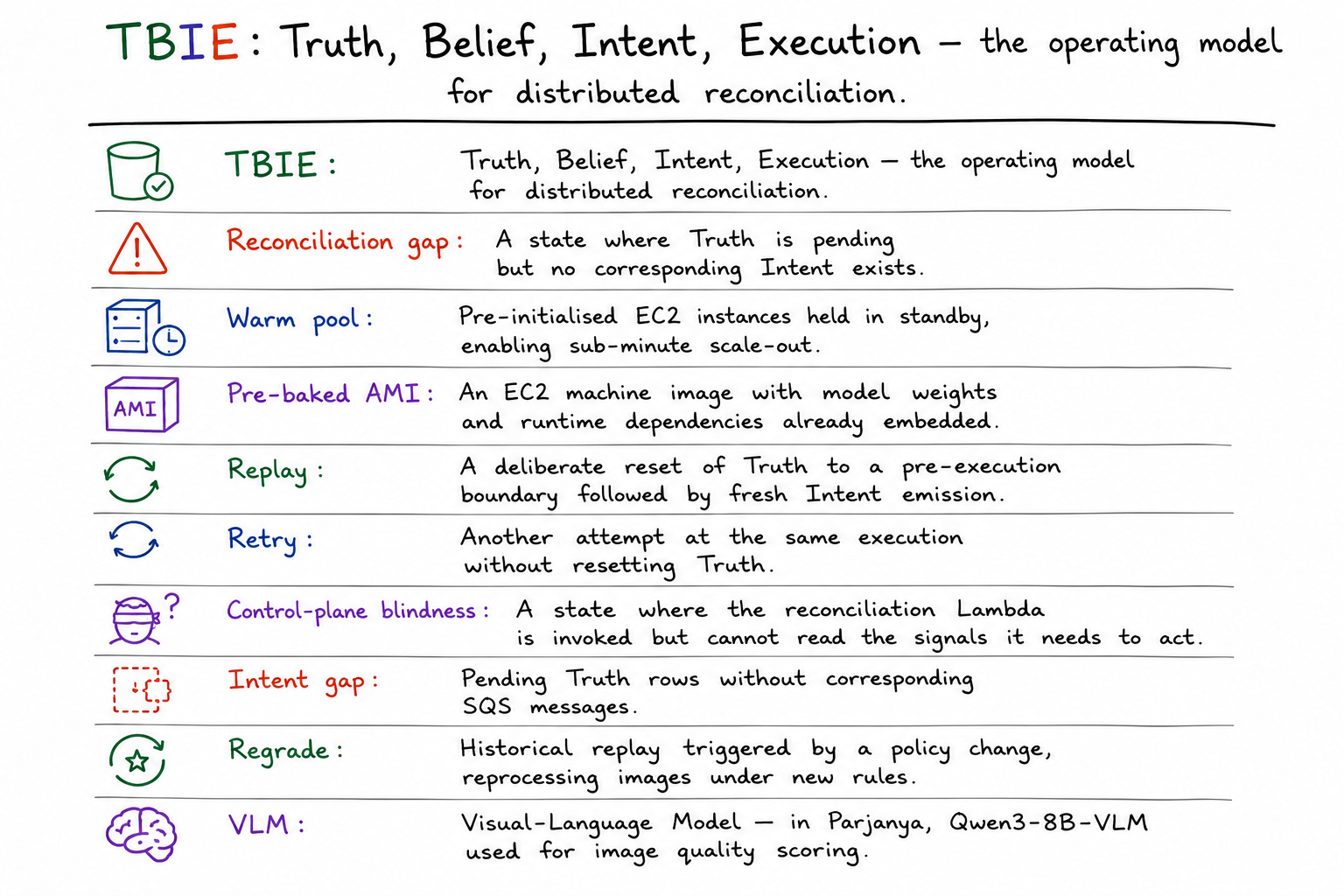
When SageMaker Wasn't the Problem
The Parjanya v2.0 case study: how AWS primitives replaced a managed ML platform through reconciliation, replay, and event-driven orchestration

As a follow-up to the original engineering note on Parjanya v2.0, this deep dive explores the architectural decisions, operational lessons, and production incidents that shaped the migration away from Amazon SageMaker toward a purpose-built AWS-native inference orchestration platform.
The original note documented how a combination of EC2 GPU warm pools, Auto Scaling Groups, SQS, EventBridge, DynamoDB Streams, and pre-baked GPU AMIs enabled Parjanya to eliminate SageMaker cold-start penalties, achieve scale-to-zero economics, and build a replay-native control plane capable of self-repair and reconciliation. Rather than treating GPU inference as a model-serving problem, the architecture reframed it as an orchestration and reconciliation problem, resulting in dramatically lower startup latency, parallel execution, improved replay safety, and reduced operational cost.
This document expands on that foundation by examining the complete system architecture, the TBIE (Truth, Belief, Intent, Execution) operating model, the move from polling to event-driven reconciliation, and the real production incidents that ultimately shaped the platform’s reliability model.
EXECUTIVE SUMMARY
Parjanya v2.0 is Phagyul AI’s image ingestion and GPU-based visual scoring, later evolved as curation platform by replacing score engine to rule engine.
