From Score Engine to Rule Engine: Why I Rebuilt the Decision Layer

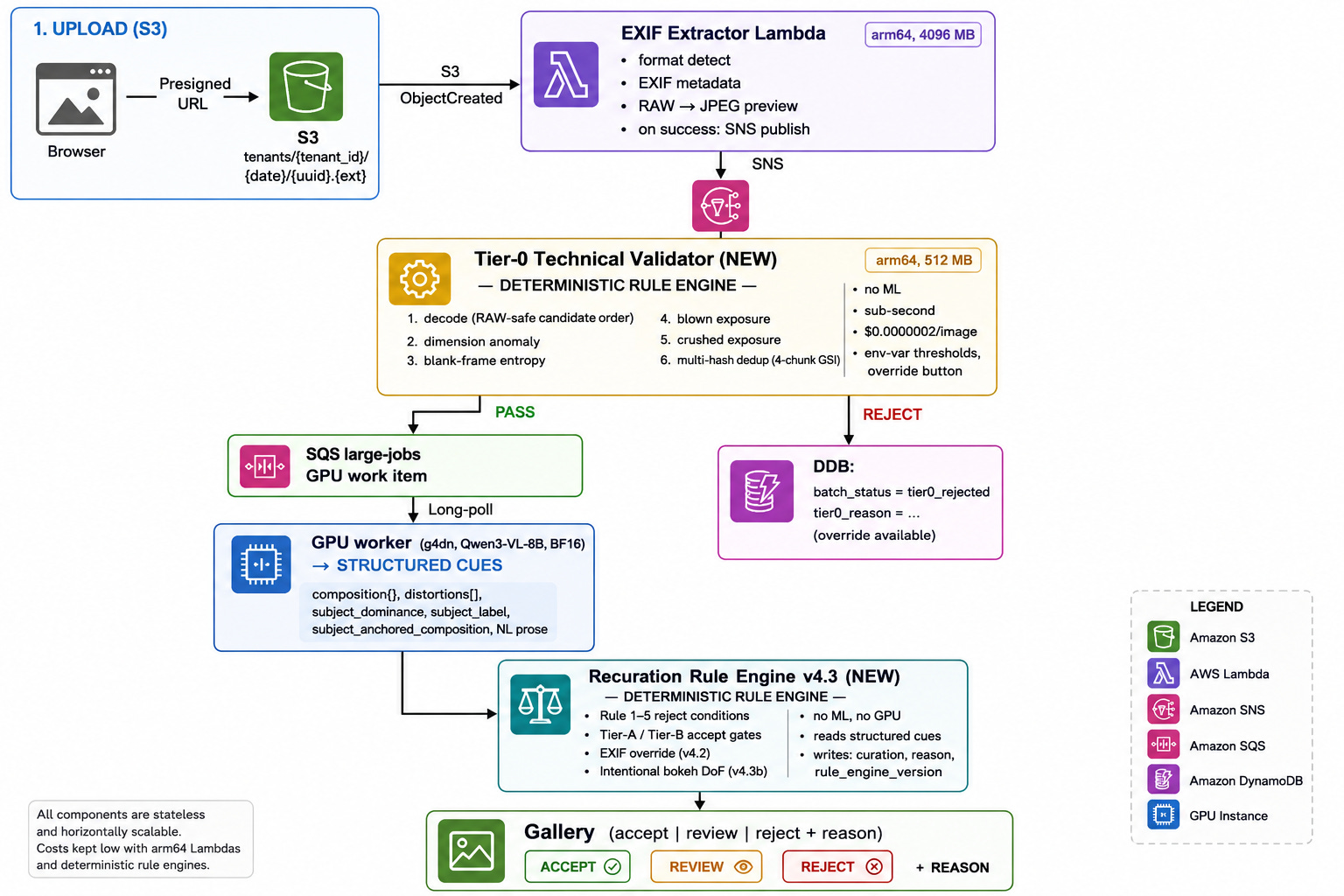
I did not set out to replace a scoring engine with a rule engine. I set out to make the system cheaper, easier to explain, and less fragile as I was not keen on moving to g5.xlarge or g6.xlarge due to prompt sizes increased and would be lot of churn in terms of architectural and infra changes, comes with re testing every functionality and the increase in the costs both the dev costs as well as instances cost even more if non-availability of spot and on-demand, currently using 75/25 for spot and OD for g4.mdn.xlarge (and 2xlarge).
What I eventually learned was that the original design had an architectural flaw: it asked a single opaque model score to do too many jobs at once. It had to decide whether an image was technically valid, whether it was worth sending to the expensive VLM path, whether it should be accepted or rejected, and how to justify that decision later. That worked until it did not. So I split the pipeline into two deterministic layers: a Tier-0 technical validator before the model, and a rule engine after the model. That change dropped cost, improved explainability, and made policy iteration much faster.
