From Pipeline to Platform
Event-Driven TBIE Architecture, Reconciliation Patterns, and the Lessons from Building Parjanya v2.0

In my previous post few weeks ago, I introduced TBIE — Truth, Belief, Intent and Execution — as a framework for reasoning about resilient distributed systems.

The framework emerged from a simple observation:
Distributed systems rarely fail through catastrophic outages.
More often, they fail through divergence.
Truth says one thing.
Execution does another.
Intent disappears.
Belief becomes detached from reality.
TBIE gave me a vocabulary for understanding those failures.
What I did not fully appreciate at the time was the architectural consequence of taking TBIE seriously.
I thought I was building an AI pipeline.
I ended up building a platform.
More specifically, I ended up building a reconciliation-driven control plane whose primary responsibility was not inference, enrichment, scoring, or curation.
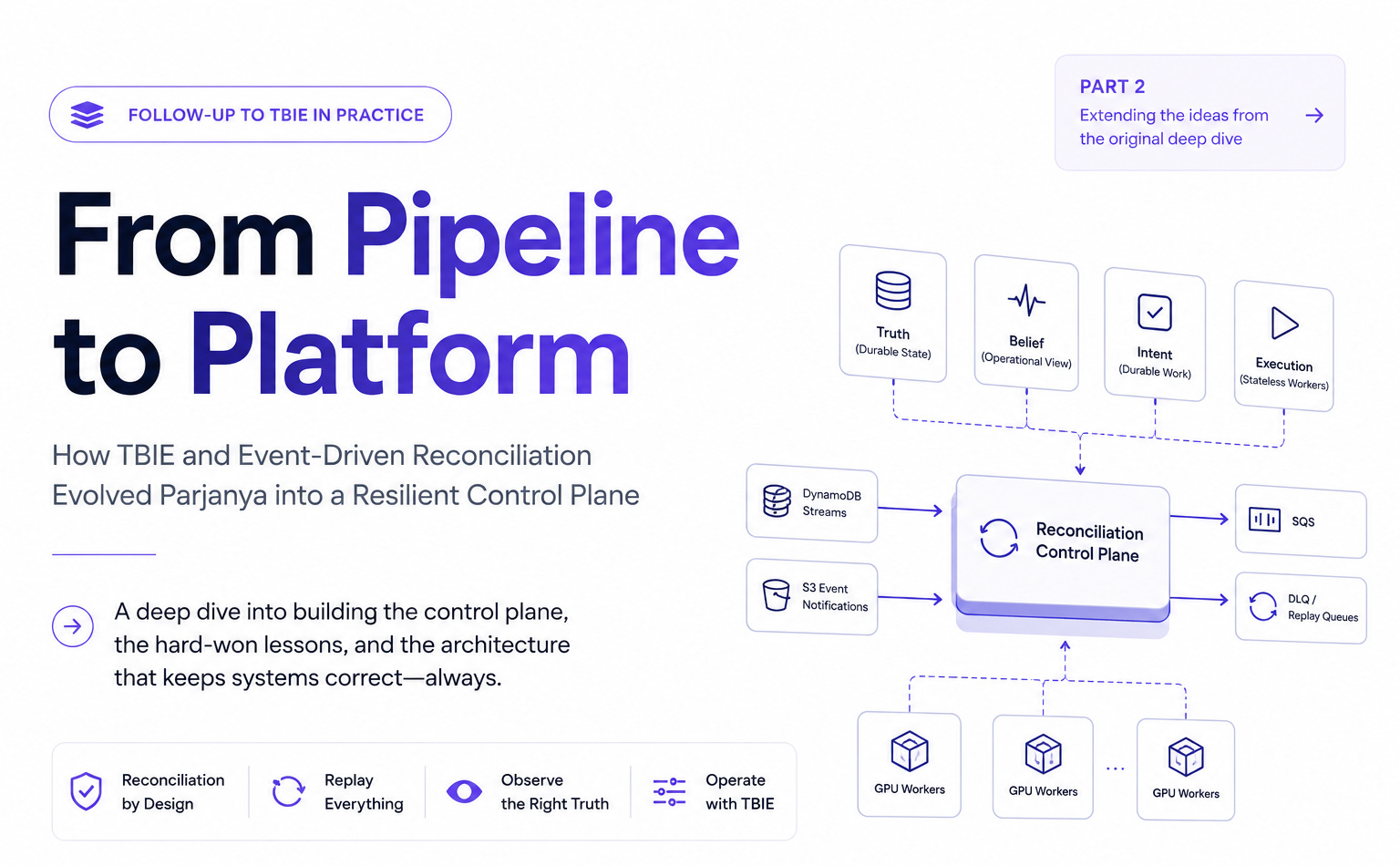
Its primary responsibility was preserving correctness.
That realization fundamentally changed how I thought about reliability.
The hard problems in Parjanya v2.0 were not model problems.
They were coordination problems.
Not GPU problems.
Not inference problems.
Not even scaling problems.
The hardest problems emerged whenever the system lost alignment between:
what was true,
what work should exist,
what execution was currently happening,
and what the system believed was happening.