From Score Engine to Rule Engine: Why I Rebuilt the Decision Layer

I did not set out to replace a scoring engine with a rule engine. I set out to make the system cheaper, easier to explain, and less fragile as I was not keen on moving to g5.xlarge or g6.xlarge due to prompt sizes increased and would be lot of churn in terms of architectural and infra changes, comes with re testing every functionality and the increase i…
Its nightly VLM inference pipeline was originally built on Amazon SageMaker. The pipeline processed photographer uploads using Qwen3-8B-VLM and worked — but it revealed a fundamental architectural mismatch over time. Wall-clock time regularly stretched to ~11 hours. Cold starts ate into every nightly window. Replay handling for failed enrichments grew fragile. Sequential execution prevented scale-out. And persistent managed-platform overhead stopped making financial sense for burst-only workloads.
The core insight that drove the migration was a reframing of the problem. The question was no longer
‘how do we run a model?’
It became:
‘how do we orchestrate burst-scale inference reliably, replay safely, and cost-efficiently?’
That reframing led to retiring SageMaker and rebuilding the pipeline entirely from native AWS primitives — EC2 GPU warm pools, Auto Scaling Groups, SQS-driven orchestration, EventBridge-triggered scale-out, and pre-baked GPU AMIs with Qwen3-8B-VLM weights embedded.
This is a detailed internal engineering deep dive into that migration. It covers the original architecture and its failure modes, the design decisions behind each new component, how TBIE (Truth, Belief, Intent, Execution) reconciliation patterns were applied to make the system replay-safe and operationally resilient, the specific production incidents encountered and how each shaped the architecture, and the guardrails now embedded to prevent regression.
Key outcome: the rebuilt system achieved near-zero or sub-minute startup latency, parallel GPU workers replacing sequential processing, event-driven replay handling, scale-to-demand orchestration, and drastically reduced idle GPU waste. More importantly, it became a system that could reason about and repair its own state — a reconciliation system, not just a pipeline.
BACKGROUND: WHAT IS PARJANYA V2.0?
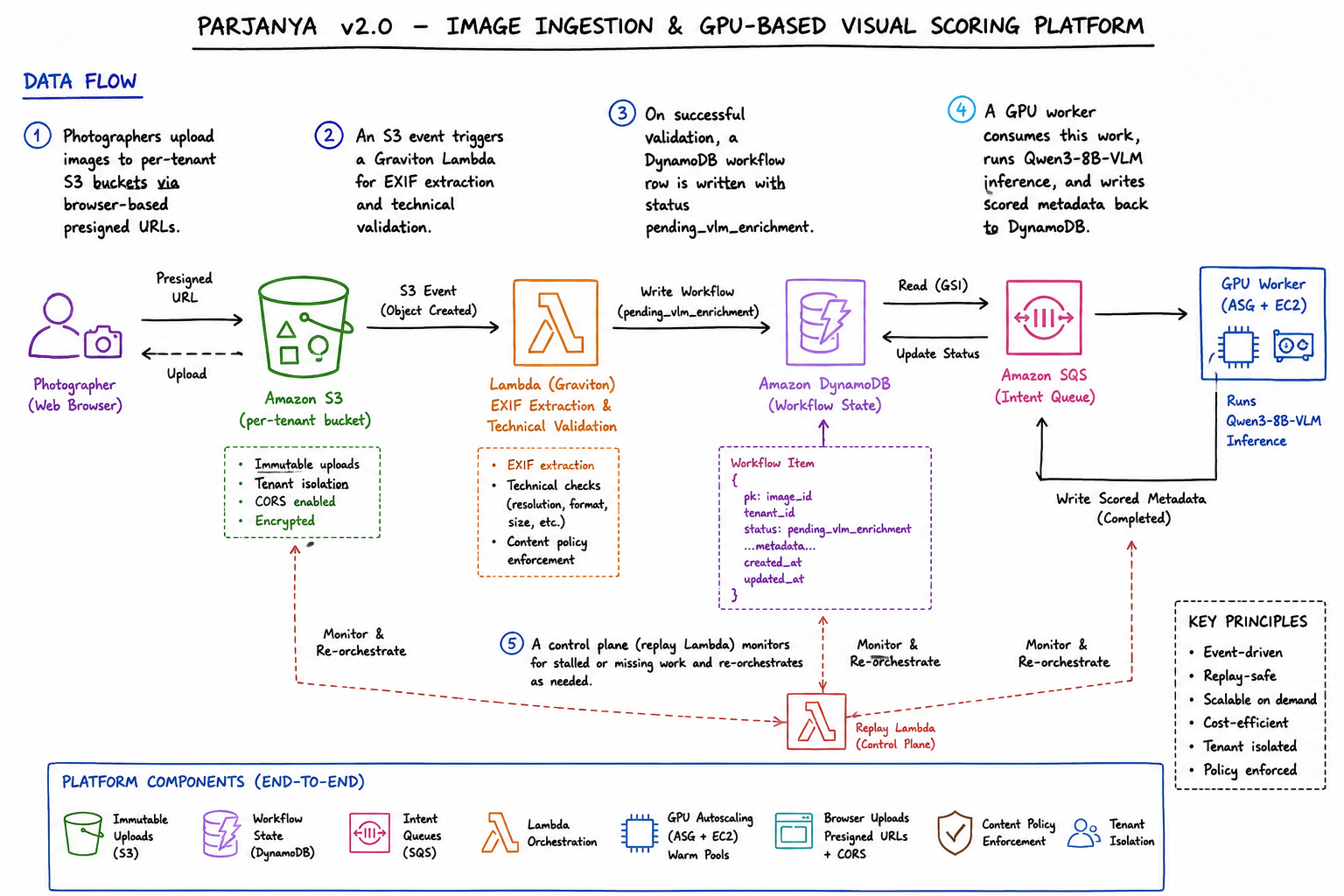
Parjanya v2.0 is the image ingestion and GPU-powered visual scoring platform at Phagyul AI Systems. Photographers upload raw images; the platform extracts technical metadata (EXIF, resolution, format), performs visual-language model inference to produce content quality scores, enforces content policy, and writes enriched metadata back to the workflow database.