The system I started with
Before Parjanya v2.0 architecture v5.3, the pipeline was basically this:
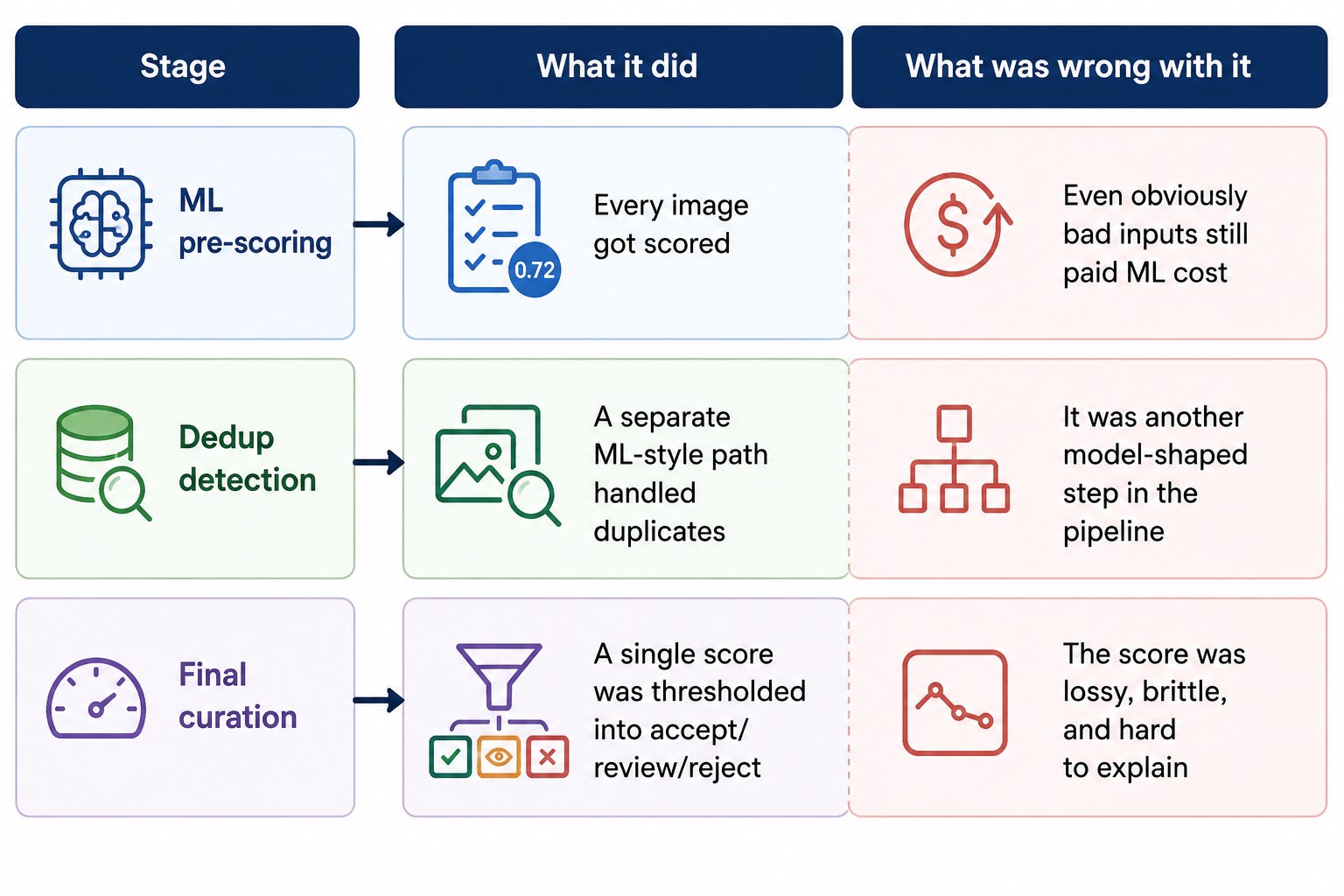
The problem was not that the model was “bad.” The problem was that I had turned a rich decision into a number. Two images with the same score could be fundamentally different: one might be a sharp wildlife shot with a minor distortion, while another might be a soft-focus landscape with no clear subject. The number hid the nuance. Prompt changes also shifted the score distribution, which meant calibration drift could silently change the policy. And when someone asked why an image was rejected, a floating-point score was not a useful answer.
What I changed
I made two structural changes.