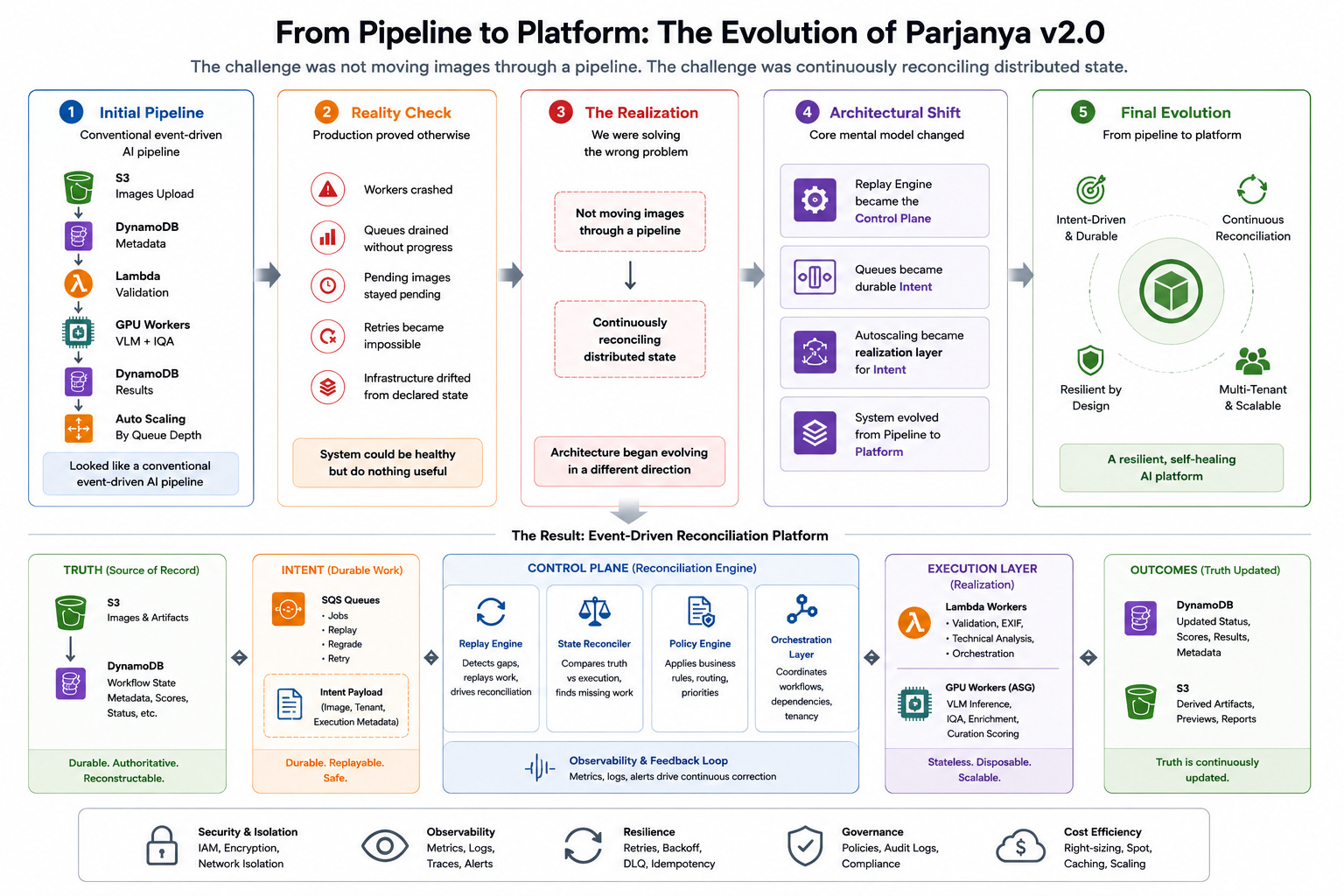
The original architecture looked deceptively simple.
Images landed in S3.
Metadata was written into DynamoDB.
Validation ran through Lambda functions.
GPU workers performed VLM enrichment and IQA processing.
Results were written back into DynamoDB.
Autoscaling reacted to queue depth.
At first glance, it looked like a fairly conventional event-driven AI pipeline.
Production quickly proved otherwise.
Workers crashed.
Queues drained without progress.
Pending images remained pending forever.
Retries became impossible.
Infrastructure drifted away from declared state.
The system could remain technically healthy while doing absolutely nothing useful.
That was the moment I realised we were solving the wrong problem.
The challenge was not moving images through a pipeline.
The challenge was continuously reconciling distributed state.
Once viewed through that lens, the architecture began evolving in a very different direction.
The replay engine stopped being a utility.
It became the control plane.
Queues stopped being transport mechanisms.
They became durable Intent.
Autoscaling stopped being a scaling feature.
It became a realization layer for Intent.
And the system itself stopped behaving like a pipeline.
It started behaving like a platform.
This article is the story of that evolution.
Preface
Distributed systems rarely fail in the way architecture diagrams suggest.
The boxes stay alive. The queues still exist. The databases continue accepting writes. The autoscaling groups look healthy. The dashboards even remain green.
And yet the system silently stops doing useful work.
An image sits in a pending state forever. A queue drains but no GPU ever runs. A worker crashes and deletes the only replayable work item. A presigned upload URL looks valid but browser execution never begins. A GPU instance launches correctly while the actual container inside it continuously crashloops.
Most production failures are not total outages. They are reconciliation failures.
Something the system believes should happen never actually happens. Or something already completed continues to look pending. Or a control plane silently loses the ability to coordinate execution.
