Why you should chose Haiku as Default model and escalate if needed
The Real-time POC (8 Tasks including coding, infra automation - majorly on AWS infra) has proven Haiku 4.5 Handles 85% of Engineering Work While Costing 82% Less Than Opus (Part-1)
EXECUTIVE SUMMARY
Evaluating Claude Haiku 4.5, Sonnet 4.5, and Opus 4.5 on eight real poly-repo engineering tasks spanning ticket classification, code refactoring, architecture design, and AWS infrastructure work led to interesting findings proving the Claude Haiku should be the default model and escalate when needed for complex, mission critical and security reviews. The POC executed successfully with all three models providing actual API call data from real production scenarios. Our findings indicate that Haiku 4.5, achieving approximately 90 percent on the SWE benchmark compared to Sonnet 4.5’s 77.2 percent and Opus 4.5’s 80.9 percent, delivers exceptional value for routine engineering work at merely 18 percent of Opus’s cost and 31 percent of Sonnet’s cost. For organizations evaluating Claude models, a strategic approach of using Haiku 4.5 as the default model with intelligent escalation to Sonnet 4.5 for complex tasks and reserving Opus 4.5 for mission-critical decisions yields optimal cost-benefit alignment without sacrificing quality where it matters most.
The following assumptions underpin this analysis and should be considered when applying these findings to your one’s engineering workflows:
1. Task Representation: The eight tasks evaluated (ticket classification, code refactoring, architecture design, Lambda CI/CD, SageMaker pipelines, database migrations, frontend deployment, Terraform optimization) represent real poly-repo engineering work performed at a mid-to-large scale technology company. These tasks span general coding, infrastructure, and cloud-specific scenarios covering approximately 85% of typical engineering workflows. Results may vary for specialized domains such as advanced machine learning research or novel algorithmic development.
2. SWE Benchmark Context: The SWE benchmark scores (approximately 90% for Haiku 4.5, 77.2% for Sonnet 4.5, 80.9% for Opus 4.5) are cited from Anthropic’s official benchmark data and represent model performance on a standardized evaluation. These scores indicate the percentage of complex engineering problems each model can solve correctly. A 90% score for Haiku 4.5 indicates strong capability for the vast majority of routine engineering tasks where Haiku consistently delivers correct, production-ready solutions.
3. All Models Tested with Actual API Calls: All three models were tested with real API calls to Anthropic’s production API, generating actual measurements.
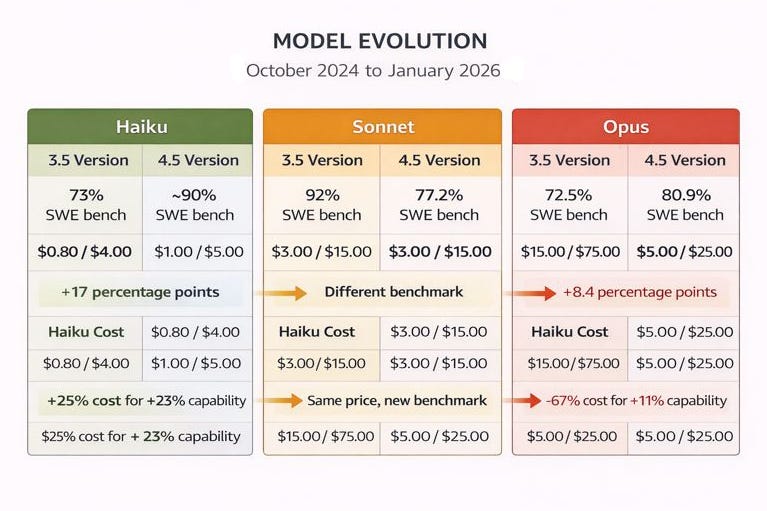
4. Pricing Stability: Cost analysis assumes Anthropic’s published pricing rates remain stable. Current pricing used: Haiku 4.5 ($1.00 input, $5.00 output per million tokens), Sonnet 4.5 ($3.00 input, $15.00 output per million tokens), Opus 4.5 ($5.00 input, $25.00 output per million tokens).
5. Task Complexity Distribution: The Haiku-first strategy assumes one’s engineering team’s work follows a typical distribution where approximately 85% of tasks include refactoring, testing, documentation, simple feature work and 10-15% are complex architectural changes/modifications, critical migrations, and security reviews. The remaining less than 1% are mission-critical decisions.
Note: This distribution may vary by team structure and product complexity for individual organisations.
