From diagnosing AI debt to durable fixes (Part-3)
The aim: not just better prompts, but systems — encoded decisions, reusable context, visible cost signals, measurable quality checks, and living documentation

This is Part 3 of the series on getting the best from Claude code. Part 1 on Why you should chose Haiku as Default model and escalate if needed; Part 2 introduced three practical practices — repo/component Claude.md files, prompt caching, and context engineering. In this final instalment we move from diagnosis to action: concise, repeatable fixes you can apply to Decision, Context, Cost, Quality, and Knowledge debt so improvements stick and scale.

How to fix this — a practical playbook
Below is a compact, repeatable playbook that uses three core practices. Treat it as a checklist you can run on one workflow, measure results, then expand.
Overarching rules (apply everywhere)
Treat repeated human choices as code (routing rules, configs, tests).
Track per-decision telemetry: model, tokens in/out, cache hit, cost estimate, quality pass/fail, reviewer time.
Default to low-cost + cached context; escalate deterministically.
Small iterations: ship a pilot, measure 2 weeks, improve
Decision Debt → encode routing & audit trails
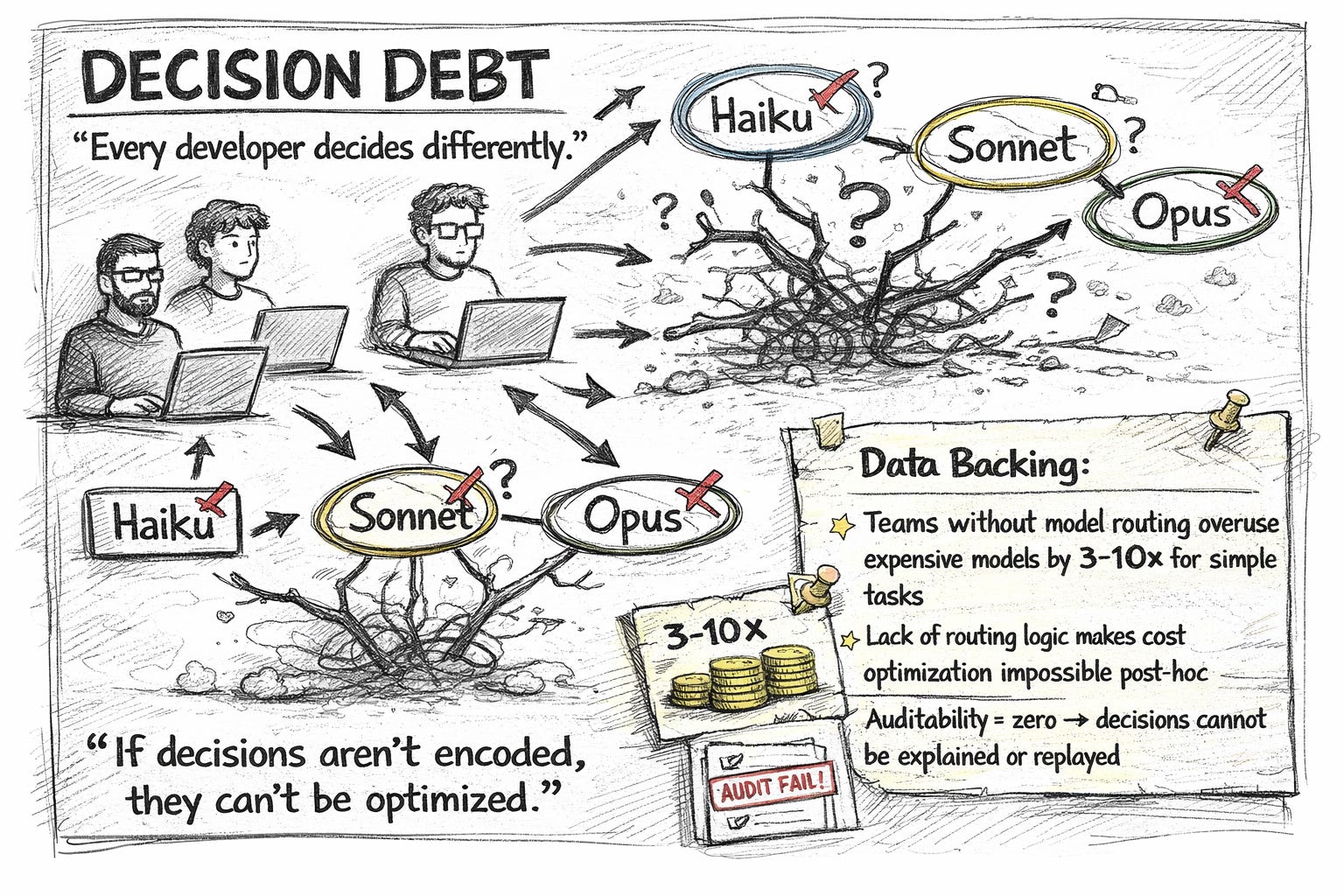
What to do
Build a small, central model_router library (or service) used by all callers. Return {model, reason} and log it.