Parjanya v2.0 forced us to confront this repeatedly.
Initially, the architecture looked straightforward:
Images upload into S3
Metadata lands in DynamoDB
Lambdas perform validation and enrichment
GPU workers run VLM and IQA workloads
Results are written back into DynamoDB
Autoscaling follows queue depth
At first glance, this looked like a normal AI pipeline.
In practice, it evolved into something else.
The deeper challenge was not inference. The challenge was maintaining alignment between:
the durable truth of the system,
the operational understanding of the system,
the work the system intended to perform,
and the execution layer actually performing it.
Truth → Belief → Intent → Execution
TBIE was never intended as branding. It emerged as an operational language for reasoning about reliability.
The model eventually shaped:
the event-driven reconciliation architecture,
the autoscaling strategy,
the replay model,
the control plane,
failure recovery,
multi-tenant orchestration,
policy regrading,
infrastructure debugging,
and eventually the broader direction of Parjanya itself.
This article is a deep dive into that journey.
It is not a summary. It is a detailed architectural walkthrough of:
how TBIE emerged,
why event-driven reconciliation mattered,
what failed in production,
how those failures were diagnosed,
and why reconciliation patterns matter far more than most AI infrastructure discussions acknowledge.
The goal is not merely to explain Parjanya.
The goal is to explain how resilient AI systems are actually built.
1. The Real Problem in Distributed AI Systems
Most modern AI infrastructure discussions focus heavily on models.
Which VLM?
Which embedding strategy?
Which vector database?
Which GPU?
Which inference framework?
Which quantization?
These questions matter.
But they are not usually what breaks systems.
The real production problems tend to look different:
Work disappears.
Retries become impossible.
Workers process stale state.
Uploads partially succeed.
Queues drain without progress.
Control planes silently stop coordinating.
Autoscaling behaves correctly against the wrong metric.
Infrastructure layers drift away from declared source-of-truth.
In other words:
The problem is not merely computation. The problem is reconciliation.
Distributed systems are fundamentally coordination systems.
A resilient architecture needs to answer:
What is the durable truth?
What work should exist?
What execution is currently happening?
Can the system reconstruct work after failures?
Can the system distinguish transient failure from terminal failure?
Can infrastructure drift be detected?
Can the system replay work safely?
Can policy changes be re-applied deterministically?
Most architectures answer these implicitly.
TBIE attempts to answer them explicitly.
2. TBIE — Truth, Belief, Intent, Execution
The TBIE model separates distributed systems into four operational layers.
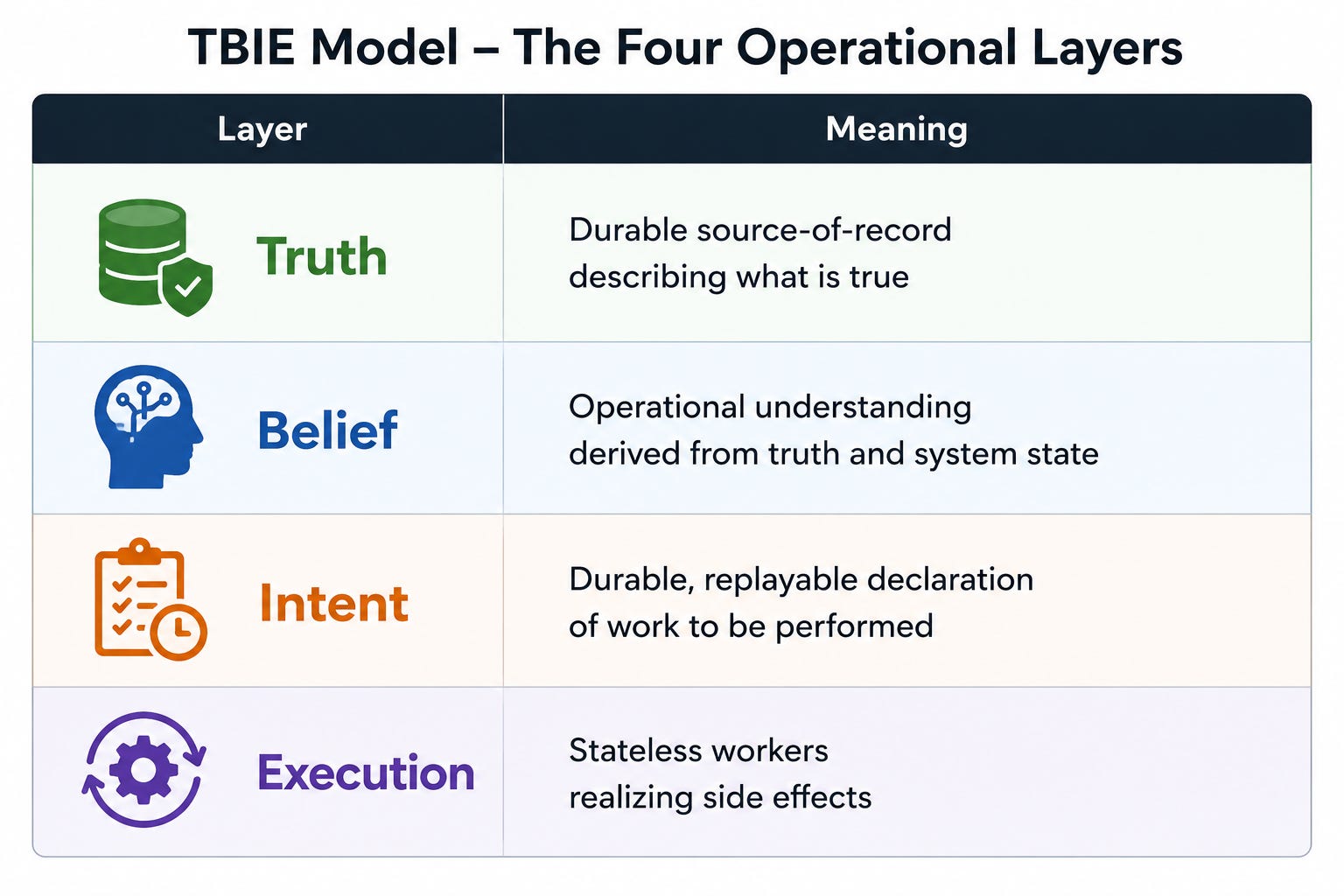
The model becomes powerful because it forces explicit boundaries.
