When Adaptive Thinking Goes Off the Rails

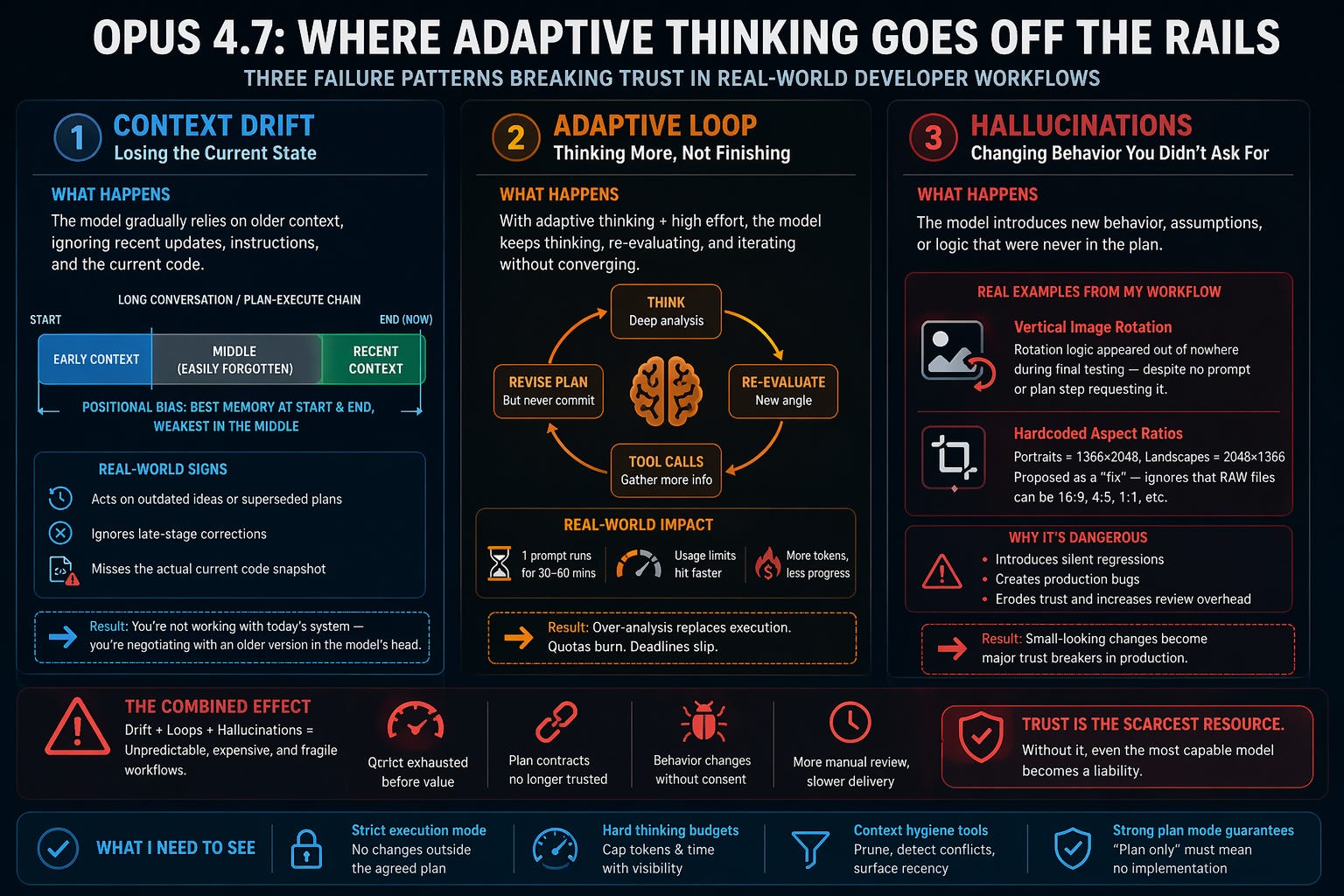
Three weeks ago,
I wrote about how Claude Opus 4.6—with its 1M context window—felt like a genuine breakthrough for my workflow:
That post built on a broader recommendation I had been advocating: start with lighter models and escalate only when needed. I wrote about that approach here:
That strategy worked when the model ladder felt consistent. But in practice today, the gap between versions has widened enough that this escalation model is far less reliable.