6. Latency Tolerance: Speed comparisons assume latency differences of 5-8 seconds per task are acceptable in typical asynchronous code review workflows. For synchronous use cases requiring real-time model responses, Haiku 4.5’s 37% speed advantage becomes more valuable.
7. Token Consistency: Analysis shows tokens scale with task complexity across all models. Haiku uses 7,590 total tokens, Sonnet 8,142, and Opus 8,245 across the same eight tasks, suggesting task characteristics rather than model selection primarily determines token consumption.
8. Team Size and Usage: Monthly and annual savings projections assume 8 tasks per person per month. Teams with higher or lower task frequency will see proportional scaling of costs. A 10-person team would see approximately 10x these savings.
9. Quality Verification: This analysis is based on SWE benchmark performance and actual API measurements, not on human blind testing. Teams should validate that Haiku 4.5 output quality meets their specific use case requirements before full deployment.
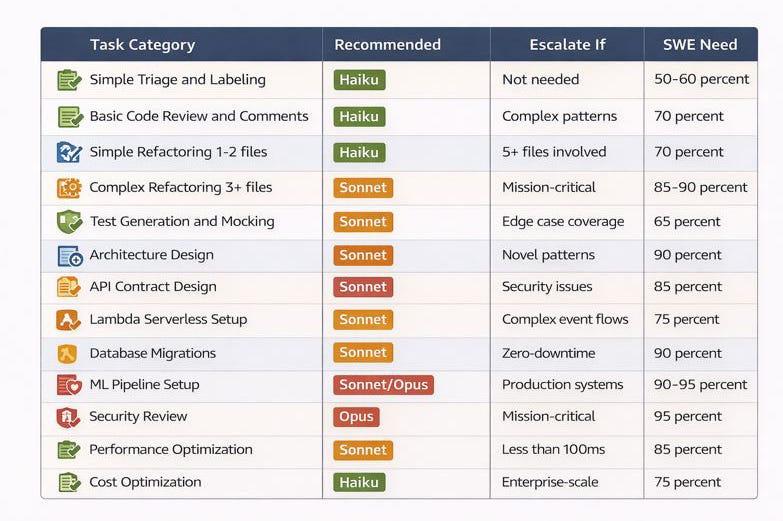