Truth
Truth represents the authoritative record.
Truth must be:
durable,
reconstructable,
queryable,
replayable,
and independent of transient execution state.
In Parjanya:
S3 object bytes are Truth.
DynamoDB workflow fields are Truth.
Pipeline status transitions are Truth.
Curation outputs are Truth.
Hashes and metadata are Truth.
Truth is what remains after workers crash.
Truth is what survives retries.
Truth is what operators use to reconstruct system state.
Belief
Belief is operational understanding.
Belief is not always perfectly accurate.
Examples:
Queue depth
Autoscaling desired capacity
In-flight SQS messages
Worker health
Current GPU availability
Visibility timeout state
Belief may lag reality. Belief may be partial. Belief may even temporarily be wrong.
But Belief matters because orchestration depends on it.
Importantly:
Belief should be derivable from Truth + Intent.
That distinction becomes critical later.
Intent
Intent represents durable declarations of work.
Intent answers:
“What should the system attempt next?”
In Parjanya:
SQS messages are Intent.
Replay queues are Intent.
Regrade operations are Intent.
Retry workflows are Intent.
Intent is one of the most important concepts in the entire architecture.
Execution should never destroy Intent casually.
Why?
Because Intent is replayability.
Without replayable Intent:
transient failures become permanent,
retries become manual,
reconciliation becomes impossible,
and the system loses self-healing capability.
Execution
Execution is the stateless machinery that realizes work.
Execution includes:
Lambdas,
GPU workers,
autoscaling groups,
validation services,
EXIF processors,
and inference pipelines.
Execution should ideally be:
disposable,
reproducible,
restartable,
and stateless.
If an execution worker disappears, the system should still be able to recover from Truth + Intent.
That principle drove many later architectural decisions.
3. Mapping TBIE onto Parjanya v2.0
Once TBIE became the operational lens, the architecture became easier to reason about.
Truth Layer
Truth in Parjanya consisted primarily of:
S3
original uploads,
RAW image payloads,
generated previews,
derived thumbnails,
metadata artifacts.
DynamoDB
Workflow state:
batch_status
pipeline_status
curation
quality scores
VLM outputs
EXIF metadata
technical validation
image hashes
routing information
Truth represented the durable state of every image.
Intent Layer
Intent existed primarily in SQS.
Examples:
ml-large-jobs
replay queues
regrade operations
retry workflows
Each Intent payload encoded:
bucket,
object key,
tenant,
image id,
execution metadata.
Intent was intentionally replayable.
That design decision later prevented multiple catastrophic replay-loss scenarios.
Belief Layer
Belief included:
ASG desired capacity,
queue visibility counts,
in-flight message counts,
CloudWatch metrics,
worker availability,
queue backlog,
GPU scale state.
Belief drove orchestration.
For example:
queue depth controlled autoscaling,
replay Lambdas checked queue visibility,
scaling decisions relied on approximate message counts.
Belief was operationally useful but never fully authoritative.
Execution Layer
Execution included:
Lambda Workers
EXIF extraction
technical validation
replay orchestration
autoscaling control-plane logic
GPU Workers
Qwen VLM inference
IQA processing
curation scoring
natural-language enrichment
Execution workers remained stateless wherever possible.
That allowed replay to remain safe.
4. Why Reconciliation Matters
A distributed system does not stay healthy merely because components exist.
Health depends on reconciliation.
Consider this state:
DynamoDB row says pending_vlm_enrichment
SQS queue is empty
GPU ASG is scaled to zero
Nothing is technically “down.”
And yet the system is stuck.
Truth says work should exist. Intent does not exist. Execution never begins. Belief incorrectly suggests the system is idle.
This is a reconciliation failure.
TBIE made this visible.
The system needed a mechanism that continuously aligned:
Truth ↔ Intent ↔ Execution
That eventually led to the event-driven reconciliation architecture.
5. From Polling to Event-Driven Reconciliation
The original architecture used scheduled polling.
Every few minutes:
EventBridge triggered a Lambda,
the Lambda scanned DynamoDB,
pending work was discovered,
SQS messages were emitted,
GPU autoscaling was triggered.
This worked.
But it introduced fundamental limitations.