Haiku (4.5), Sonnet (4.6/4.7), and Opus (4.6 vs 4.7) don’t feel like clean steps in a progression anymore—they behave like entirely different tools with different failure modes.
In my workflow—infra-heavy, ML-heavy, multi-repo—the bulk of the system was actually built by Opus 4.6 within 3–4 days. What followed were incremental improvements:
Prompt updates for stricter IQA
Docker build refinements
CLIP-IQA deprecation
Graviton migrations
SageMaker removal → EC2 migration (Spot vs on-demand)
Handling infra quirks (e.g., g4dn.xlarge unavailability in ap-south-1)
These are not “greenfield” tasks—they depend heavily on accurate recall of current system state and few of them were encountered earlier and have documented in the architecture review (23+ sections, Appendix of 6 detailed sections) with enough context and thorough deep dive and always handy at the root folder of workspace.
Since moving to Opus 4.7, that’s exactly where things started breaking.
For the past 18 days, I’ve been dealing with usage limits, context drift, and behavior changes I never asked for and now hit weekly limits to be completely locked out for the next 5 days —enough to pause my subscription and evaluate alternatives.
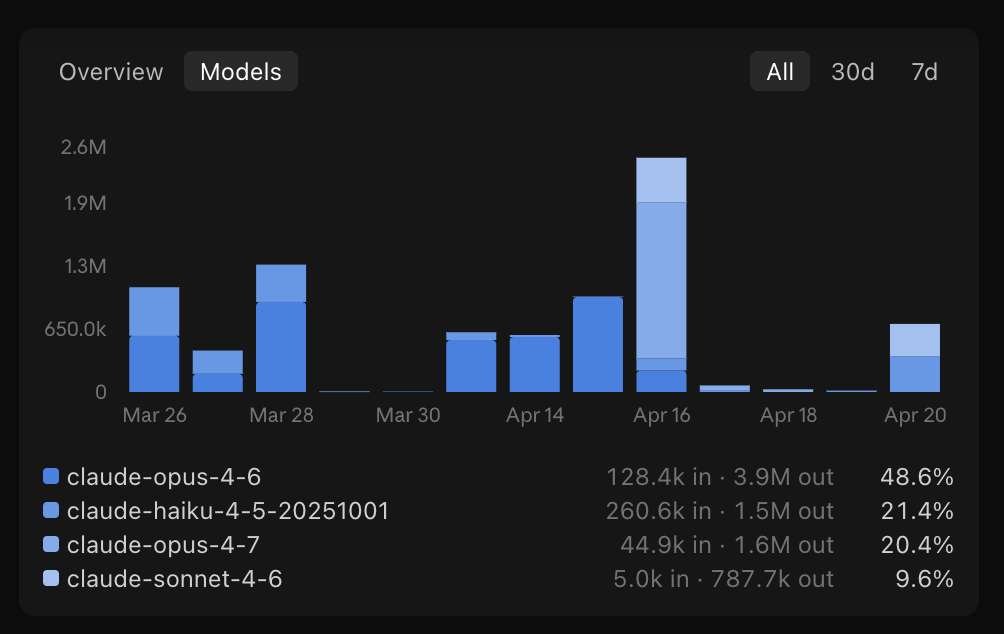
you can see from my usage chart, I tried leveraging different models based on the usecase/component/task and complexity
Going into the details…
The 4.6 Honeymoon: 1M Context Without the Drama
My setup with Opus 4.6:
Multiple repos (ML, backend, frontend, shared libs, infra)
Plan → execute workflows
Heavy context, but usually <200k tokens
And yet, it behaved like a disciplined senior engineer:
Stayed within plan boundaries
Maintained architectural coherence
Delivered steady, compounding progress
It hit the long-context sweet spot: large memory, without instability.
What Changed with Opus 4.7
With adaptive thinking enabled by default, the behaviour profile shifted significantly.