The data flow is:
Photographers upload images to per-tenant S3 buckets via browser-based presigned URLs → An S3 event triggers a Graviton Lambda for EXIF extraction and technical validation.
On successful validation, a DynamoDB workflow row is written with status
pending_vlm_enrichment.A GPU worker consumes this work, runs Qwen3-8B-VLM inference, and writes scored metadata back(later recuration) to DynamoDB.
A control plane (replay Lambda, reconciliation loop) monitors for stalled or missing work and re-orchestrates as needed.
The platform spans immutable uploads (S3), workflow state (DynamoDB), intent queues (SQS), Lambda orchestration, GPU autoscaling (ASG + EC2), browser-side uploads with CORS policies, content policy enforcement, and tenant isolation.
THE ORIGINAL SAGEMAKER PIPELINE
Parjanya’s first VLM inference implementation used Amazon SageMaker as the compute platform. A nightly batch job was triggered on a schedule. SageMaker endpoints were provisioned, images were submitted for inference in sequence, results were collected, and endpoints were torn down.
The original system worked. It produced correct results. But it had structural problems that compounded as the platform grew:
Cold-start tax: Every nightly run incurred GPU cold starts before the first image could be processed.
Sequential execution: Image inference ran sequentially across the batch; there was no parallelism at the worker level.
Fragile replay: Failed enrichments required increasingly fragile custom replay logic layered on top of SageMaker’s job model.
Idle cost: The platform was billed for managed infrastructure overhead even during windows with no work to do.
Throughput ceiling: Wall-clock time regularly stretched to approximately 11 hours per nightly run.
THE ARCHITECTURAL REFRAMING
The decision to migrate was not triggered by a single catastrophic failure. It was triggered by a change in how the problem was understood.
“The problem was no longer ‘how do we run a model?’
The real problem was: ‘how do we orchestrate burst-scale inference reliably, replay safely, and cost efficiently?’”
Once the problem was stated that way, SageMaker was the wrong tool. SageMaker is an excellent managed platform for running models. It is not designed to be a burst-scale GPU orchestration layer with event-driven replay. Those properties had to be bolted on from outside, which is why the replay logic was fragile and why cold start latency was unavoidable.
Native AWS primitives offered a better fit for the actual problem: EC2 GPU instances could be pre-baked with model weights, Auto Scaling Groups could scale to demand rather than a fixed schedule, SQS provided durable, replayable intent, and EventBridge could trigger orchestration the moment new work appeared. The result is not a simpler system — it is a more intentional one.
THE NEW ARCHITECTURE: NATIVE AWS- PRIMITIVES
EC2 GPU WARM POOLS
Rather than provisioning GPU instances from scratch each time a job runs, Parjanya v2.0 uses EC2 warm pools attached to the Auto Scaling Group. Instances are pre-initialised and held in a stopped or standby state. When the ASG scales out, warm pool instances start in seconds rather than minutes, eliminating the cold start latency that dominated the original SageMaker pipeline.
Warm pool design note: instances in the warm pool must be pre-baked with model weights already on disk. Do not rely on model download during instance boot — download failures become silent launch failures. The AMI is the contract between infrastructure and runtime.
PRE-BAKED GPU AMIs WITH QWEN3-8B-VLM WEIGHTS
Each GPU AMI is built with the Qwen3-8B-VLM model weights, runtime dependencies, and worker application code baked in. The AMI is immutable. When a new model version or dependency is needed, a new AMI is built and the launch template is updated. This makes the execution environment reproducible and testable before deployment.
Key constraints on AMI design:
All model weights must be present at AMI build time — no remote download at boot.
Python environment, CUDA libraries, and worker scripts must be included in the AMI.
The launch template image tag and the AMI must be kept in sync; stale launch templates are a production risk (see Incident 6).
Container and model artifact versions are a compatibility pair — they must be validated together.
AUTO SCALING GROUPS (ASG)
An Auto Scaling Group manages the GPU worker fleet. The ASG is configured with a minimum of 0 instances (scale-to-zero for cost efficiency) and a maximum that reflects the burst capacity needed during active processing windows. Desired capacity is driven by queue depth rather than a schedule.
ASG configuration decisions:
Scale-out is triggered by the replay Lambda when SQS queue depth exceeds threshold.
Scale-in is time-based to prevent premature termination of in-flight workers.
