Intelligent Model Orchestration for AI Agent Systems
Ending the “One Size Fits All” Era of AI Infrastructure (learnings from Distributed systems)


Most teams deploy AI as a single endpoint.
One model.
One cost tier.
One reasoning depth.
That works — until:
Costs spike
Latency increases
Complex tasks fail silently
Critical workloads get underpowered models
Or simple tasks get massively over-engineered
Parjanya 2.0 introduces a smarter pattern:
Treat AI like cloud infrastructure — dynamically route requests to the lowest capable model, enforce SLA rules, and escalate only when necessary.
For startups, small teams, and independent developers, this changes everything.
You don’t need a massive AI budget to build production-grade intelligence.
You need governance.
One Size Fits All Is an Anti-Pattern
In distributed systems, we learned:
One database doesn’t fit all workloads
One instance size doesn’t fit all traffic
One cache strategy doesn’t fit all latency needs
Yet in AI systems?
Teams deploy:
One model. For every request.
This is architecturally wrong.
This has been first-principal at Phagyul AI,
Here is the excerpt “4-Tier Inference Scaling”
Parjanya’s Polyrepo Architecture: Building Scalable AI/LLM Products with Organizational Autonomy (Part 1)

After shipping Parjanya v1.0 through v1.3 (with 17+ patch releases), we’ve evolved from monolithic friction to a deliberate five-repository polyrepo architecture aligned with team structure and technical boundaries. This post documents our research-driven thought process, the specific tech stack (Nx frontend, FastAPI microservices, PyTorch + MIT-license…
Problem Statement
AI Agent Systems at Scale Face:
🚨 Escalating inference costs
🧠 Overuse of frontier models
🐢 Latency variability
❌ Unreliable reasoning on critical workloads
📉 No governance layer
Startups and teams building AI agents are:
Paying hyperscale prices
Without hyperscale orchestration
Market Shift
AI is moving from:
Prompt Engineering —> Multi-Agent Distributed SystemsAgent coding frameworks now:
Call tools
Spawn subtasks
Execute workflows
Interact across repos
Debug and refactor codebases
But routing remains naive.
┌──────────────────────┐
│ AI AGENT HUB │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ ONE LARGE MODEL │
│ (For Everything) │
└──────────────────────┘Problems:
Cost explosion
No workload classification
No SLA awareness
No intelligent escalation
Our Strategy
A Complexity-Aware AI Routing Layer
Instead of one model:
We introduce:
Workload classification
Complexity scoring
SLA enforcement
Budget-aware routing
Confidence-based escalation
AI becomes governed infrastructure.
Architecture Overview
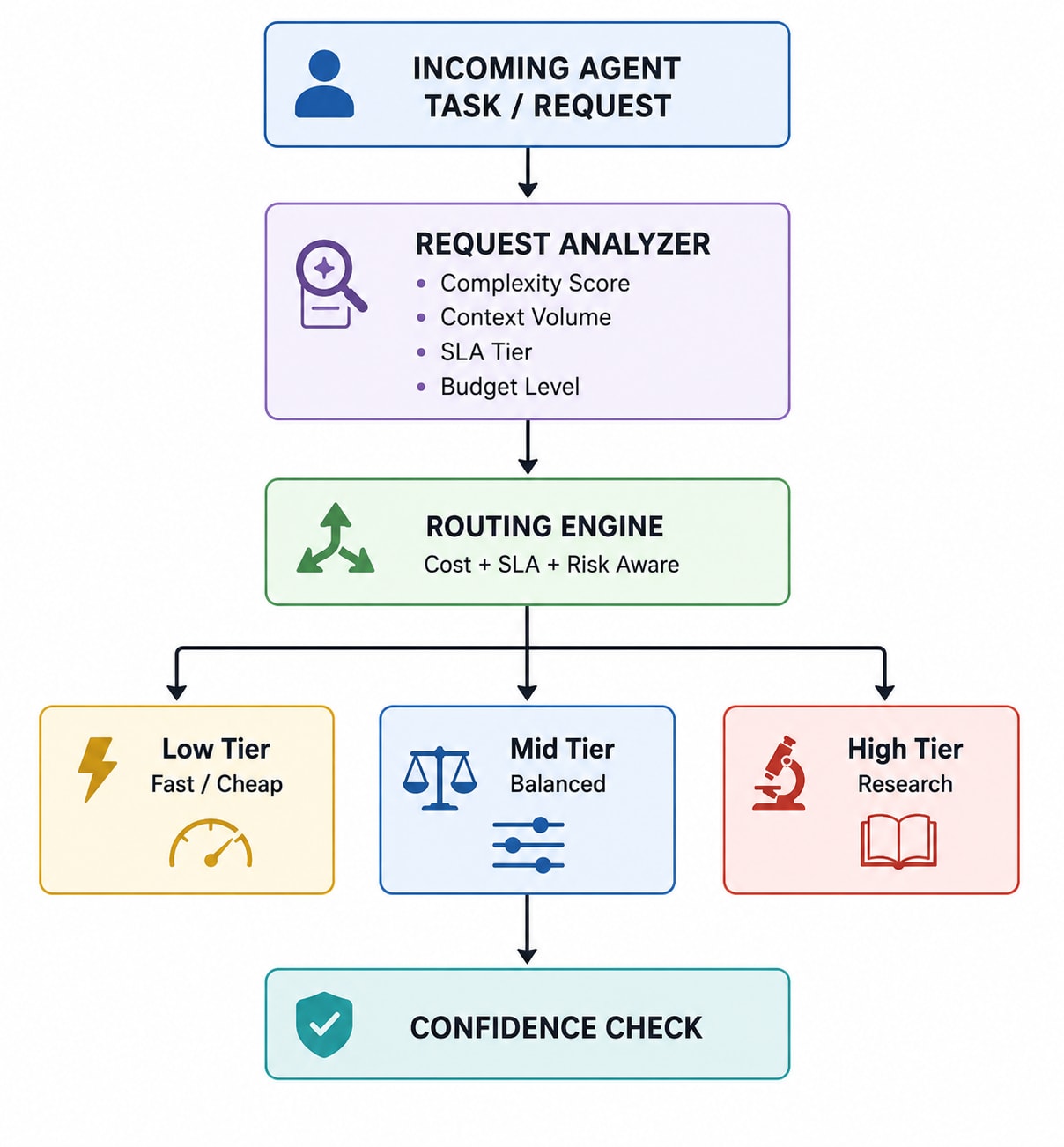
How It Works
Step 1: Compute Complexity (1–10)
Weighted dimensions:
Structural depth
Cognitive reasoning
Context size
Ambiguity
Risk/SLA
Step 2: Route to Lowest Capable Tier
Step 3: Evaluate Confidence
If < threshold → escalate once.
This mirrors:
Auto-scaling
Load balancing
Risk-aware distributed design
The Intelligence: Complexity Computing

Parjanya 2.0 assigns each request a score from 1 to 10.
Complexity = (0.25 × Structural)+ (0.25 × Cognitive)+ (0.20 × Context)+ (0.15 × Ambiguity)+ (0.15 × Risk)
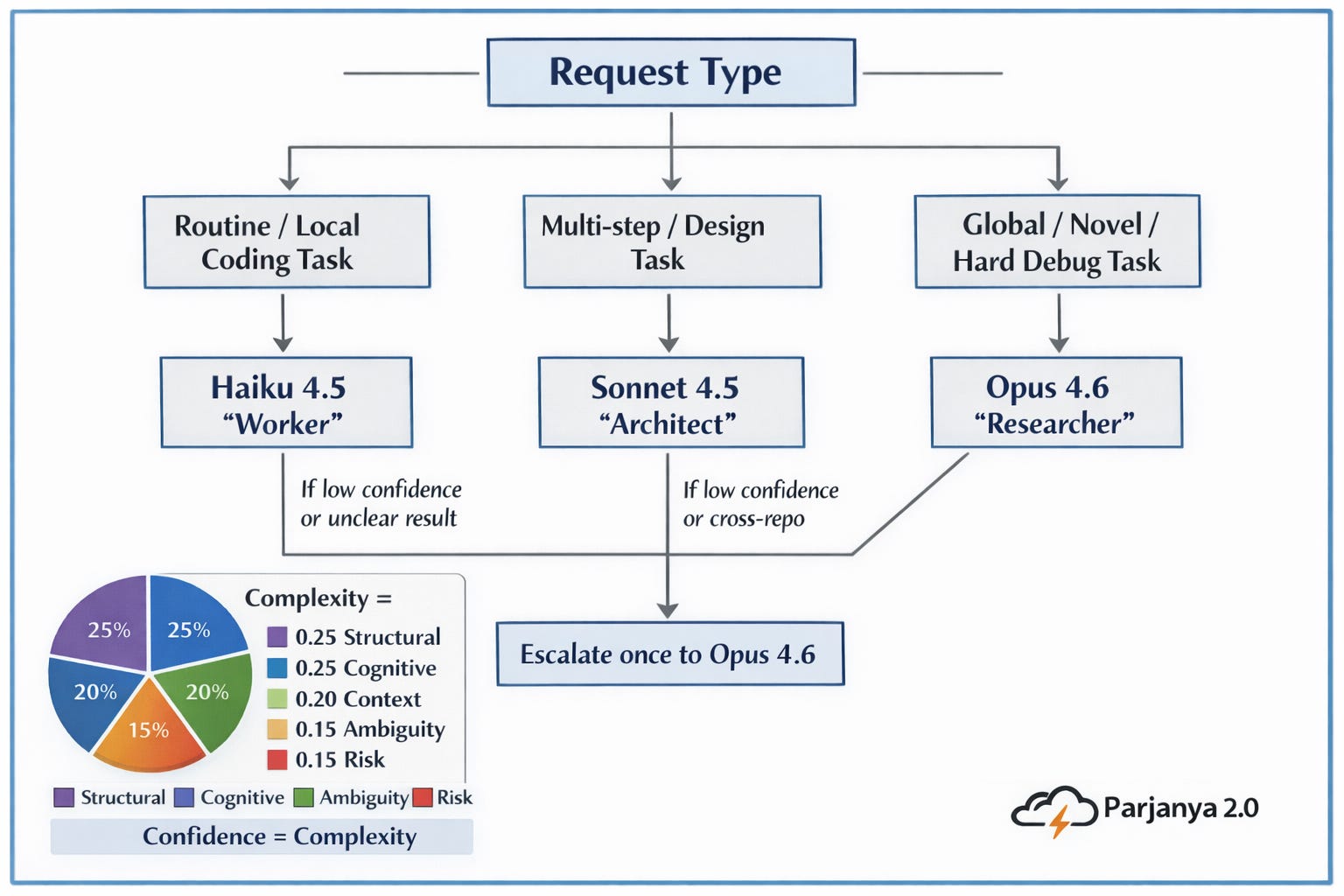
Why This Wins for AI Agent Coding
In agent coding systems:
60% tasks are routine
30% require architectural reasoning
10% require deep research/debug
Yet most systems use high-tier models 100% of the time. I strongly recommend, workload-aware routing.
Sonnet 4.6 Became My New Benchmark for Building an Infra-Heavy VLM Platform

A few months ago, I wrote about why I believed in a Haiku-first strategy: start with the cheapest and fastest model possible, then escalate only when the task genuinely becomes harder. That idea still makes sense in principle.
Winnings(projected)
Typical results:
40–70% cost reduction
25–40% latency improvement