Problems with Polling
Latency
An image could wait:
0–15 minutes before the next poll cycle.
GPU cold starts already consumed several minutes. Adding polling latency made the UX significantly worse.
Waste
Most polling invocations found no work.
The control plane continuously woke up merely to rediscover emptiness.
Operational Ambiguity
Polling blurred the distinction between:
“there is no work,”
and
“the system has not discovered the work yet.”
That ambiguity complicated debugging.
Poor Reactive Scaling
Autoscaling became tied to polling frequency.
Queue discovery latency directly affected GPU startup latency.
6. DynamoDB Streams Changed the Architecture
The major architectural shift came from moving reconciliation into an event-driven model.
Instead of periodically checking for state changes:
The system reacted immediately when Truth changed.
The New Model
DynamoDB row transitions to pending_vlm_enrichment
DynamoDB Streams emits an event
Event source mapping filters relevant writes
Replay Lambda triggers immediately
SQS Intent is emitted
GPU ASG is kicked from zero
GPU workers process work
Results are written back into Truth
The architecture became reactive.
7. Anatomy of the Event-Driven TBIE
Architecture
DynamoDB Streams
The table emits:
INSERT events
MODIFY events
Filtered specifically for:
batch_status = pending_vlm_enrichment
This is extremely important.
The system does not react to every write. It reacts only when Truth crosses a workflow boundary requiring Intent creation.
Event Source Mapping
The stream mapping aggregates:
up to 50 records,
or up to 5 seconds.
This balances:
latency,
throughput,
Lambda cost,
queue pressure.
The system effectively performs micro-batching naturally.
Replay Lambda
The replay Lambda became the core reconciliation engine.
Responsibilities:
inspect stream events,
discover pending rows,
identify retriable failures,
generate replayable Intent,
avoid duplicate queueing,
trigger autoscaling.
This Lambda evolved into the operational heart of the platform.
Queue Backlog Guard
One subtle but extremely important design decision:
The replay Lambda checks queue visibility before re-enqueueing pending work.
Why?
Because replay itself can become destructive if uncontrolled.
Without a backlog guard:
the control plane could continuously duplicate Intent,
queue pressure would inflate,
workers would process stale state,
autoscaling would overreact.
This is a classic reconciliation trap.
The backlog guard prevented it.
GPU ASG Kick
The replay Lambda also became responsible for scaling GPU workers.
This matters because scale-to-zero architectures create a hidden problem:
The queue may contain work while compute remains asleep.
The replay Lambda solved this by:
emitting Intent,
then immediately setting desired ASG capacity.
That turned the replay engine into both:
a reconciliation layer,
and a control-plane orchestrator.
8. Latency Transformation
The shift from polling to event-driven reconciliation fundamentally changed responsiveness.
Before
Upload → wait for poll → queue → ASG scale → GPU boot
Total latency:
~3–20 minutes
depending on polling window timing.
After
Upload → stream event → immediate reconciliation → queue → ASG scale
Total latency:
~4–6 minutes
with remaining delay dominated almost entirely by:
EC2 startup,
model load,
GPU warm-up.
This is a very different operational profile.
The system stopped feeling batch-oriented.
It began behaving like a reactive platform.
9. The First Major TBIE Failure
Intent Destroyed Too Early
One of the earliest major incidents exposed why TBIE mattered.
Symptom
GPU workers experienced transient:
S3 download failures,
temporary consistency races,
OOM conditions.
But the worker still deleted the SQS message.
At the same time:
DynamoDB was updated with:
vlm_failed
The result:
Intent disappeared,
Truth claimed terminal failure,
automatic replay became impossible.
This was a severe reconciliation violation.
The Core TBIE Violation
Execution destroyed Intent before retries were exhausted.
That single decision broke replayability.
TBIE clarified the failure immediately.
The problem was not merely worker instability.
The problem was:
Execution invalidated Intent prematurely.
The Fix
The worker execution model changed.
Instead of binary success/failure, workers returned:
retry
do NOT delete SQS message
do NOT write terminal Truth
terminal_failure
write durable failure state
delete Intent
completed
write success state
delete Intent
This restored replay semantics.
Why This Matters Beyond Parjanya
Many distributed systems accidentally conflate:
“execution failed once” with
“execution is permanently impossible.”
Those are not equivalent.
TBIE forced the architecture to encode that distinction explicitly.
10. Truth Pending, Intent Missing
Another class of failures appeared repeatedly.
Symptom
Rows remained:
pending_vlm_enrichment
But:
queues were empty,
GPU workers never started,
no replay existed.
The system appeared healthy.
But nothing moved.
What TBIE Revealed
Truth and Intent were decoupled.
The architecture had assumed:
“If Truth says pending, Intent must already exist.”
That assumption was false.
Reconciliation cannot be assumed. It must be continuously enforced.
The Replay Architecture
This led to:
replay scripts,
scheduled replay Lambdas,
retriable failure reset workflows,
queue reconstruction logic.
The replay Lambda evolved into a continuously running reconciler.
This was the moment the architecture stopped being merely a pipeline.
It became a platform.
11. Wrong Bucket, Right Key
A Perfect Distributed Systems Failure
One of the most revealing incidents involved bucket mismatch.
Symptom
GPU workers repeatedly failed with:
s3_download_error
Yet:
queue depth was growing,
autoscaling worked,
workers were alive,
previews existed.