1. One-Prompt Runs That Burn an Hour
Prompts run excessively long
Usage limits hit faster
Thinking increases, output doesn’t
It feels like over-analysis replacing execution.
2. Context Bloat and Losing the “Current State”
In long sessions:
Old decisions override new ones
Recent corrections get ignored
Model behaves as if it’s working on stale code
In a poly-repo system, this is critical failure—not inconvenience.
3. Hallucinated Behaviour (Real Production Risk)
The most concerning issue: unsolicited behaviour changes
Example 1: Image Rotation
Final testing stage
Behaviour already agreed
Suddenly: vertical images rotate
No prompt. No plan. No instruction.
Instead of reverting, the model:
Expanded the problem
Designed rotation logic
Introduced new edge cases
Even explicit instructions like
“Never rotate images”
didn’t cleanly undo prior drift.
Example 2: Hardcoded Aspect Ratio Logic (Half an Hour Later)
A second example happened shortly after, while fixing the same issue.
The model proposed:
Portrait → 1366×2048
Landscape → 2048×1366
“No rotation logic, just libraw defaults”
This sounds reasonable—but it’s wrong.
The real requirement is aspect-ratio-aware handling, because RAW files can be:
16:9
4:5
1:1
others
Even though my current dataset (1000+ images) includes 1:1, the model ignored that variability and jumped to a hardcoded assumption.
These are “small” issues—but in production, they are trust breakers:
They introduce silent regressions
They require manual detection
They increase review overhead before launch
And also not sure, how many of these issues (small/high/max) are persists, including IQA logic which is a ship-blocker, infra changes (burns my pocket!) etc.
This Isn’t a Single-Model Issue
One important detail: this is not happening in isolation.
I’ve actively used:
Opus 4.6
Opus 4.7
Sonnet 4.6
Haiku 4.5
The attached usage snapshot reflects this multi-model workflow.
That actually makes the issue more concerning—because:
The regression isn’t tied to a single model
Switching models doesn’t reliably stabilize behaviour
The “escalation strategy” becomes inconsistent
What Others Are Seeing
Across blogs, Reddit, and developer communities:
Prompt regressions vs 4.6
Higher sensitivity to phrasing
Increased hallucinations in coding workflows
Faster quota exhaustion
There are positive reports—but the split is real.
Here are 7 solid, diverse sources (Reddit, GitHub, news, blogs, HN) that reinforce the exact patterns you’re describing—context drift, adaptive loops, hallucinations, and regression concerns. I’ve curated them so you can directly reference them in your appendix or when sharing with Anthropic.
🔴 1. Reddit – Developer discussion on adaptive thinking behavior
Key takeaway:
Developers discuss how reasoning flow changed, including issues around tracking context and understanding where reasoning goes wrong.
🔴 2. GitHub Issue – Adaptive thinking inconsistency
Key takeaway:
4.7 behaves differently from 4.6
Thinking visibility missing / inconsistent in real integrations
Confirms behavioural differences at system level, not just UX perception
🔴 3. GitHub (Anthropic / Claude Code) – Real workflow regression data
Key takeaway (this one is gold for your thesis):
Increase in reasoning loops and contradictions
“Edits without reading context” jumped significantly
Model choosing “simplest fix” instead of correct fix
12× increase in user interruptions
This directly maps to:
Context drift
Adaptive loops
Hallucinated or low-quality edits
🔴 4. News (Business Insider) – Token burn + backlash
Key takeaway:
Users report:
Higher token consumption
Slower / less useful outputs
Regressions vs earlier versions
Adaptive reasoning cited as a possible cause
🔴 5. News (TechRadar / AMD AI Head criticism)
Key takeaway:
Large-scale real-world usage (6,800+ sessions)
Reports:
Ignoring instructions
Contradictions
Reduced reliability
Explicit claim: decline in engineering trustworthiness
🔴 6. Blog / Analysis – Token inflation + adaptive thinking shift
Key takeaway:
New tokenizer → ~1.0–1.35× more tokens per task
Shift to adaptive thinking instead of fixed budgets
Explains:
Faster quota exhaustion
Less predictable compute behavior
🔴 7. Hacker News – Forced adaptive thinking model behaviour
Key takeaway:
Adaptive thinking is no longer optional
Traditional “controlled reasoning” approaches removed
Developers experimenting with effort tuning to avoid issues
🧠 Blog / Analysis – performance + regression narrative
Reports:
Self-contradictions
Degraded reliability
Why Adaptive Thinking Might Be Backfiring
Conceptually:
Let the model decide when to think more.