Reduced failure cascades
Predictable SLA compliance
Lower risk in critical flows
Competitive Positioning
| Approach | Problem |
| ----------------------- | ------------------------------- |
| Single-model deployment | Cost inefficient |
| Manual routing rules | Brittle |
| Static tiering | Non-adaptive |
| Parjanya 2.0 | Adaptive, governed, intelligent |We are:
The orchestration layer for AI agent systems.
The routing and governance standard for AI reasoning workloads.

“One model for everything”
is the same mistake as
“One server for all traffic.”
Distributed systems taught us better. AI systems must evolve.
Here are couple of Real world examples
📚 References & Prior Art
Parjanya 2.0 does not emerge in isolation.
It’s architecture is grounded in established distributed systems principles, cloud infrastructure design, and modern AI research.
Below are the key bodies of work that support the orchestration-first approach.
1️⃣ AWS Well-Architected Framework
Authority: Amazon Web Services
The AWS Well-Architected Framework emphasizes workload-aware design and right-sized infrastructure. Two pillars are especially relevant:
Performance Efficiency
Cost Optimization
Core principle:
Select the appropriate resource type and size based on workload characteristics.
This directly parallels model tier selection in AI systems.
Using the most powerful compute for every workload is considered poor architecture in cloud systems — the same logic applies to AI models.
References:
AWS Well-Architected Overview
https://aws.amazon.com/architecture/well-architected/Performance Efficiency Pillar
https://docs.aws.amazon.com/wellarchitected/latest/performance-efficiency-pillar/welcome.htmlCost Optimization Pillar
https://docs.aws.amazon.com/wellarchitected/latest/cost-optimization-pillar/welcome.html
2️⃣ AWS Auto Scaling & Right-Sizing
Authority: AWS Compute Engineering
AWS strongly promotes dynamic scaling and workload-based resource allocation.