Instance type selection balances GPU memory requirements (Qwen3-8B-VLM needs sufficient VRAM) against cost per inference.
Warm pool instances buffer the latency between a scale-out trigger and first inference.
SQS-DRIVEN ORCHESTRATION
SQS is the durable intent layer. Each message represents a single VLM inference job for one image. Messages are not ephemeral transport — they are the replayable journal of work that must happen. This is a TBIE design principle: intent must survive transient failure.
SQS configuration decisions:
Visibility timeout is set to exceed the maximum realistic inference time to prevent duplicate processing.
Queue retention is set to exceed the maximum expected outage window (e.g., weekend + holiday gap) so intent survives scale-to-zero periods.
A dead-letter queue captures messages that exceed the maximum receive count, enabling manual triage of terminal failures.
Message attributes carry routing metadata: tenant ID, image key, source bucket, expected output location.
Queue retention is not a generic operational setting. It is a resilience parameter. If the GPU fleet is at zero for 3 days, messages must still be present when the fleet wakes up. Set retention to match your worst-case outage window, not a default.
EVENTBRIDGE-TRIGGERED SCALE-OUT
Scale-out is event-driven via EventBridge and DynamoDB Streams. When a DynamoDB row reaches pending_vlm_enrichment, the stream emits an event. A stream processor filters and batches records, then invokes the replay Lambda. The replay Lambda evaluates queue state (Belief) against database state (Truth), emits SQS messages (Intent), and increases ASG desired capacity (Execution trigger).
This replaces a polling model where a scheduled timer would periodically scan for work. The event-driven approach gives lower latency, eliminates wasted invocations during quiet periods, and makes the system’s reaction to new work causally clear:
Truth changes → control plane notices → Intent is created → Execution follows.
REPLAY LAMBDA (CONTROL PLANE)
The replay Lambda is the reconciliation control plane. It is invoked by DynamoDB Streams and by periodic safety-net schedules. Its job is to compare Truth (DynamoDB workflow state) against Intent (SQS queue depth) and repair any divergence: emitting missing messages, resetting stale state, and triggering ASG scale-out when work is present.
The replay Lambda is a first-class reliability surface, not a background helper. If it fails silently, every other safety net becomes weaker. Its observability must be stronger than ordinary worker observability.
Monitor its error rate, execution duration, and whether it successfully reads queue attributes. A lambda that runs but cannot see queue state is functionally blind.
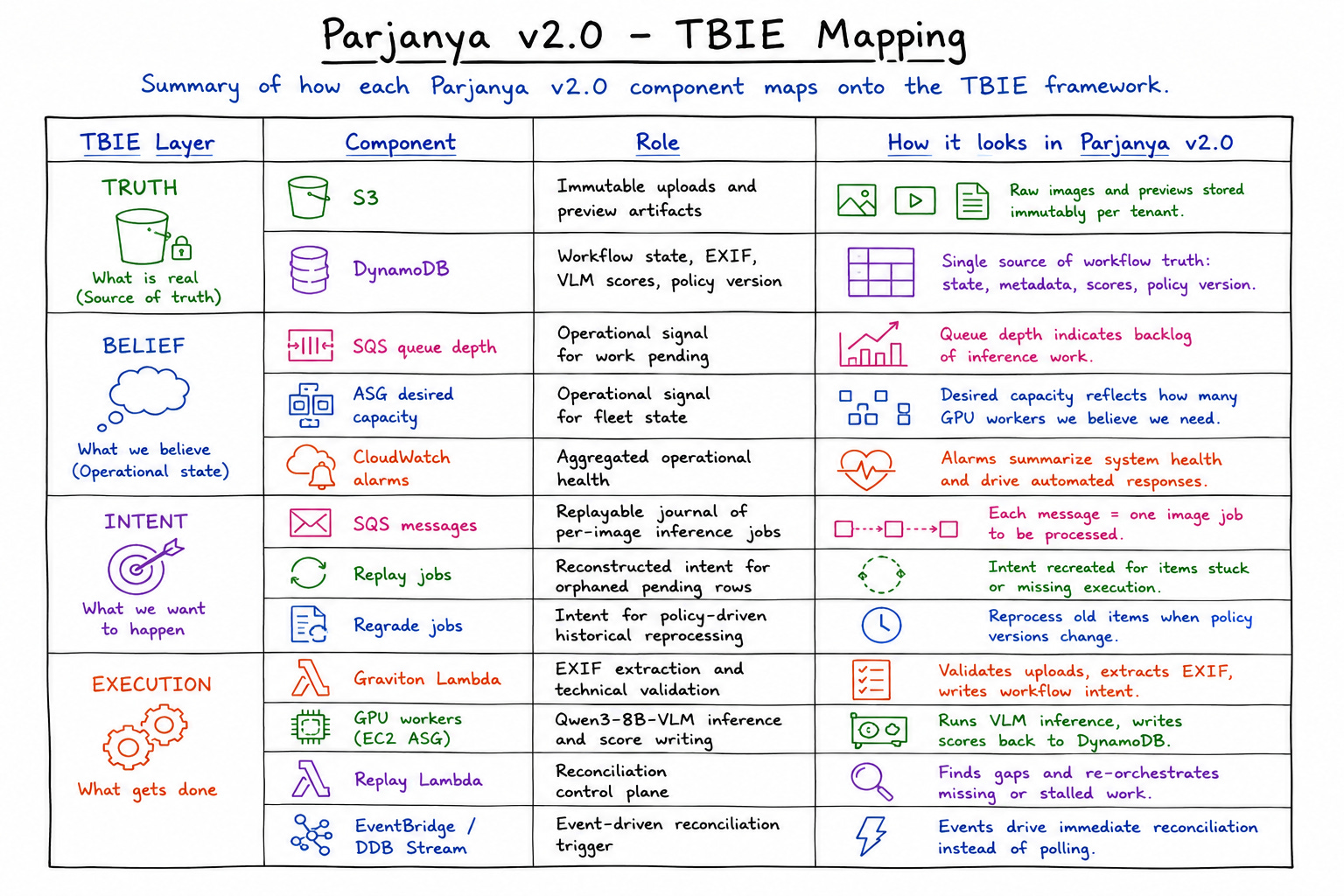
TBIE: TRUTH, BELIEF, INTENT, EXECUTION
TBIE is the operating model used to design, debug, and evolve Parjanya v2.0. It decomposes a distributed system into four conceptually distinct layers. The model is most valuable as a diagnostic tool: when the system behaves unexpectedly, TBIE provides a structured vocabulary for identifying which layer has diverged.