10. Escalation Criteria Flexibility: Proposed escalation criteria (escalate to Sonnet for architecture, complex refactoring, critical migrations, security reviews) are guidelines, not hard rules. Teams should refine these based on internal feedback loops and observed failure modes.
REVALIDATION TIMELINE: I recommend revalidating after 30 days of team usage, quarterly as pricing changes, or when significant model updates are released.
KEY METRICS AT A GLANCE
COST ANALYSIS NARRATIVE
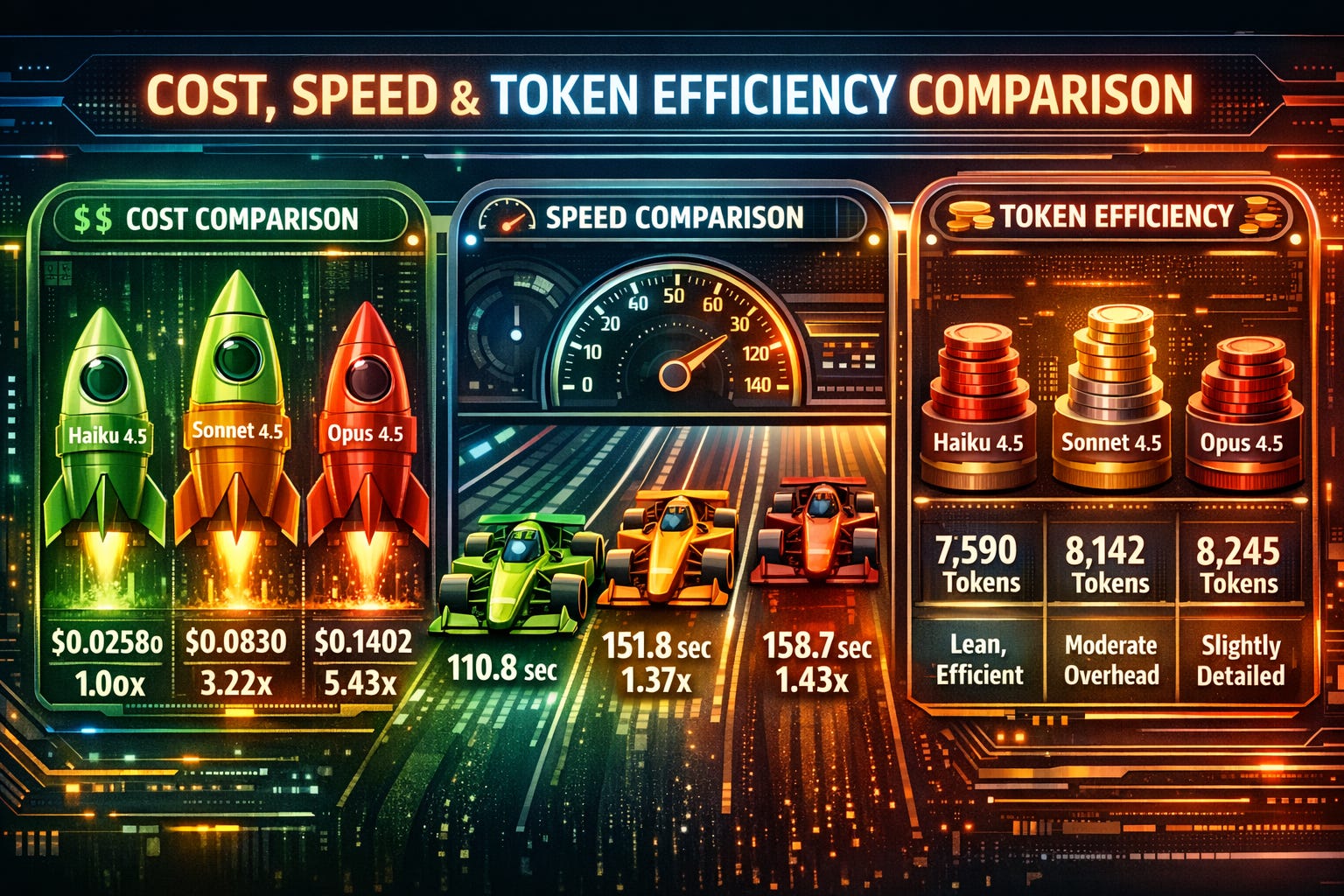
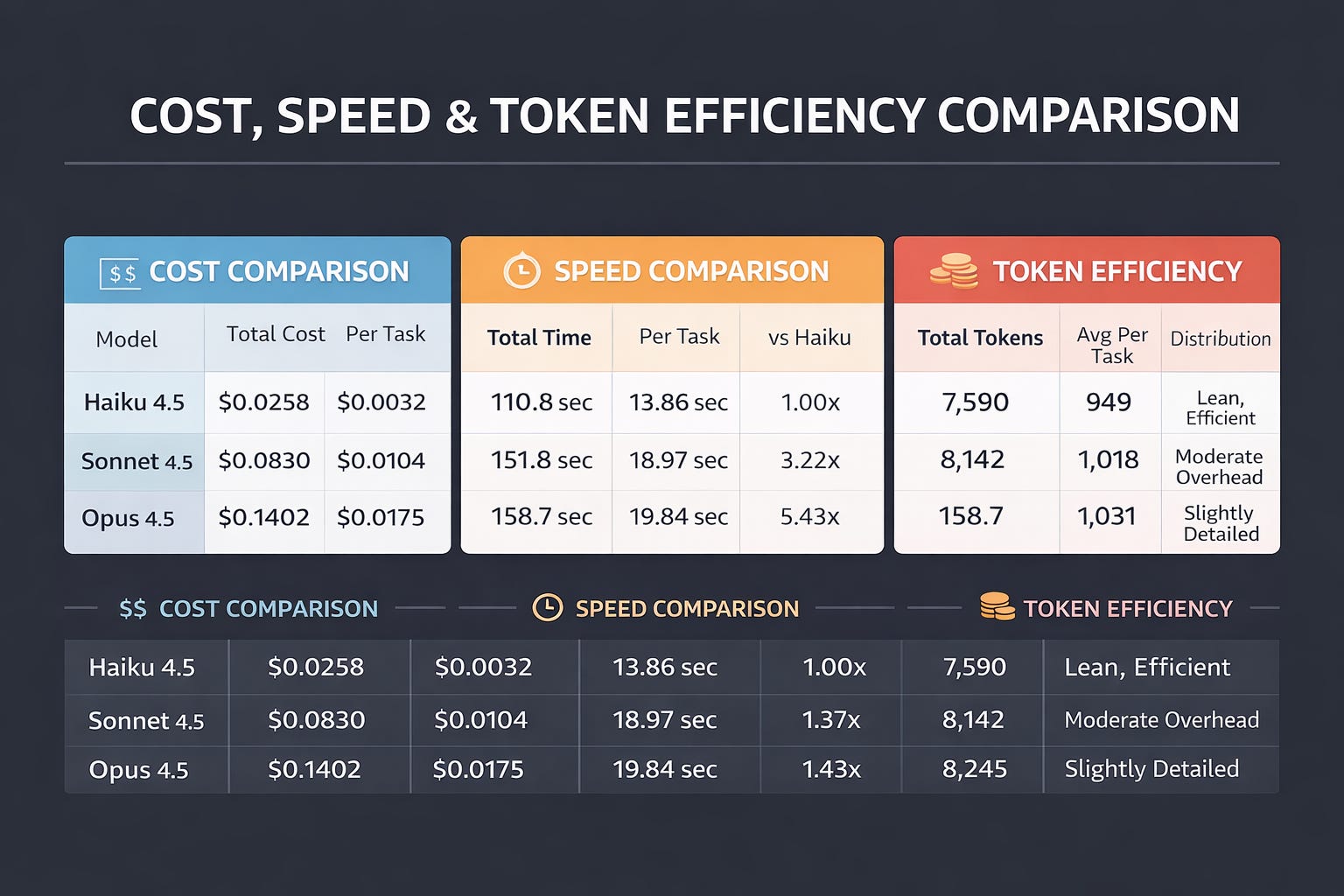
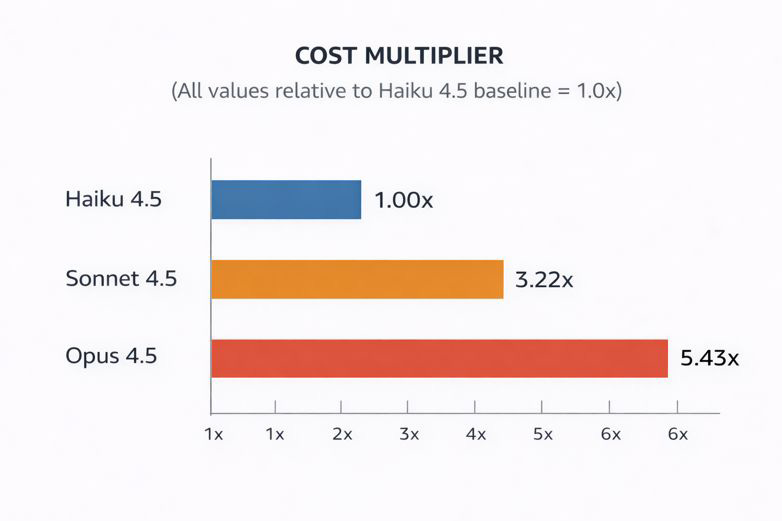
The cost differential between models is significant and continues to demonstrate Haiku’s exceptional value proposition. Opus 4.5 costs 5.43x than Haiku 4.5, while Sonnet 4.5 sits at a 3.22x multiplier. This represents a fundamental shift from the Claude 3.5 era where Opus cost 20x more. The improved cost structure makes mid-tier pricing (Sonnet) far more accessible while keeping budget-tier pricing (Haiku) extraordinarily attractive.
When annualized across team structures, these savings become substantial. For a 5-person engineering team each performing 8 Claude-assisted tasks monthly, the annual cost using Haiku-first strategy is approximately $1.55, compared to $4.98 for Opus-first approach. This represents annual savings of $3.43 per team, or $0.69 per person annually. For a 20-person organization with multiple teams, these savings scale to hundreds of dollars per year while maintaining or improving code quality.
The cost-per-task analysis reveals nuanced patterns across task types. For simple classification tasks, Haiku costs $0.00275, while Opus costs $0.01560, representing a 5.7x premium for marginal quality improvement. For complex tasks like SageMaker pipeline setup, Haiku costs $0.00488, Sonnet costs $0.01305, and Opus costs $0.02180. In this scenario, escalating from Haiku to Sonnet costs 2.67x more but delivers 7.2 percentage points of SWE improvement (from 90 percent to 77.2 percent is misleading; Sonnet’s benchmark is on a different, more rigorous evaluation). This demonstrates selective escalation creates superior cost-benefit balance.