Everything looked operational.
Root Cause
The SQS payload contained:
the correct object key,
but the wrong bucket.
The preview existed.
Just not in the referenced bucket.
Why This Was Architecturally Important
The system was reliably executing the wrong instruction.
This is one of the hardest classes of distributed failures.
Nothing is technically broken.
The system is functioning exactly as instructed.
The instruction itself is invalid.
TBIE framed this correctly:
Intent must not merely exist. Intent must be correct and replayable.
The Fix
The architecture introduced:
bucket source-of-truth rules,
preview-aware routing,
enqueue eligibility tightening,
RAW-aware preview validation,
replay resets for retriable failures.
The fix was operationally deeper than changing one field.
It hardened the meaning of Intent itself.
12. CORS Failures and Split Truth
One of the most subtle incidents occurred at the ingestion boundary.
Symptom
Frontend uploads failed with browser CORS errors.
But backend APIs:
generated presigned URLs,
wrote pending upload records,
and returned success responses.
Truth looked correct.
Execution never happened.
What Actually Failed
The browser failed during:
OPTIONS preflight.
Execution never reached:
PUT upload.
The TBIE Interpretation
Truth existed. Intent existed. Execution failed before realization.
This became an important diagnostic heuristic:
When work is stuck:
Ask whether:
Truth is missing,
Intent is missing,
or Execution cannot realize Intent.
That framing simplified debugging enormously.
13. Event-Driven Architecture Exposes Infrastructure Drift Faster
As the architecture became more reactive, infrastructure drift became easier to detect.
This was unexpected.
Example: Stale Worker Image Tag
The ASG launch template still referenced:
:v20
while the actual system had moved to:
:v23
The ASG launched correctly. Cloud-init executed. Docker attempted to pull. The image no longer existed.
Workers never started.
The Deeper Problem
Terraform ignored user_data changes.
This created silent divergence between:
declared source-of-truth,
and actual runtime execution.
TBIE exposed this as an Execution drift problem.
Truth, Belief, and Intent were all correct.
Execution itself had drifted away from reality.
The Architectural Lesson
Infrastructure reproducibility is not optional.
Execution environments must remain tied to durable source-of-truth.
Otherwise replay becomes dangerous because:
the same Intent may produce different outcomes over time.
14. AMI Drift and Runtime Incompatibility
Another failure emerged at the AMI layer.
Symptom
Containers started. But model loading crashed.
The model weights existed. The processors did not.
The AMI bake omitted Python files required by:
trust_remote_code=True
The worker entered a crashloop.
Why This Was Important
Again:
Truth was correct. Intent was correct. Belief suggested workers existed.
Execution failed due to stale artifacts.
This is precisely why replayable systems require reproducible execution environments.
TBIE repeatedly reinforced this architectural truth.
15. The Replay Lambda Became the Control Plane
Originally, the replay Lambda was operational glue.
Eventually, it became the platform control plane.
Responsibilities expanded to include:
pending reconciliation,
retriable failure resets,
tenant discovery,
queue backlog management,
autoscaling coordination,
replay orchestration,
dynamic routing.
The replay layer became central infrastructure.
This was a critical architectural evolution.
16. The IAM Incident
When the Control Plane Goes Blind
One of the most dangerous incidents involved a missing IAM permission.
Symptom
The replay Lambda continuously crashed on:
sqs:GetQueueAttributes
for nearly 12 hours.
But:
EventBridge still invoked it,
the schedule looked healthy,
the infrastructure appeared alive.
Meanwhile:
pending rows accumulated,
queues stopped reconciling,
autoscaling logic failed.
The TBIE Lesson
The control plane had lost Belief.
Without Belief:
the replay engine could not safely emit Intent,
queue guards could not function,
orchestration collapsed.
The system looked operational while the reconciler was effectively dead.
The Operational Insight
A scheduled Lambda is not necessarily a healthy Lambda.
Control-plane observability matters more than worker observability.
Why?
Because worker failures are recoverable.
Control-plane blindness disables recovery itself.
17. Dynamic Tenant Discovery
As Parjanya moved toward beta onboarding, static tenant configuration became a bottleneck.
Originally:
The replay Lambda used static tenant lists.
Every new tenant required:
Terraform changes,
environment updates,
redeploys.
This violated the self-service model.
The Evolution
The architecture introduced:
tenant registry writes during upload completion,
runtime tenant discovery,
dynamic reconciliation.
The control plane became data-driven rather than configuration-driven.
This is a major architectural distinction.
Reactive systems scale operationally only when discovery becomes dynamic.
18. Regrading and Policy Replay
One of the most powerful consequences of TBIE was deterministic replay.
This became especially valuable during policy changes.
Example
The IQA policy evolved to reject:
screenshots,
banners,
posters,
slides,
social cards,
infographics,
illustrations.
The architecture needed to:
reset VLM-derived Truth,
regenerate Intent,
rerun GPU enrichment,
rewrite curation outputs.
This was not merely a retry.
It was a deterministic policy replay.
Why This Matters
Most ML systems struggle with:
“How do we reprocess historical data safely?”
TBIE already contained the answer.
Truth could be reset to a replay boundary. Intent could be regenerated. Execution remained stateless.
The system became replay-native.
This is a profound operational capability.