First, I added a Tier-0 technical validator. This is a deterministic gate that runs before any expensive VLM work. It checks whether the image can be decoded, whether the dimensions are suspicious, whether the frame is blank, whether exposure is blown or crushed, and whether the image is a duplicate using multi-hash dedup. It runs on a small ARM64 Lambda, finishes in sub-second time, and costs about $0.0000002 per image.
Second, I changed the VLM output contract. Instead of asking the VLM for a single quality score, I asked it to emit structured cues: subject label, subject dominance, composition signals, distortion types, and prose. Then I fed those cues into a deterministic recuration rule engine that makes the final accept/review/reject decision and writes out a human-readable reason.
How the new decision layer works
The rule engine is deliberately boring in the best possible way. It is not trying to be clever. It is trying to be consistent.
Here is the decision logic in plain language:
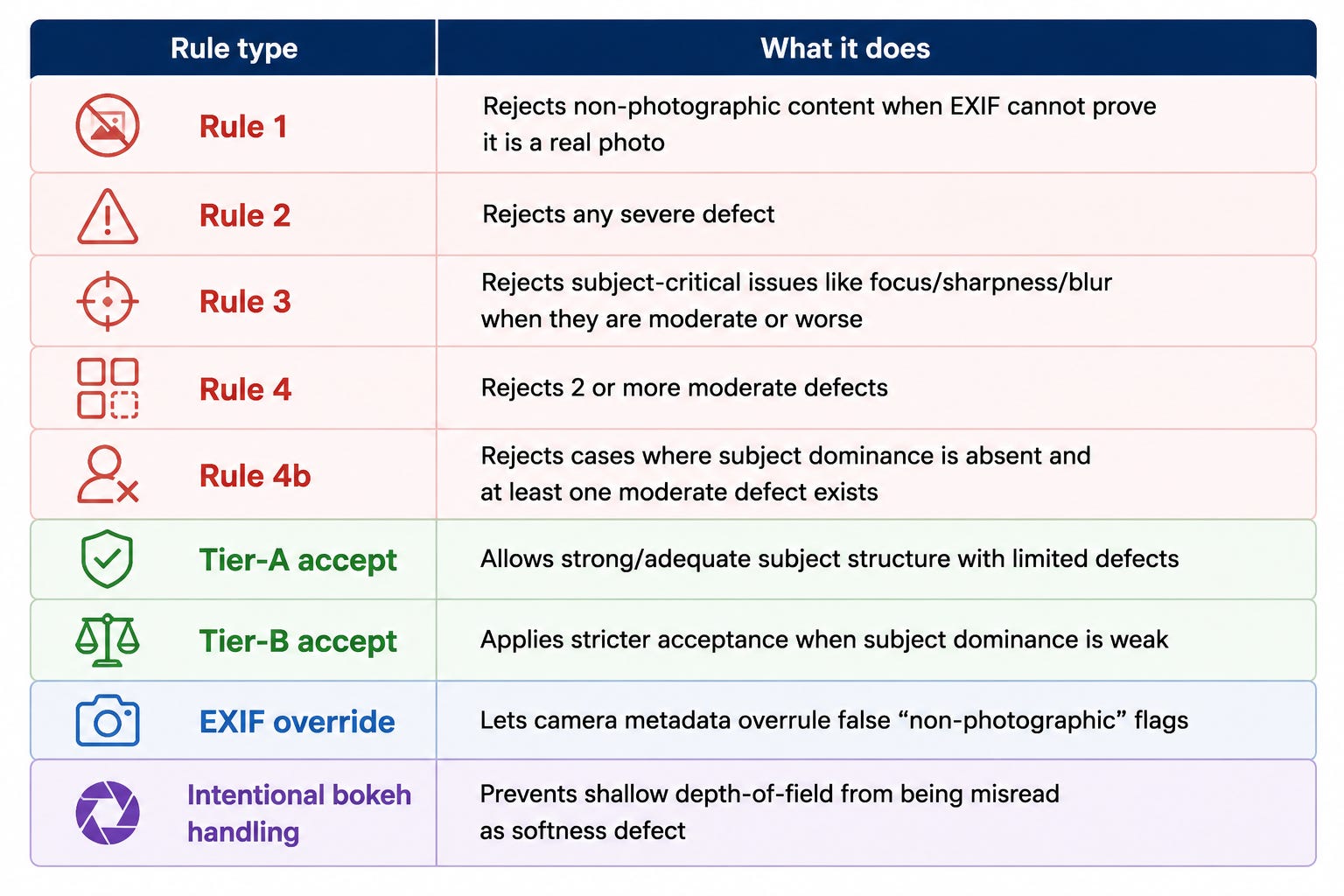
Every verdict also gets a version tag and a reason string, so I can audit what happened later. That is a huge shift from the old system, where the final answer was essentially “the score was 0.41.”
Why this mattered operationally
The first benefit was cost.
