The Hidden Runtime Failure Behind Claude’s Recent Regression

For a few weeks, Claude Code got noticeably worse.
It wasn’t subtle.
It read less code.
It reasoned less deeply.
It stopped early.
And yet—nothing “official” had changed.
When Anthropic finally published their postmortem, they called it a set of bugs.
After digging through the data and my own usage, I don’t think that tells the full story.
Adaptive Thinking Gone Wrong
Why Claude’s Silence Broke My Trust
For months, Claude Code with Opus 4.6 was the backbone of my engineering workflow.
With Opus 4.7—and the rise of “adaptive thinking”—that same assistant began to feel unreliable, opaque, and, most concerning of all, quietly downgraded.
Anthropic’s April 23 postmortem confirmed something many of us already felt: Claude Code did get worse for weeks.
https://www.anthropic.com/engineering/april-23-postmortem
But the explanation—and the framing—left me with a deeper concern:
This wasn’t just a bug. It was a runtime failure of adaptive thinking.
This is a first-person account of what changed, what the data shows, and why this moment broke trust for me—even though I’m still not walking away.
1. When It Worked: Opus 4.6 as a Force Multiplier
My earlier experience with Opus 4.6 was very interesting.
Claude Code behaved like a senior engineer embedded in my workflow:
It read deeply before editing
It maintained context across long sessions
It handled multi-step refactors with caution and coherence
Under the hood, this was already powered by adaptive thinking—a system that dynamically allocates reasoning effort per task.
But here’s the key:
It worked quietly and reliably.
2. When It Broke: Opus 4.7 Regression
With Opus 4.7, the experience flipped.
What I observed:
Shallower reasoning
More hallucinated structure
Premature stopping or avoidance
Worse tool usage
Increased repetition
All while adaptive thinking was being positioned as the primary reasoning mode.
At the same time:
Usage limits tightened
Sessions became less predictable
From a user perspective:
It felt like a silent downgrade.
3. Anthropic’s Explanation
https://www.anthropic.com/engineering/april-23-postmortem
Anthropic attributes the regression to three issues:
Effort downgrade (March 4)
Default reasoning dropped from high → medium
Thinking cache bug (March 26)
Thinking history cleared after idle periods
Verbosity constraint (April 16)
Artificial limits reduced output quality
All three are now reverted.
Their position:
The model wasn’t degraded—only the application layer was.
4. What the Data Shows
Independent telemetry and analysis revealed:
Files read before editing: 6.6 → 2.0
Thinking length: ~2200 → ~600 characters
Stop/avoidance behaviors: spiked significantly
These are not isolated anomalies.
They indicate systemic changes in:
Reasoning depth
Context retention
Decision consistency
5. The Real Problem: A Runtime Failure
All three issues converge on one layer:
Adaptive thinking at runtime
Lower effort → less reasoning
Cache bug → lost reasoning
Verbosity cap → suppressed reasoning
This creates a cascade:
Adaptive Thinking Failure Chain
6. Why the Framing Matters
Anthropic’s framing:
“A few issues, now fixed”
User reality:
“Core reasoning behaviour degraded for weeks”
That gap is where trust erodes.
Because for power users:
The runtime layer is the product
7. Bad Timing Made It Worse
This regression coincided with:
Tighter usage limits
Pricing pressure toward higher tiers
Source-code leak incident
Mythos leak
Together:
Reduced capability + reduced transparency + increased constraints
8. Why I’m Still Using Claude
I’m not leaving.
Because when it works:
It’s still one of the best engineering copilots available.
To Anthropic’s credit:
Detailed postmortem
Fixes implemented
Public acknowledgment
But:
Benefit of the doubt ≠ restored trust
9. What Needs to Change
To rebuild trust, adaptive thinking must become:
Observable
Expose reasoning allocation
Controllable
Allow effort overrides
Stable
Test long-session behavior
Transparent
Treat runtime changes like model updates
Final Thought
Adaptive thinking isn’t just a feature.
It is the system between the user and the model.
When that system changes silently:
Behaviour shifts
Expectations break
Trust erodes
I’ll keep using Claude.