TRUTH
Truth is the durable, authoritative record of what is actually true. It must survive worker restarts, deploys, transient outages, and infrastructure drift.
In Parjanya v2.0, Truth lives in:
S3 — immutable image uploads and preview artifacts. If an object is in S3, it exists.
DynamoDB — workflow rows recording status, EXIF metadata, VLM scores, curation state, and hashes.
Derived committed state — VLM output written durably after successful inference.
Truth answers questions like:
What objects exist?
What stage is this image in?
What has been computed?
What is the authoritative record for this batch?
BELIEF
Belief is the operational view of reality. It is derived from Truth and current signals, but it may lag, be partial, or be noisy. Belief is what operators see first — but it must never be confused with source-of-record Truth.
In Parjanya, Belief includes:
SQS queue depth and in-flight message counts.
ASG desired capacity, running instance count, and warm pool state.
Worker health signals and CloudWatch alarms.
GPU availability and instance lifecycle state.
A healthy Belief is not the same as a healthy system. The queue can appear empty while Truth still holds a large pending backlog. That gap is a reconciliation failure, not an idle system.
INTENT
Intent is the durable record of work that has been requested. It is the replayable journal of ‘please do this work.’
The critical property of Intent is replayability: if Intent can be lost too early, transient failures become permanent failures requiring manual rescue.
In Parjanya, Intent is:
SQS messages — each representing a single VLM inference job.
Replay jobs — reconstructed Intent emitted for rows that had pending Truth without corresponding queue messages.
Regrade jobs — Intent emitted for historical reprocessing after policy changes.
EXECUTION
Execution is the stateless work that turns Intent into side effects and updated Truth. Execution is where work happens, but in a resilient system it must never be allowed to erase the record of what was supposed to happen.
In Parjanya, Execution includes:
Graviton Lambdas for EXIF extraction and technical validation.
GPU workers running Qwen3-8B-VLM inference and writing scored results to DynamoDB.
Replay Lambda emitting Intent and triggering ASG scale-out.
ASG and EC2 actions that instantiate the worker fleet.
TBIE AS A DIAGNOSTIC MODEL
The power of TBIE is operational. Once internalised, it changes the first question asked during any incident. The question is no longer ‘is the queue healthy?’ or ‘are the GPU workers running?’ Those are Belief signals. The real question is:
Is the system waiting because Intent is missing — or because Intent is present but Execution cannot realise it?
That single question narrows the search space dramatically and prevents wasted time on the wrong layer.
EVENT-DRIVEN RECONCILIATION
Parjanya initially used a scheduled polling model. A timer would wake the replay Lambda periodically. The Lambda would scan for pending work and, if appropriate, emit SQS messages and trigger GPU autoscaling. This worked but introduced avoidable latency, wasted invocations, and operational ambiguity.
The move to DynamoDB Streams changed the architecture fundamentally. Now, when a workflow row reaches pending_vlm_enrichment, the stream emits an event immediately. An event source mapping filters for relevant writes, batches records briefly, and invokes the replay Lambda. The Lambda discovers missing or retriable work, emits Intent into SQS, and kicks the GPU ASG when necessary.
The net effect:
Reconciliation latency dropped from O(poll_interval) to O(stream_propagation) — typically seconds.
Wasted Lambda invocations during idle periods eliminated.
Causal chain made explicit: Truth changes → stream emits → Lambda reacts → Intent created → Execution follows.
Operators can reason about system state without wondering ‘has the next poll happened yet?’
A reconciliation system does not rely on humans noticing a stalled queue and manually fixing it.
It detects, explains, and repairs the divergence between Truth and Intent on its own. Event-driven streaming is what makes that self-repair fast enough to be useful in production.
PRODUCTION FAILURE MODES & LESSONS
The following incidents occurred during the development and operation of Parjanya v2.0. Each is documented here not as a post-mortem but as a design lesson — how the failure shaped the architecture, and what guardrail was added as a result. TBIE is used throughout as the diagnostic lens.