Here is the cost comparison I care about most:

On my typical tenant workload, GPU spend still dominates the bill, so every image I keep out of the GPU queue is real leverage. I also found one non-obvious cost: at single-tenant scale, about half of the per-drain cost was NAT Gateway egress, not GPU. In the measured v25 drain, NAT cost was actually larger than GPU cost. That means the rule engine improved the decision layer, but infrastructure tuning still matters separately.
The second benefit was iteration speed.
I moved the rule engine through several versions in days, not weeks. The workflow became: edit the rule file, test it on canaries, inspect the reasons, then run the full re-curation if it looked good. No GPU redeploy. No prompt-engine rebuild. No waiting for model infrastructure to churn. In practice, that made policy iteration feel like software engineering again instead of model ops. The v25 drain took 7 hours 41 minutes end to end, but the rule-engine pass over 3,427 rows took less than a minute.
The third benefit was explainability.
I finally had a decision layer that could say things like:
“reject — subject-critical motion blur”
“reject — 3 slight defects stack”
“review — weak subject dominance; technically clean”
That may sound small, but it changes everything when a user asks why something was rejected. A reason string is much more useful than a numeric score.
The fourth benefit was robustness to prompt drift.
When the IQA prompt changed from v16 to v17, the score distribution shifted. Under the old design, that meant threshold recalibration and potential policy drift. Under the new design, the rule engine sat on top of structured fields whose meaning stayed stable across prompt versions. The model could change in ways that improved extraction without forcing me to rethink the whole decision layer.
The measured validation run
The clearest proof came from the v25 rescore.
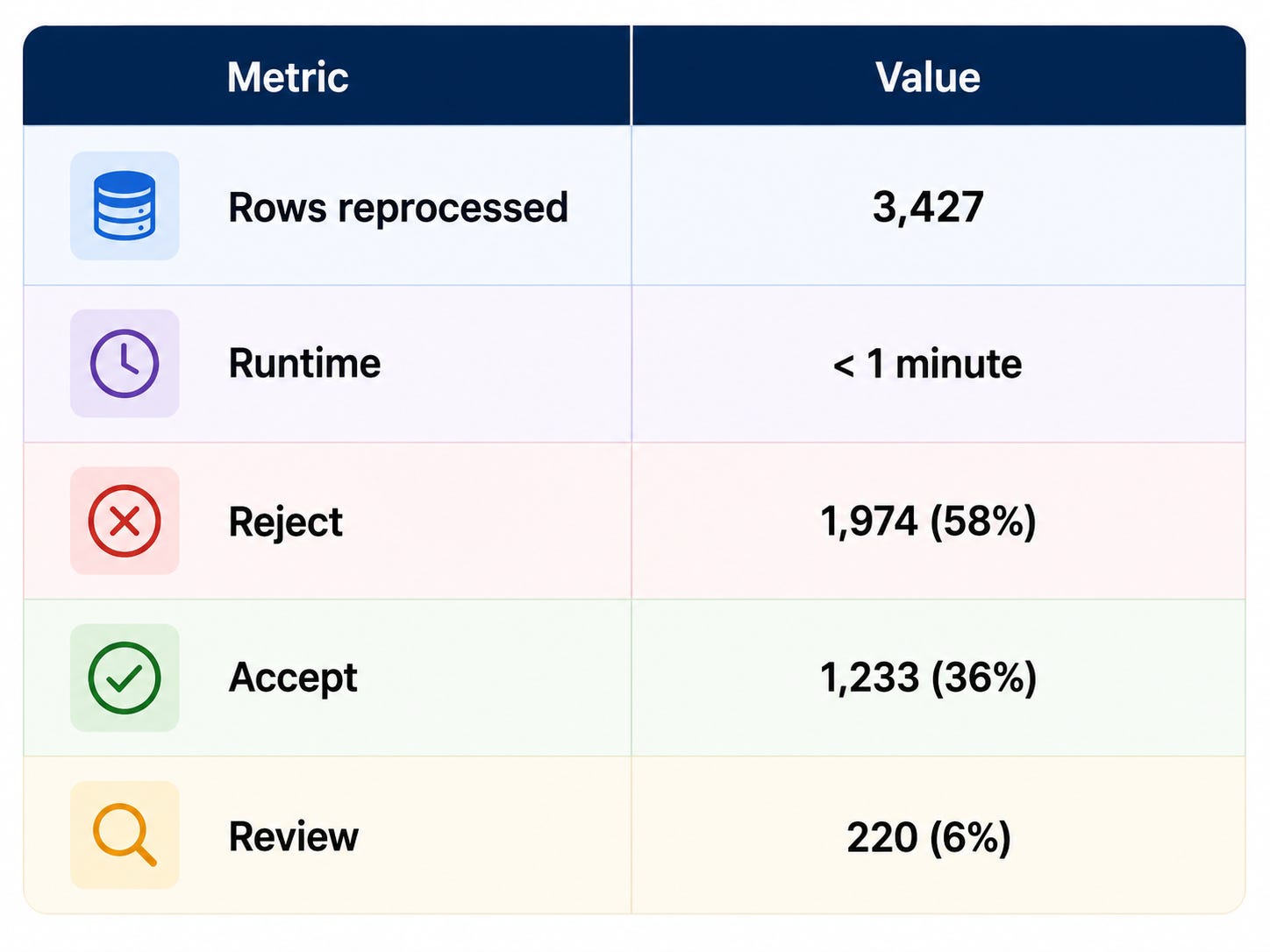
I had 2,426 images drained through the pipeline, and then 3,427 rows reprocessed by the rule engine. This was not a synthetic benchmark. It was the first large enough live run to give me defensible numbers.