But not as a black box anymore. In fact, exploring the options like Orchestrators like a battle-tested Cursor code and in future LiteLLMProxy along with Claude, gpt-4o, Gemma4:31b and Qwen-3.6 and/or Kimi k2.6
This is the simplest way to understand what actually broke:
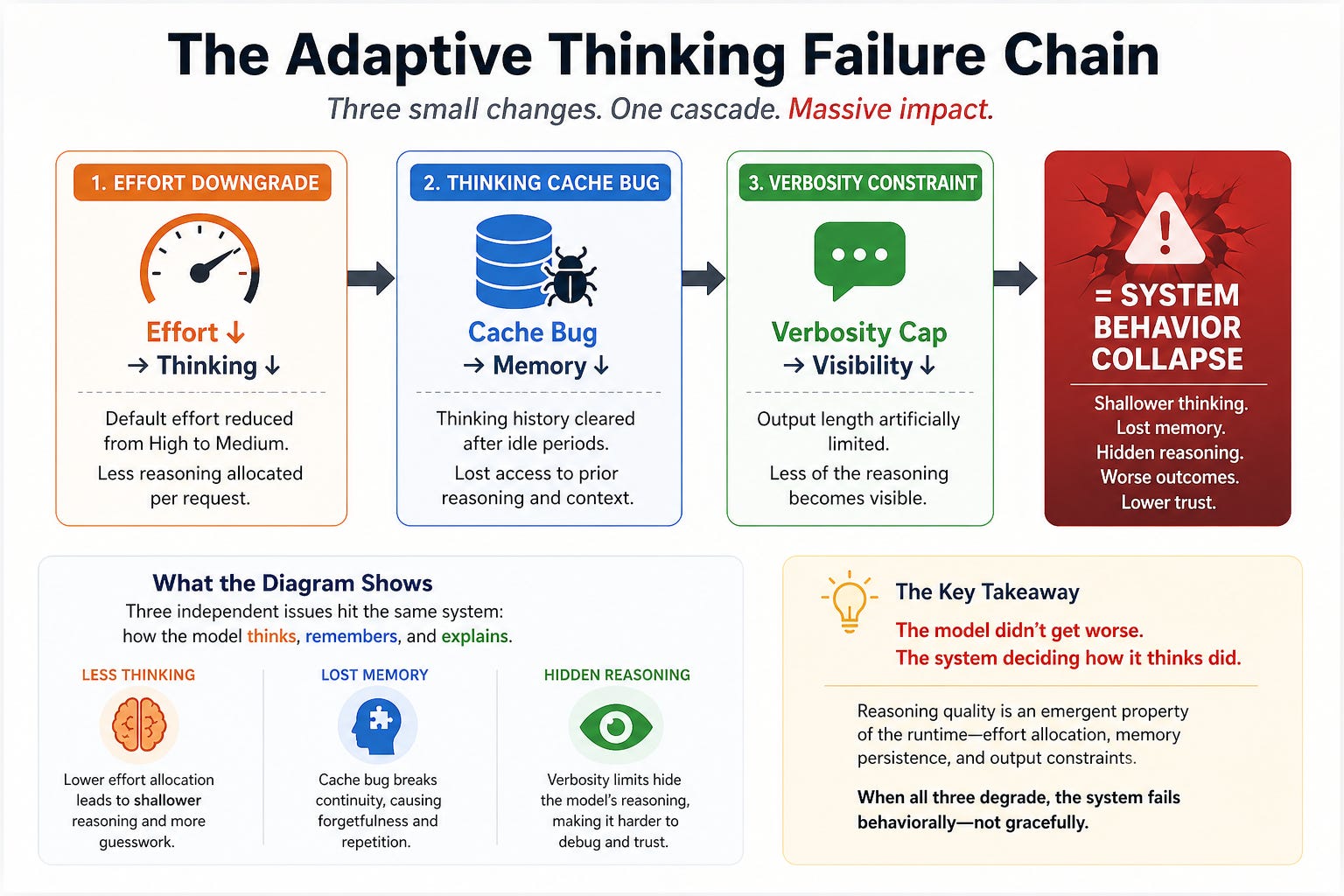
What the Diagram Shows
At first glance, these look like three unrelated issues:
Effort downgrade
Cache bug
Verbosity constraint
But they all hit the same underlying system:
How the model thinks, remembers, and explains
The Chain Reaction
Effort ↓ → Thinking ↓
Cache Bug → Memory ↓
Verbosity Cap → Visibility ↓
= System Behavior CollapseEach step compounds the next:
Less effort → shallower reasoning
Broken cache → lost continuity
Lower verbosity → hidden reasoning
Individually manageable.