Incident 1: Transient GPU Failure Destroying Intent
GPU workers were deleting SQS messages before the retry window had been exhausted. A worker could encounter a temporary S3 download failure or an OOM condition, write a failure status to DynamoDB, and still delete the queue message. At that point, Truth said the work had failed, but Intent no longer existed — the system had no automatic path to retry.
TBIE diagnosis: Execution destroyed Intent prematurely.
Resolution:
Workers now return explicit outcome signals: retry, terminal_failure, or completed.
retry: preserve the message. Visibility timeout and receive count govern re-attempts.
terminal_failure: write durable failed Truth, then delete the message.
completed: write final Truth, then delete the message.
That separation preserves replayability while still allowing durable failure when necessary. The message deletion decision became a function of execution outcome, not a side effect of worker exit.
Worker outcome protocol
if outcome == ‘retry’:
# Do NOT delete. Let visibility timeout expire.
return # SQS will re-deliver
elif outcome == ‘terminal_failure’:
write_durable_failure(db, image_id)
sqs.delete_message(receipt_handle)
elif outcome == ‘completed’:
write_enriched_truth(db, image_id, scores)
sqs.delete_message(receipt_handle)
Incident 2: Pending Truth Without Intent (Reconciliation Gap)
DynamoDB rows remained in pending_vlm_enrichment status, but no corresponding SQS messages existed. Queue depth showed zero. The system appeared idle. The backlog still existed in Truth but was invisible to Execution.
TBIE diagnosis: Truth was pending while Intent never existed. Classic reconciliation gap.
Resolution:
The replay Lambda now scans for pending rows without corresponding queue messages.
For each orphaned pending row, it regenerates a queue message and kicks the GPU ASG.
DynamoDB Streams ensure this scan is triggered promptly rather than waiting for a polling cycle.
The key insight: this is not a worker bug. Workers cannot fix work that was never queued. The control plane must own the responsibility of keeping Truth and Intent aligned.
Incident 3: Retry vs. Replay Distinction
Some failures — S3 download errors, temporary GPU OOM — are retryable once the underlying condition is fixed. But simply re-enqueueing the message is insufficient when the workflow row contains partial or stale derived fields from the failed attempt.
TBIE clarification:
a retry is another attempt at the same execution. A replay is a deliberate reset to a pre-execution boundary, removal of stale derived state, and emission of fresh Intent.
Resolution:
Retry: re-attempt on the existing message, preserving current workflow state.
Replay: reset the DynamoDB row to a clean pre-VLM boundary (clear stale score fields, VLM status, partial outputs), then emit a fresh SQS message.
Replay is a controlled reconstruction, not just another attempt on top of corrupted state. The distinction prevents accumulating corrupted derived fields across multiple failed attempts.
Incident 4: Wrong Bucket, Right Key (Deterministic Misrouting)
An SQS payload pointed to a valid preview key but in the wrong bucket. The worker repeatedly failed with S3 download errors even though the file existed — just not at that address. This was deterministic misrouting, not flaky execution.
TBIE diagnosis: Intent encoded the wrong target. Not an Execution failure — an Intent construction failure.
Resolution:
Preview keys now canonically use the uploads bucket as the authoritative source.
Intent construction validates bucket routing before emitting to SQS.
Eligibility checks were tightened: only objects confirmed present in the correct bucket are enqueued.
The lesson generalises: Intent must encode the correct target, not just some valid key. A message that is ‘almost correct’ will fail deterministically and indefinitely until the Intent itself is repaired.
Incident 5: Policy Change Requiring Historical Replay
Content policy was updated to more strictly reject non-photographic content: screenshots, banners, infographics, social cards, slides, illustrations, and mockups. Historical images scored under the old policy needed to be re-evaluated.
TBIE framing: policy change = controlled replay, not a patching exercise.
Resolution:
Affected rows were identified by policy version marker in DynamoDB.
Each affected row was reset to a pre-VLM boundary: stale score fields cleared, VLM status reset to pending.
Fresh Intent was emitted into SQS so GPU workers re-scored under the new policy.
This is one of the most powerful properties of a replay-native system: policy evolution does not require one-off correction scripts. It becomes a controlled reprocessing event with clear before-and-after semantics. The same replay machinery used for failure recovery also handles deliberate re-evaluation.
Incident 6: Execution Drift Below the Application Layer
Two distinct incidents exposed failures where application code was correct but the execution environment was stale.
6a: Stale Launch Template (Image Tag)
A launch template continued to reference an old image tag that no longer existed. Cloud-init failed when pulling the nonexistent container image, and the GPU instance came up without ever starting the worker. The worker log group was empty — the application layer never ran.
Complete silence in the GPU log group is a critical signal. It usually means execution failed before the application layer started: image pull failure, IAM denial during bootstrap, or cloud-init crash.
6b: Incomplete AMI (Missing Model Artifacts)
A separate incident involved an AMI that was missing the Python files required by Qwen3-8B-VLM (a model that relies on remote code). The container started successfully, but the model loader crashed because local artifacts were incomplete.
Resolution — both incidents:
Launch templates now include version assertions checked at deployment time.