Pipeline results
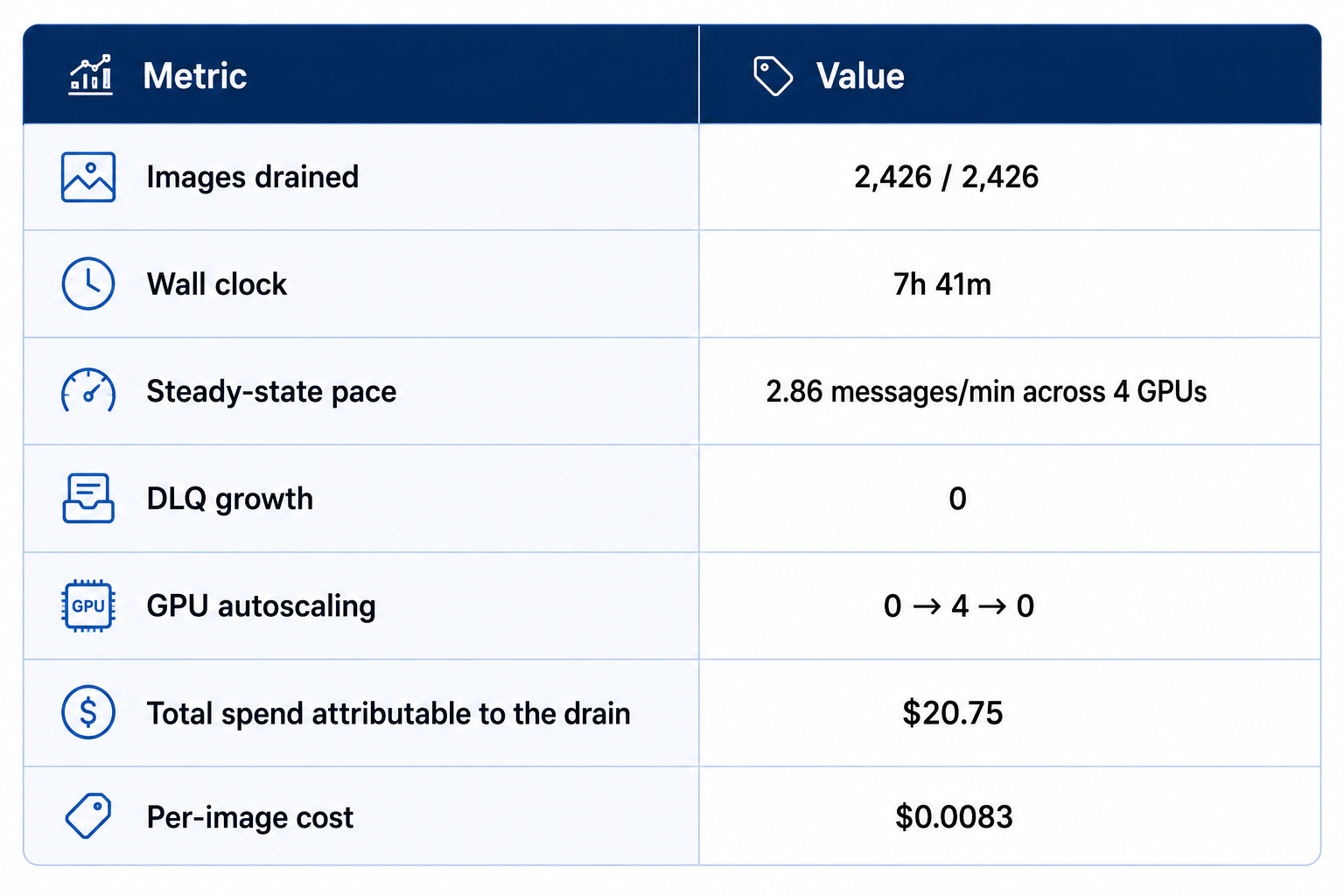
What stood out to me was not just that the run completed, but that it completed cleanly. There was no message loss, the DLQ stayed at zero, and the autoscaler shut down correctly after the queue emptied.