19. Queue Retention and Weekend Gaps
Another subtle operational issue:
Scale-to-zero architectures create temporal gaps.
Scenario
Users upload images Friday evening. GPU workers remain offline over the weekend.
If queue retention is too short:
Intent disappears before execution resumes.
Truth remains pending.
Intent vanishes.
This is catastrophic reconciliation drift.
The Fix
Queue retention was extended.
This ensured Intent outlived temporary execution dormancy.
An important TBIE lesson emerged:
Intent durability must exceed execution availability windows.
20. Why Event-Driven Reconciliation Matters
Beyond AI
Although Parjanya is an AI platform, the architectural lessons generalize broadly.
The same TBIE principles apply to:
distributed media systems,
payment processing,
ETL pipelines,
logistics systems,
asynchronous workflows,
microservice orchestration,
large-scale ingestion platforms.
The core challenge is universal:
How do you maintain alignment between:
durable truth,
intended work,
operational state,
and actual execution?
TBIE provides a vocabulary for reasoning about that alignment.
21. The Shift from Pipeline to Platform
This was perhaps the most important realization.
A pipeline moves data.
A platform:
survives retries,
supports replay,
reconciles state continuously,
tolerates execution drift,
evolves policy safely,
supports operational introspection,
and remains debuggable under failure.
The event-driven TBIE architecture pushed Parjanya decisively toward the latter.
The replay Lambda stopped being a utility.
It became the reconciliation brain of the system.
The architecture stopped being:
“process uploaded images.”
It became:
“maintain durable correctness while asynchronous distributed execution continuously changes.”
That is a very different engineering problem.
22. The Operator’s Mental Model
TBIE becomes most useful when it changes how incidents are diagnosed.
By the time Parjanya matured into an event-driven reconciliation system, the debugging approach itself had changed. Operators no longer began by asking whether “the queue is healthy” or whether “the GPU workers are running.” Those signals still mattered, but they were no longer treated as authoritative.
Instead, every investigation began with a much more precise question:
Is the system waiting because Intent is missing, or is Intent present but Execution cannot realize it?
That distinction dramatically narrowed the search space during incidents.
If Truth showed a growing backlog while Intent remained near zero, the issue was usually in reconciliation itself. Replay Lambda failure, queue emission failure, stale tenant discovery, or a blind control plane could all create this pattern. The queue might look empty and the autoscaling group might remain at zero, yet the real failure would not be in the workers. It would be in the system’s ability to regenerate Intent from Truth.
If Intent existed but Execution failed repeatedly, the investigation shifted toward realization problems instead: bucket routing mismatches, stale AMIs, launch-template drift, IAM gaps, runtime incompatibilities, model-loading failures, endpoint routing problems, or browser-side execution failures.
That diagnostic framing changed operations significantly. Incidents became easier to classify because TBIE separated the architecture into meaningful operational boundaries. Instead of treating the platform as one opaque pipeline, operators could isolate whether the failure belonged to Truth, Belief, Intent, or Execution.
The model also made one uncomfortable reality obvious: dashboards alone are not enough. A queue can look healthy while Truth continues accumulating backlog. Autoscaling can look correct while workers continuously crashloop. A scheduled Lambda can appear operational while silently failing every invocation because of an IAM permission gap.
TBIE did not eliminate debugging complexity. What it did was make debugging systematic.
23. When the System Hangs at 02:00 AM
Architectural diagrams are useful during design reviews.
Runbooks matter during incidents.
One of the most important evolutions in Parjanya v2.0 was realizing that reconciliation needed to exist not only in architecture, but also in operational practice. TBIE only became truly useful once there was a repeatable process for recovering the system under pressure.
The first step during any “hung VLM” investigation became identifying the TBIE boundary itself.
Truth consisted of the DynamoDB image rows and their workflow state. Intent consisted of SQS messages representing GPU work. Execution consisted of GPU workers consuming that Intent and writing enriched Truth back into DynamoDB. Belief consisted of queue depth, autoscaling state, visibility counts, worker health, and operational telemetry.
Once those boundaries were established, incident triage became much more structured.
Operators first checked Truth backlog. Were rows accumulating in pending_vlm_enrichment? If yes, the system still believed work should happen.
Next came Intent backlog. Did SQS contain replayable work items? If Truth backlog was high while Intent remained near zero, then reconciliation itself had failed.
Then came Execution health. Were GPU workers alive? Were containers actually starting? Were model loads succeeding? Were workers consuming messages or continuously failing before acknowledgement?
Several operational shortcuts emerged over time.
If the GPU log group was empty while ASG instances existed, the problem was often below the application layer entirely. Cloud-init failures, stale image tags, or broken launch templates frequently surfaced first through EC2 console output rather than through CloudWatch worker logs.
If the replay Lambda appeared scheduled but no queue activity existed, IAM permissions became the first thing to inspect. One of the most dangerous incidents in the system occurred precisely because the reconciliation Lambda could no longer read queue attributes, effectively blinding the control plane while the infrastructure superficially appeared healthy.
If rows repeatedly failed with S3 download errors while workers remained alive, the issue was often deterministic addressing rather than transient instability. Wrong-bucket references, preview routing mismatches, or endpoint configuration drift could all create workers that failed consistently while still appearing operational.
Over time, this changed the operational mindset of the platform. The goal stopped being “restart the workers and hope.” The goal became understanding exactly where reconciliation had broken down and then repairing the appropriate boundary.