AMI build pipelines validate the presence and integrity of all model artifacts before publishing.Container version and model artifact version are treated as a compatibility pair, validated together.
Deployment tooling refreshes launch templates automatically when image tags change.
Incident 7: CORS and Browser Upload Split-State Failure
The backend could write a pending upload record and generate a presigned URL, but the browser’s PUT could fail because of CORS misconfiguration. In that case, Truth at the API layer looked correct while Execution at the browser layer never completed.
Investigation revealed multiple independent configuration failures could co-exist: a bucket rejecting wildcard origins under restricted public bucket settings, while the client simultaneously used a global S3 endpoint that returned redirects that browsers would not follow on OPTIONS preflight.
TBIE diagnosis:
Intent existed (presigned URL generated, pending row written). Execution was blocked by infrastructure configuration drift. Two independent misconfiguration layers were both wrong simultaneously.
Resolution:
CORS policies are version-controlled and validated in CI before deployment.
Bucket CORS and public access settings are treated as a matched pair, not configured independently.
Upload path includes client-side detection of presigned URL PUT failure with structured error reporting.
Pending rows created without a completed upload are detected by the replay Lambda and age-gated before re-emission.
Incident 8: Control Plane Blindness (Replay Lambda IAM Failure)
The replay Lambda lacked permission to read SQS queue attributes. The function continued to be scheduled and invoked, but it crashed before it could inspect Belief (queue depth) or emit Intent. From the outside, everything appeared enabled. In reality, the control plane had gone blind.
This is the most dangerous failure mode in the system. A silently failing control plane means every other safety net weakens simultaneously. Worker failures that should self-repair accumulate without rescue. Operators see green infrastructure dashboards while reconciliation has effectively stopped.
Resolution:
The replay Lambda’s IAM policy now explicitly grants
sqs:GetQueueAttributes,sqs:GetQueueUrl, andsqs:SendMessage.IAM policy drift is checked in deployment assertions — the Lambda will not deploy if required permissions are absent.
The Lambda now emits a structured heartbeat metric on every successful invocation, including after inspecting queue state.
Alarm on absence of heartbeat metric: silence means the control plane has likely failed.
The operational philosophy shift from this incident: worker failures are recoverable noise. Control-plane blindness is a systemic risk. Observability on the control plane must be stronger than on individual workers.
Incident 9: Dynamic Tenant Discovery and Queue Retention
As the platform grew, static tenant lists became a bottleneck. Reconciliation could not depend on manually editing infrastructure configuration every time a new tenant was onboarded. Additionally, when the GPU fleet was scaled to zero for cost savings, queue retention was set too short — messages expired before the fleet woke up.
Resolution:
The control plane moved to dynamic tenant discovery from DynamoDB. Tenant registry markers are written by the upload path and discovered by the replay Lambda at runtime.
Queue retention policy was extended to match the maximum expected outage window, not an idealised constant.
New tenant onboarding now automatically creates the required DynamoDB registry marker without manual infrastructure changes.
OPERATIONAL MODEL AND RUNBOOK THINKING
By the time Parjanya matured into an event-driven reconciliation system, the debugging approach itself had changed. The starting question is no longer ‘is the queue healthy?’ or ‘are GPU workers running?’ — those are Belief signals. Every incident investigation now begins with a TBIE classification:
THE DIAGNOSTIC SEQUENCE
Step 1: Check Truth
Is DynamoDB accumulating rows in pending_vlm_enrichment? If so, the platform believes unfinished work exists, regardless of what the queue shows. A growing Truth backlog is the authoritative signal that the system is behind.
Step 2: Check Intent
Does SQS contain replayable work items? High Truth backlog + near-zero queue depth = reconciliation failure, not execution failure. The replay Lambda itself becomes suspect. Either it stopped emitting Intent, or it lost the ability to discover the work.
Step 3: Check Execution
If Intent exists but the backlog still does not move, shift to Execution health. GPU worker logs become critical. Check for:
Deterministic S3 download errors (wrong bucket routing — see Incident 4).
Repeated OOM crashes (model too large for instance type).Complete log group silence (execution failed before the application layer — check cloud-init).
Stale launch template (image tag no longer exists — check ASG launch configuration).
Step 4: Check the Control Plane
If queue visibility is unchanged while pending Truth continues growing, the replay Lambda itself is the focus. Check: Is it being invoked? Is it completing successfully? Can it read sqs:GetQueueAttributes? Is it emitting its heartbeat metric?
Operational summary of diagnostic signals:
Truth backlog growing → unfinished work exists
Intent near zero despite Truth backlog → reconciliation failure
Intent present but Execution failing → runtime or routing failure
GPU log silence → bootstrap failure (cloud-init, image pull, IAM at boot)
Replay Lambda silence → control-plane failure (IAM, crash, permission gap)
No heartbeat metric → control plane has gone blind
INCIDENT RESPONSE DECISION TREE
At 02:00 AM, when the queue looks empty but customers are waiting:
Check Truth: pull DynamoDB pending count. If non-zero, the system is behind regardless of queue state.
Check replay Lambda logs: has it run in the last cycle? Did it complete? Did it emit messages?
Check SQS: are messages present? If Truth is high and SQS is low, replay Lambda is suspect.