Rule-engine results
The most interesting transitions were:
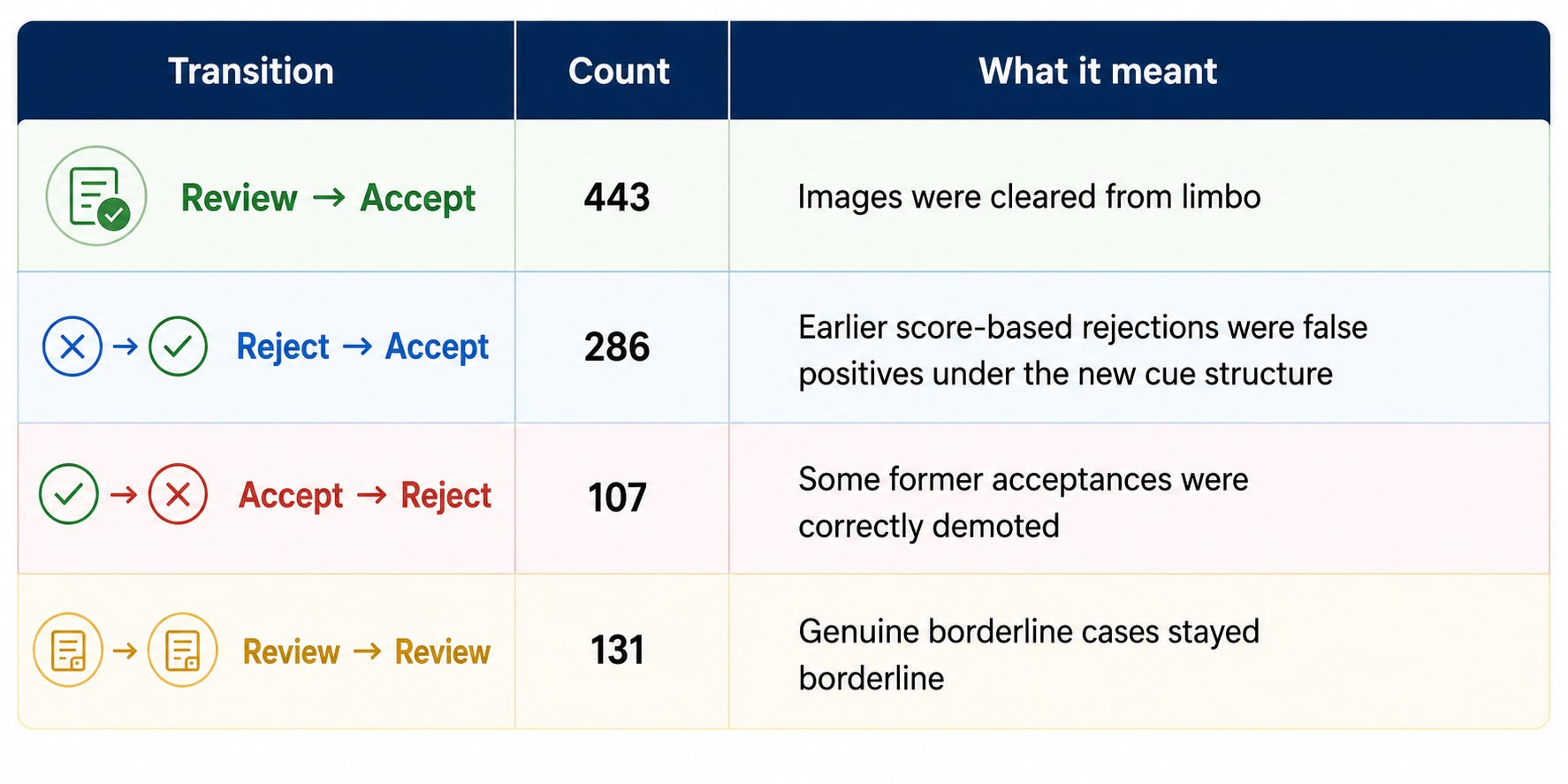
That last part mattered to me because it showed the rule engine was not trying to force certainty where none existed. It preserved uncertainty instead of masking it.
Why this architecture works
This pattern is not new in spirit. It is a cascade: a cheap stage rejects obvious failures, and the expensive stage only handles what survives. That reduces inference cost and keeps the scarce GPU path for cases that actually need it. The broader literature supports the same idea, especially for VLM and moderation workloads.