Together:
A collapse in perceived intelligence
Why This Matters
From a system design perspective, this is the real insight:
Reasoning quality is not just a model property.
It is an emergent property of the runtime.
That runtime includes:
Effort allocation (adaptive thinking)
Memory persistence (thinking cache)
Output constraints (verbosity rules)
When all three degrade—even slightly—the system doesn’t fail gracefully.
It fails behaviourally.
The Key Takeaway
The model didn’t get worse.
The system deciding how it thinks did.
And that distinction is exactly why this episode matters.
References
Claude Code Regression Update: Anthropic’s April 23 Postmortem Changes the Story
Clients Were Right: Anthropic Admits Claude Code Got Dumber
https://kingy.ai/ai/clients-were-right-anthropic-admits-claude-code-got-dumber-not-claude-post-mortem/An update on recent Claude Code quality reports
https://www.anthropic.com/engineering/april-23-postmortemDeep News — Superlinear Academy
https://yage.ai/share/The Claude Code Nerf: An Invisible, Unilateral Downgrade
https://yage.ai/share/claude-code-runtime-regression-en-20260407.htmlAdaptive thinking - Amazon Bedrock
https://docs.aws.amazon.com/bedrock/latest/userguide/claude-messages-adaptive-thinking.htmlClaude Opus 4.6 adaptive reasoning
https://www.infoq.com/news/2026/03/opus-4-6-context-compaction/Adaptive thinking - Claude API Docs
https://platform.claude.com/docs/en/build-with-claude/adaptive-thinkingOpus 4.7 overview
https://artificialanalysis.ai/articles/opus-4-7-everything-you-need-to-knowDid Anthropic Secretly Nerf Claude?
https://thedroidguy.com/anthropic-nerf-claude-quality-degradation-explained-1273110Anthropic source code leak (NDTV)
https://www.ndtv.com/feature/2026-just-got-crazy-internet-erupts-after-anthropics-claude-source-code-leak-shakes-ai-industry-11294628Anthropic leaked its own Claude source code (Axios)
https://www.axios.com/2026/03/31/anthropic-leaked-source-code-aiClaude Code leak analysis (Dev.to)
https://dev.to/varshithvhegde/the-great-claude-code-leak-of-2026-accident-incompetence-or-the-best-pr-stunt-in-ai-history-3igmClaude Mythos leak https://absolutelyagentic.com/p/claude-mythos-the-ai-model-anthropic-won-t-release-to-the-public
Mythos leak coverage (Fortune)
https://fortune.com/2026/03/26/anthropic-says-testing-mythos-powerful-new-ai-model-after-data-leak-reveals-its-existence-step-change-in-capabilities/Mythos summary (Mashable)
https://mashable.com/article/claude-mythos-ai-model-anthropic-leakAnthropic second security lapse (Fortune)
https://fortune.com/2026/03/31/anthropic-source-code-claude-code-data-leak-second-security-lapse-days-after-accidentally-revealing-mythos/Reddit discussion
https://www.reddit.com/r/ClaudeAI/comments/1s9ai45/anthropic_leaked_512000_lines_of_claude_code/Alignment Forum discussion
https://www.alignmentforum.org/posts/K8FxfK9GmJfiAhgcT/anthropic-repeatedly-accidentally-trained-against-the-cotClaude Code leak breakdown
https://www.felamity.com/post/claude-code-leak-2026-what-happened-and-why-it-matters-for-ai-securityMythos video
Japanese coverage of quality regression
https://innovatopia.jp/ai/ai-news/98588/