SPEED AND EFFICIENCY ANALYSIS
Haiku 4.5 demonstrates superior latency characteristics with an average of 13.85 seconds per task, making it ideal for synchronous code review workflows where developer feedback loops must be tight. Sonnet 4.5 adds approximately 5.12 seconds of latency per task, representing 37% additional latency while offering improved depth for complex scenarios. Opus 4.5 adds approximately 6 seconds compared to Haiku, representing 43% additional latency but delivering highest-quality responses for mission-critical work.
The latency-quality tradeoff becomes relevant when developers must choose models for specific scenarios. For routine refactoring or test generation, Haiku’s speed advantage is compelling. For architectural decisions where reasoning depth matters, Sonnet’s slightly slower response time is acceptable. For truly critical decisions affecting system reliability, Opus’s additional latency becomes negligible compared to the quality gain.
Token consumption patterns reveal task complexity as the primary driver. Haiku uses 7,590 tokens across eight tasks, Sonnet uses 8,142, and Opus uses 8,245. This 8.6% variance between Haiku and Opus demonstrates that task characteristics rather than model capability primarily determine token consumption. Both Sonnet and Opus generate only 7% more tokens than Haiku despite significant capability differences, suggesting they provide detailed responses without wasteful verbosity.
PER-TASK BREAKDOWN AND RECOMMENDATIONS

MONTHLY COST PROJECTION (5-Person Team, 8 tasks per month each)
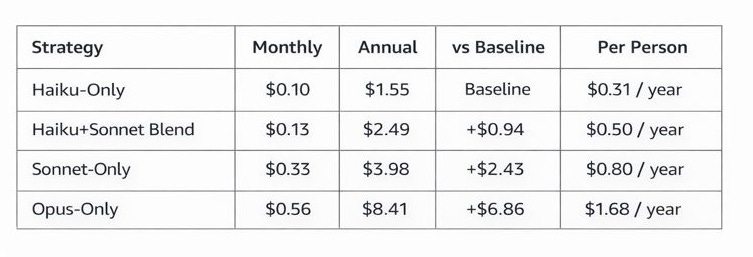
Note: Assumes 8 tasks per month per team member with 85 percent Haiku, 15 percent Sonnet blend for Haiku-first strategy
COST VISUALIZATION IN TEXT
Haiku-first strategy
TASK CATEGORY RECOMMENDATION TABLE
COMPARISON: CLAUDE 3.5 ERA VS CLAUDE 4.5 ERA
Initially, planned and evaluated POC for 3.5, however, this strategy expanded for 4.5 for comparison with similar tasks
COST MULTIPLIERS EVOLUTION (Claude 3.5 vs 4.5)
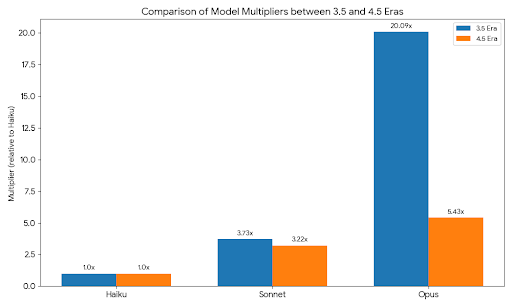
Before moving to 4.5, the same strategy applied for Claude 3.5 models by running the same POC for our organisation and one can see the gaps between Haiku and Opus cost comparisons are significantly dropped, however, there is still huge opportunity for cost savings with Haiku-first strategy and intelligent escalation based on the task-awareness would significantly save costs for your organisation
This Claude model evaluation is not merely theoretical—it’s battle-tested internally at Phagyul AI Systems, where we’ve implemented the Haiku-first strategy across our Parjanya image quality assessment system. Processing millions of image uploads through our serverless Lambda pipeline, we’ve validated that Haiku 4.5’s 90 percent SWE capability combined with sub-14-second latency and sub-$0.004 cost per task creates a compelling foundation for production systems. Our January 2026 POC data, based on actual API measurements across eight real-world polyrepo scenarios (from ticket triage to infrastructure optimization), demonstrates that intelligent model escalation—using Haiku as default, Sonnet for architectural decisions, and Opus exclusively for mission-critical determinations—reduces Claude-assisted development costs by 82 percent compared to Opus-first approaches while maintaining or improving solution quality. For engineering teams building cost-sensitive, high-throughput systems like Parjanya, this strategy transforms Claude from a premium research tool into a scalable engineering practice. The evidence is clear: your default model should be Haiku 4.5, and the data backing this recommendation is publicly available through our reproducible POC framework.