For me, the more important pattern was extract-then-decide. The VLM is the extractor. The rule engine is the decider. Once I separated those roles, the system became easier to reason about. The model could be probabilistic and flexible. The policy could remain deterministic and auditable.
What I watch for now
I did not trade away all the hard problems. I just moved them into better places.
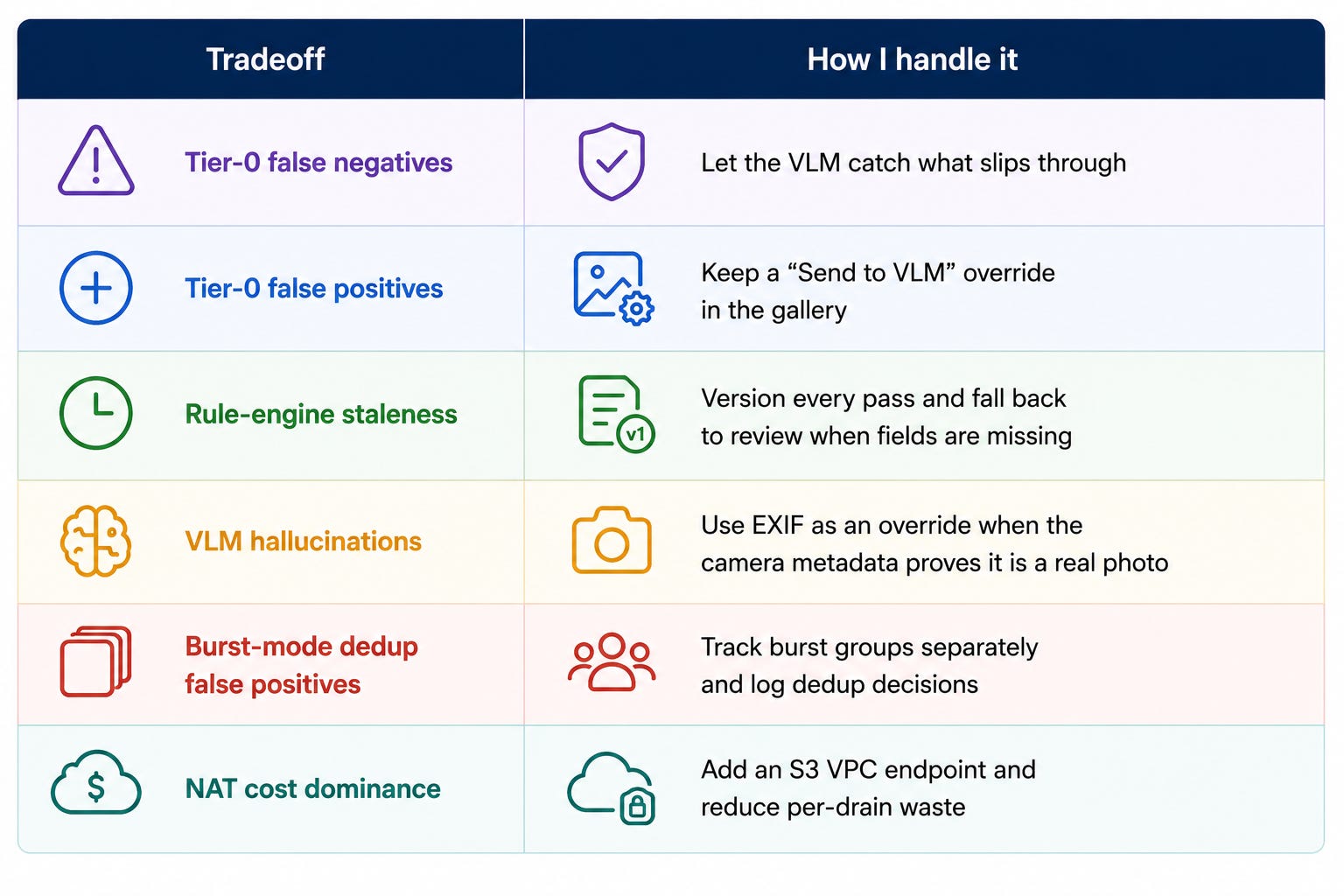
That last item is still open: infrastructure cost can easily dominate the apparent model cost, so I do not want to fool myself into thinking the architecture alone solved everything.
What is next
The next steps are pretty clear to me. Dedup is still shipped but not yet used as a hard gate in production. The rule engine will likely get a v5 cleanup once the remaining fallback paths are collapsed. And I want a dashboard that breaks out cost by Tier-0 reject reason, because it would be useful to know exactly how much pure margin I am saving when corrupt files, blank frames, and blown exposures are filtered early.