Check ASG desired capacity: did the Lambda set it correctly? Check CloudWatch ASG activity log.
Check GPU worker logs: any entries? Silence means boot failure. Errors usually indicate routing or model issues.
Check IAM: can the Lambda call sqs:GetQueueAttributes? Can the worker read the correct S3 bucket?
Check launch template: does the image tag still exist? Pull the AMI manifest.
OUTCOMES
The migration from SageMaker to native AWS primitives, combined with TBIE reconciliation, changed both the cost profile and the operational character of the pipeline.
OPERATIONAL IMPROVEMENTS
Latency: Startup latency: near-zero or sub-minute (down from 20–40 minutes cold start on SageMaker).
Parallelism: Workers process images in parallel rather than sequentially — throughput scales with fleet size.
Throughput: Wall-clock time reduced dramatically from the ~11 hour nightly baseline.
Replay: Event-driven replay handles failures automatically without manual intervention for most failure classes.
Cost: Scale-to-zero when no work is present; burst capacity available within seconds via warm pools.
ARCHITECTURAL IMPROVEMENTS
The system can repair its own state: Truth without Intent is detected and corrected by the control plane.
Policy changes are handled as replay events — no custom migration scripts needed.
Tenant onboarding is dynamic — no infrastructure changes required per tenant.
Execution environments are immutable and reproducible via pre-baked AMIs.
Control plane observability now triggers independent alerting paths from worker failures.
THE BROADER LESSON
Not every AI workload needs a managed ML platform. Sometimes the real engineering challenge sits in orchestration, reconciliation, and operational resilience — not in model serving. When the problem is ‘how do we run a model?’, SageMaker is the right answer. When the problem is ‘how do we orchestrate burst-scale inference reliably, replay safely, and cost efficiently?’, native primitives and a clear reconciliation model are the right answer.
GUARDRAILS, MAINTENANCE, AND OPERATIONAL CHECKLIST
Parjanya’s reliability is not a property of its initial design. It is the accumulated result of incidents converted into permanent controls. The following checklist encodes what the system has already learned.
INTENT PRESERVATION
Workers never delete SQS messages unless the outcome is terminal_failure or completed.
Visibility timeout exceeds maximum realistic inference time.
Queue retention exceeds maximum expected outage window.
Dead-letter queue is monitored and reviewed regularly.
EXECUTION ENVIRONMENT INTEGRITY
Launch template image tags are validated against existing AMIs at deployment time.
AMI build pipelines assert presence of all model artifacts before publishing.
Container version and model artifact version are validated as a compatibility pair.
Launch templates are refreshed automatically when image tags change.
Python lockfiles are used to prevent dependency drift inside worker environments.
CONTROL PLANE HEALTH
Replay Lambda emits a structured heartbeat metric on every successful execution.
Alarm fires if heartbeat is absent for more than one poll cycle.
IAM policy grants for the Lambda are validated in deployment assertions.
Lambda error rate and duration are independently alarmed.
Control-plane CloudWatch logs are retained and searchable for incident forensics.
RECONCILIATION INTEGRITY
Truth backlog (pending DynamoDB rows) is monitored as a primary SLI.
Intent gap (pending Truth with no corresponding queue message) is checked by the Lambda on each invocation.
Replay logic resets Truth cleanly to a pre-execution boundary before re-emitting Intent.
Tenant discovery is dynamic — no manual configuration changes needed on onboarding.
Queue retention policy change requires explicit engineering review.
INFRASTRUCTURE DRIFT PREVENTION
CORS policies are version-controlled and validated in CI.
Bucket CORS and public access settings are configured as a matched pair.
API schema and frontend types have drift detection in CI.
S3 bucket routing is validated at Intent construction time, not only at worker download time.
POLICY AND REGRADE
Content policy version is stored per image in DynamoDB.
Policy changes trigger replay jobs for images scored under previous policy versions.
Regrade jobs use the same replay machinery as failure recovery — no custom tooling.
IMPLICATIONS FOR AI PLATFORM DESIGN
TBIE generalises beyond Parjanya. Any AI platform that spans storage, metadata, asynchronous work, GPU execution, and policy evolution benefits from the same model. The key is to stop thinking of the system as a one-way pipeline and treat it as a reconciliation loop that continuously restores alignment between durable truth and intended work.
That shift changes concrete architecture choices:
Queues: Queues become journals of intent rather than temporary transport.
Replay: Replay becomes a first-class product capability, not an ops workaround.
Autoscaling: Autoscaling becomes a consequence of work existing, not a heuristic guess.
Model packaging: Model packaging becomes part of execution correctness, not just deployment.
Browser uploads: Browser upload behaviour becomes part of the end-to-end reliability model.
Policy change: Policy change becomes a replay event rather than a manual repair task.
From Pipeline to Platform

In my previous post few weeks ago, I introduced TBIE — Truth, Belief, Intent and Execution — as a framework for reasoning about resilient distributed systems.
The right mental model for modern AI infrastructure is not ‘build a pipeline.’ It is ‘build a system that can continuously reconcile truth and intent until intended work is actually realised.’
APPENDIX A: COMPONENT MAPPING TABLE
APPENDIX B: KEY TERMS