Core principle:
Do not statically provision the largest instance for all traffic.
This is structurally identical to avoiding a single frontier AI model for every request.
Reference:
Amazon EC2 Auto Scaling
https://docs.aws.amazon.com/autoscaling/ec2/userguide/what-is-amazon-ec2-auto-scaling.html
3️⃣ AWS Step Functions — Orchestration Pattern
Authority: AWS Serverless Architecture
AWS Step Functions formalizes the separation of orchestration logic from execution logic.
Core principle:
Decouple coordination from execution to improve reliability and scalability.
Parjanya applies this same architectural pattern:
Models perform execution.
The routing layer governs orchestration.
Reference:
AWS Step Functions
https://aws.amazon.com/step-functions/Developer Guide
https://docs.aws.amazon.com/step-functions/latest/dg/welcome.html
4️⃣ AWS Builders’ Library — Load Shedding
Authority: Amazon Engineering
The AWS Builders’ Library provides deep technical insight into how Amazon designs resilient systems.
Particularly relevant:
“Using Load Shedding to Avoid Overload”
Core insight:
Not all requests should be treated equally under stress.
This aligns with:
SLA-tier routing
Critical-path prioritization
Confidence-based escalation policies
Reference:
Using Load Shedding to Avoid Overload
https://aws.amazon.com/builders-library/using-load-shedding-to-avoid-overload/
5️⃣ Google SRE — Service Level Objectives & Error Budgets
Authority: Google Site Reliability Engineering
Google’s SRE model introduced error budgets and differentiated reliability tiers.
Core principle:
Not all traffic deserves equal reliability guarantees.
This supports:
SLA-aware routing
Risk-weighted orchestration
Guardrails for high-sensitivity workloads
References:
SRE Book (Free Online)
https://sre.google/books/Service Level Objectives Chapter
https://sre.google/sre-book/service-level-objectives/
6️⃣ Martin Fowler — Microservices Architecture
Authority: Martin Fowler
Microservices architecture formalized the idea that different services have distinct scaling and performance characteristics.
Core principle:
Avoid monolithic systems; separate concerns based on workload.
Applying this to AI:
Different reasoning tasks require different levels of compute and reasoning depth.
Reference:
Microservices Article
https://martinfowler.com/articles/microservices.html
7️⃣ Mixture of Experts (MoE) — Google Research
Authority: Google Brain
Seminal paper:
“Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer”
This research demonstrates that even inside large neural networks, not all parameters are activated for every input. Instead, tokens are routed dynamically to specialized experts.
In other words:
Frontier AI models themselves reject the “one size fits all” paradigm internally.
Parjanya extends this idea externally — at the system architecture level.
Reference:
Mixture of Experts Paper (arXiv)
https://arxiv.org/abs/1701.06538
8️⃣ AWS Bedrock — Multi-Model Strategy
Authority: AWS AI/ML
AWS Bedrock promotes selecting foundation models based on workload characteristics and cost/performance tradeoffs.
Core principle:
Model selection should be contextual.
Reference:
Amazon Bedrock
https://aws.amazon.com/bedrock/
9️⃣ LangChain — Routing & Agent Orchestration
Authority: LangChain
LangChain includes explicit routing constructs for selecting chains, tools, or agents based on task classification.
Core principle:
AI systems require orchestration layers, not monolithic execution.
Reference:
Routing Use Cases
https://python.langchain.com/docs/use_cases/routing/
🔟 Microsoft Semantic Kernel — Planning & Skill Routing
Authority: Microsoft AI
Semantic Kernel introduces planners and skill orchestration for AI workflows.
Core principle:
Complex AI applications require controlled coordination between components.
Reference:
Semantic Kernel Documentation
https://learn.microsoft.com/en-us/semantic-kernel/
Distributed systems engineering has long rejected monolithic resource allocation.
Cloud architecture evolved to embrace:
Workload-aware scaling
Cost optimization per task
SLA differentiation
Orchestration layers
Risk-aware decision systems
Modern AI systems are now at a similar inflection point.
Parjanya 2.0 applies proven distributed systems principles to AI reasoning infrastructure — transforming model selection from a static choice into a governed, adaptive system.