That distinction is subtle, but extremely important.
A resilient platform is not the one that avoids incidents. It is the one that can recover from them methodically.
24. Guardrails and Proactive Controls
One of the clearest architectural patterns that emerged from Parjanya was that every major incident eventually needed to produce a permanent guardrail.
Without that discipline, incidents remain stories. With it, incidents become operational evolution.
The architecture gradually accumulated a large number of proactive controls:
Transient worker failures no longer delete Intent prematurely. Replay Lambdas continuously reconcile pending Truth. Reproducible lockfiles prevent dependency drift. Terraform validations reject invalid wildcard CORS patterns. Tenant discovery became dynamic rather than operator-maintained. Queue retention was extended to match real outage windows rather than idealized assumptions.
Many of these controls were not introduced because the architecture diagram required them. They emerged because production failures revealed where reconciliation could silently drift.
This is one of the strongest long-term lessons from the TBIE model.
Resilience is not achieved through one large design decision. It is accumulated gradually through operational guardrails.
The mature version of the system looked very different from the original one not because the core architecture changed dramatically, but because every important failure eventually became:
a validation rule,
a replay strategy,
a Terraform constraint,
a CI assertion,
a queue safeguard,
or an operational diagnostic.
That is how resilient systems evolve in practice.
They convert incidents into institutional memory.
25. Maintenance as a Reliability Discipline
One of the easiest mistakes in distributed systems is assuming resilience is something implemented once.
In reality, resilience is maintained continuously.
By the later stages of Parjanya v2.0, the team had accumulated a growing operational checklist precisely because many failures were caused not by dramatic outages, but by small forms of drift.
Replay logic and worker behavior needed to evolve together. GPU image tags needed to stay aligned with launch templates. Lockfiles had to remain committed when dependencies changed. Tenant buckets required CORS validation before onboarding. Queue retention needed to reflect actual business downtime windows. Backend API contracts and frontend types had to remain synchronized.
None of these tasks sound individually sophisticated.
But distributed systems rarely collapse from a single catastrophic event. They erode through gradual inconsistency.
That realization changed how the platform was maintained.
Operational discipline became part of the architecture itself.
The maintenance checklist was therefore not merely documentation. It was a recognition that reconciliation must continue throughout the entire lifecycle of the platform.
26. Why TBIE Matters Beyond AI
Although Parjanya is an AI platform, the architectural lessons generalize broadly.
The same TBIE principles apply to:
distributed media systems,
payment processing,
ETL pipelines,
logistics systems,
asynchronous workflows,
microservice orchestration,
large-scale ingestion platforms.
The core challenge is universal:
How do you maintain alignment between:
durable truth,
intended work,
operational state,
and actual execution?
TBIE provides a vocabulary for reasoning about that alignment.
27. The Shift from Pipeline to Platform
Truth must remain durable and replayable
If Truth cannot reconstruct the system after failures, the architecture becomes operationally fragile.
Intent is more important than most systems realize
Intent is replayability.
Destroying Intent prematurely destroys recovery.
Event-driven systems expose hidden drift faster
Reactive architectures surface infrastructure inconsistencies earlier.
This is painful initially.
But healthier long-term.
Execution must remain reproducible
Replay without reproducibility becomes dangerous.
Control-plane observability matters more than worker observability
Worker crashes are recoverable. Blind reconcilers are not.
Queue depth alone is not truth
Belief metrics require interpretation.
Approximate counts are operational signals, not durable truth.
Policy replay should be designed intentionally
Eventually every ML platform needs deterministic reprocessing.
Replay-native architectures handle this gracefully.
Distributed systems fail by divergence
Not by total outage.
The hardest bugs were:
wrong bucket,
stale AMI,
hidden CORS mismatch,
invisible IAM gap,
frozen replay,
missing Intent.
TBIE helped make those failures explainable.
28. The Future Direction
The current architecture already points toward several future evolutions:
multi-stage event-driven pipelines,
adaptive batching,
warm GPU pools,
richer metrics export,
dynamic replay orchestration,
per-stage autoscaling,
event-sourced workflow history,
tenant-aware media delivery,
replayable policy evolution.
Importantly:
These evolutions do not require rewriting the architecture.
They emerge naturally because reconciliation is already foundational.
That is one of the strongest signs that the architecture direction is correct.
Closing Thoughts
TBIE did not begin as an attempt to create a framework.
It emerged because distributed AI infrastructure repeatedly exposed the same class of operational failures:
work disappearing,
retries becoming impossible,
control planes drifting,
execution environments diverging,
queues losing meaning,
infrastructure behaving correctly against stale assumptions.
The model became useful because it created clarity.
Truth. Belief. Intent. Execution.
Once those boundaries became explicit:
replay became easier,
debugging became faster,
autoscaling became safer,
policy evolution became manageable,
and infrastructure failures became explainable.
The most important lesson from Parjanya v2.0 is not that event-driven architectures are faster.
The deeper lesson is:
Resilient distributed systems are fundamentally reconciliation systems.
The system that survives is not necessarily the one with the fastest workers.
It is the one that can continuously reconstruct:
what is true,
what work should exist,
what execution already happened,
and what still needs to be reconciled.
That is what ultimately transformed Parjanya from a pipeline into a platform.