The takeaway
I did not move from “AI” to “rules.” I moved from one opaque score to a more honest pipeline.
Now the model extracts structure, the rule engine makes the decision, and the cheap gate keeps obvious failures away from the GPU. That gave me lower cost, faster iteration, and a system I can actually explain to another human without hand-waving. For a production image pipeline, that is the architecture I trust more.
One thing I appreciated only after moving to the rule engine was how much the user experience improved once the system stopped behaving like a black-box scorer.
Previously, the output was essentially a number hidden behind a threshold. After the re-curation architecture, every image started carrying an explainable pipeline trail: technical validation status, VLM enrichment state, structured distortion analysis, composition signals, subject analysis, and finally a deterministic curation verdict with explicit reasoning. The gallery stopped feeling like “an AI guessed a score” and started feeling like a traceable review system.
In the image below, for example, the pipeline clearly shows the two-stage flow: Tier-0 technical validation first, followed by VLM enrichment and structured analysis. The system identifies slight sharpness and focus issues, explains where they occur (“subject lacks critical sharpness on head and eye area”), records composition attributes like framing and depth layers, and still accepts the image because the final rule evaluation determined the defects were minor enough relative to subject structure and overall composition quality.
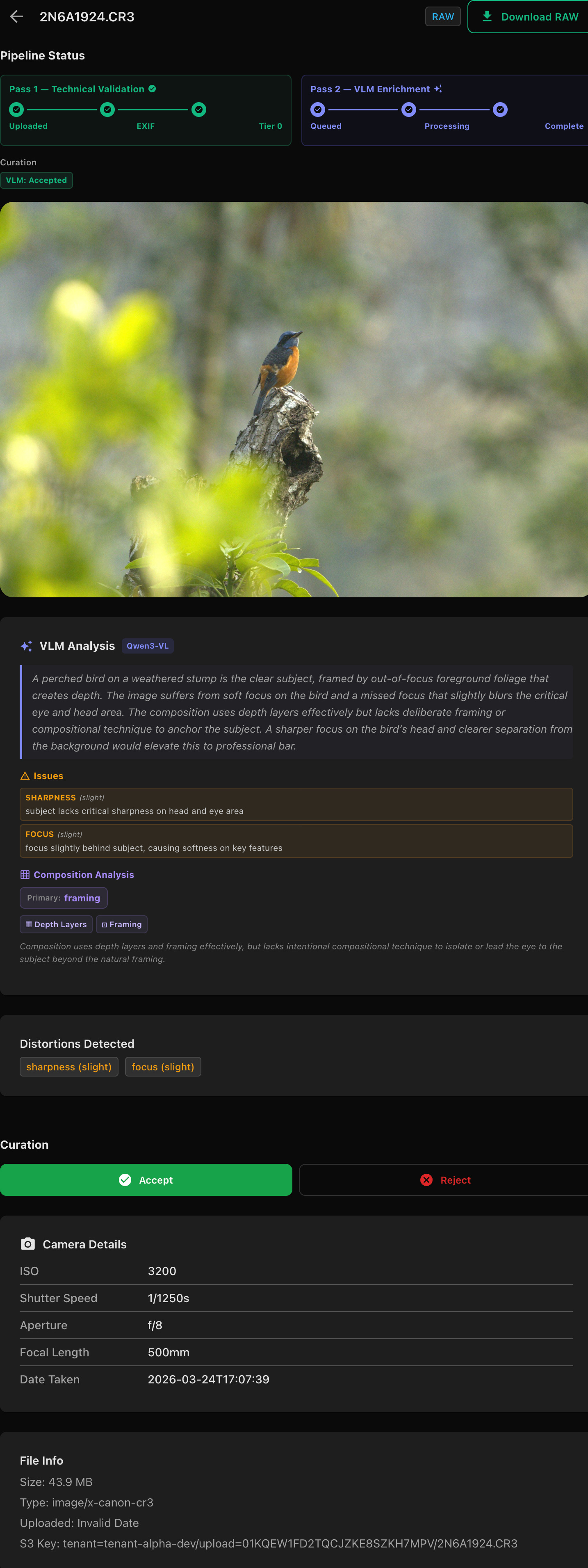
That distinction matters. Under the old scoring engine, this image could easily have landed near a threshold boundary and become another opaque 0.62 vs 0.58 decision. Under the new architecture, the reasoning is visible, deterministic, and debuggable.
The biggest realization for me was this: the rule engine did not make the system less intelligent. It made the intelligence easier to operationalize.
The VLM still does the hard perceptual work — understanding composition, defects, subject prominence, and scene semantics. But the final decision layer is no longer probabilistic glue hidden behind one floating-point number. It is now an auditable policy system built on top of structured perception.
That separation ended up becoming the real architectural shift.