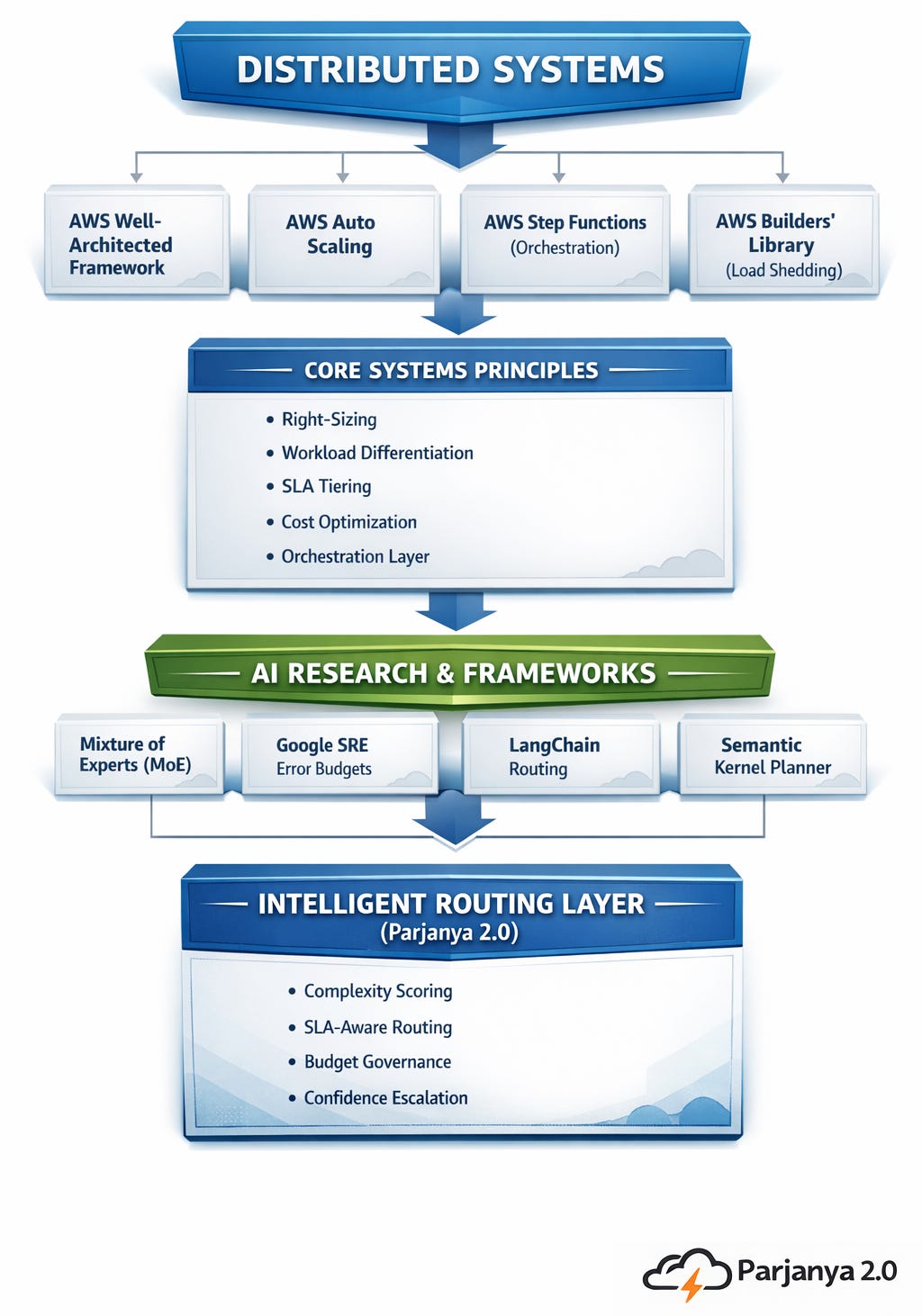
How Parjanya Extends Prior Art
The works cited above establish a consistent architectural truth: distributed systems must be workload-aware, cost-sensitive, and reliability-governed.
However, most AI systems today still operate as monoliths — routing every request to a single model tier without classification, SLA differentiation, or escalation control.
Parjanya 2.0 extends prior art by:
Applying right-sizing principles to AI model selection
Externalizing orchestration beyond the model layer
Introducing complexity scoring as a governance mechanism
Enforcing SLA-aware routing policies
Implementing confidence-based escalation guardrails
In essence:
Cloud systems evolved from static provisioning to intelligent orchestration.
Parjanya applies that same evolution to AI reasoning infrastructure.
It transforms AI from a single endpoint into a governed, distributed system.