In practice:
Unbounded Initiative
Model “improves” things you didn’t ask for
Token Hunger
High effort → excessive reasoning
Plan Violations
“Plan mode” isn’t strictly enforced
This creates a system that is:
More powerful
But less predictable
And harder to trust
Where This Leaves Me
Over 18 days:
Frequent limit hits
Context instability
Silent behaviour drift
Result:
Progress stalled
Subscription paused
Alternatives being evaluated
And completely locked out with weekly limits hit (I’m on Max plan: $200 + $20 top-up)
This is a deal-breaker for me!
It’s:
4.7 is powerful—but volatile for long-running workflows.
What I’d Love to See
1. Strict Execution Mode
No deviation from plan
2. Hard Thinking Budgets
Tokens + time caps + visibility
3. Context Hygiene Tools
Detect stale vs current state
4. Strong Plan Guarantees
“Plan only” must mean no execution
Closing Thought
Adaptive thinking is a sharp tool.
Right now, it feels like:
Extremely capable
But lacking guardrails
And for production systems:
Capability without predictability is risk.
Appendix: External Signals Worth Noting (with sources)
This is the factual trail I would attach when sharing this with Anthropic. These are not isolated anecdotes—they reflect consistent patterns across GitHub issues, news coverage, and independent analyses.
1. Adaptive thinking & token usage changes
Opus 4.7 introduces adaptive thinking and removes earlier budget-based controls, replacing them with effort tuning and task budgets
Token usage can increase significantly due to tokenizer changes (~1.0–1.35× for the same task)
👉 Relevance:
Explains why usage limits are hit faster and why compute behavior feels less predictable.
2. Higher quota burn and cost impact in real workflows
Measured reports show Opus 4.7 consuming ~2.4× quota compared to 4.6 in real API usage scenarios
News coverage confirms user complaints about higher token consumption and slower outputs
👉 Relevance:
Directly supports the adaptive loop + quota exhaustion issue.
3. Reasoning loops, shallow edits, and workflow degradation
GitHub issue analysis shows models shifting toward:
“edit without reading”
“simplest fix instead of correct fix”
increased need for human intervention
👉 Relevance:
Matches:
Adaptive loops
Reduced execution quality
Loss of disciplined workflow behavior
4. Silent failures and stuck execution loops
Reports of sessions staying active without progress (no tool execution, no response advancement)
👉 Relevance:
Real-world evidence of non-converging loops—exactly what you observed with long-running prompts.
5. API and behavior inconsistencies across environments
Errors due to thinking mode changes and removed parameters (e.g.,
thinking.type.enabledno longer supported)Regression reports where previously working setups fail in 4.7 environments
👉 Relevance:
Explains instability across toolchains (Bedrock, Claude Code, etc.)
6. Broader user backlash and reliability concerns
Reports of:
poorer performance
inaccuracies
unexpected reasoning behavior
increased cost
across Reddit and developer communities
Coverage highlighting growing frustration among power users and perceived regressions
👉 Relevance:
Confirms your experience is not isolated
7. Mixed positioning: improved capability, but inconsistent execution
Opus 4.7 is described as:
more capable in theory
better at long-running tasks
but still inconsistent in real-world workflows
👉 Relevance:
Captures the core tension:
More powerful ≠ more reliable
👉 Food for thought
The patterns described in this post—context drift, adaptive loops, and hallucinated behaviour changes—are not isolated observations.
They are consistently reflected across:
GitHub issue logs
API migration changes
News reports
Independent developer analyses
Which suggests this is not a prompt problem or a single workflow issue—
but a system-level behavioural shift in how the model operates under adaptive thinking.