Add deterministic escalation rules (cheap → standard → powerful).
Create audit logs for each decision (inputs, rule id, model, timestamp, outcome).
How the three practices help
Repo-specific Claude.md: documents routing policy, escalation rationale, and tests.
Context engineering: standardise inputs used to evaluate routing rules so decisions are deterministic.
Prompt caching: ensures cached outputs are tied to the chosen model + context version.
Quick checks
Unit test: simple_task -> Haiku; complex_task -> Sonnet.
Telemetry: ratio of escalations, average cost per decision.
Context Debt → componentise and version prompts
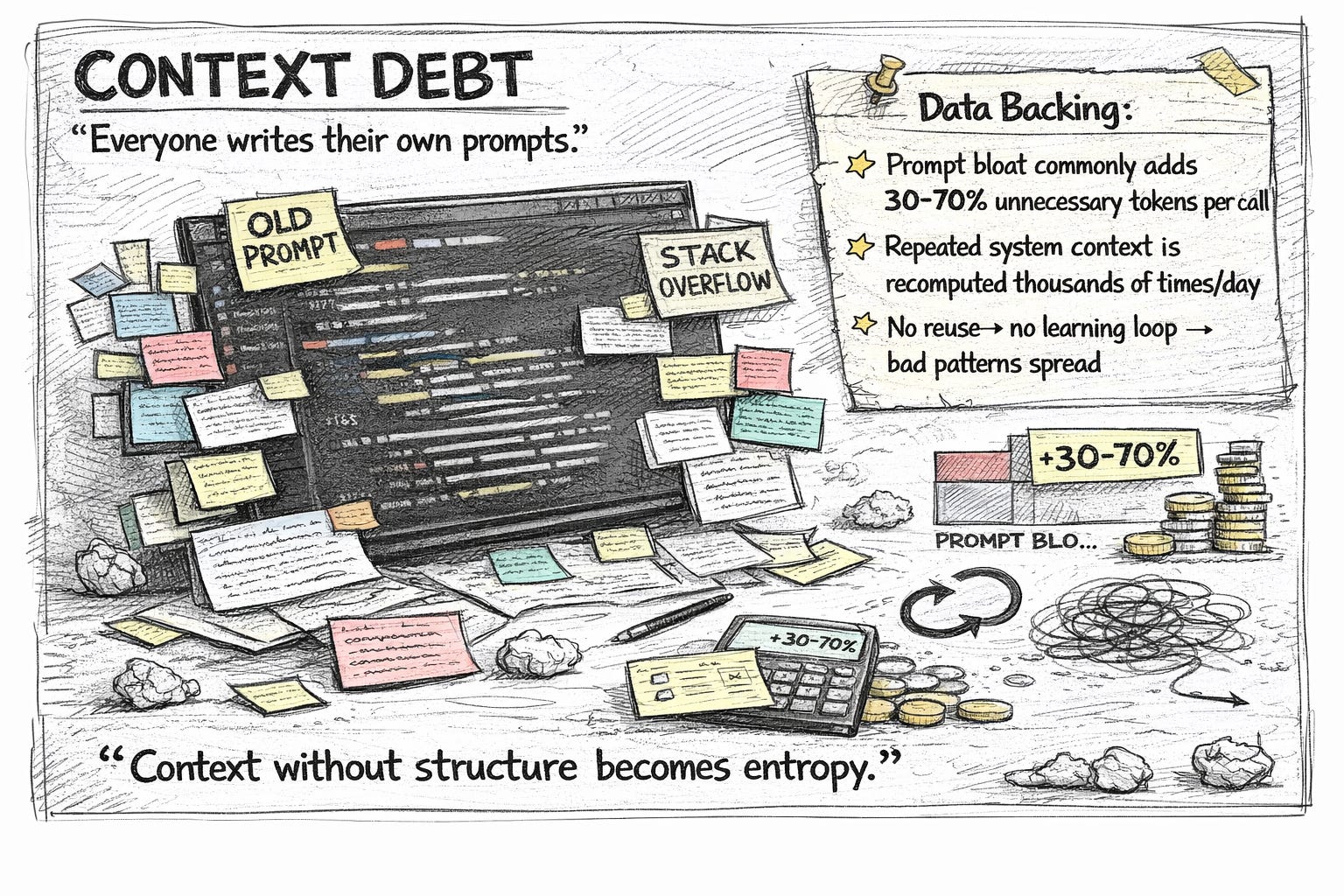
What to do
Extract repeated instruction blocks into named context components (tone, schema, safety, few-shot examples).
Reference components in prompts instead of copy-pasting text. Version each component (e.g., formatting@v1).
Store components in a shared context/ library and list them in Claude.md.
How the three practices help
Repo/component Claude.md: lists canonical components, versions, owners, and examples.
Context engineering: design small composable pieces (system msg, template, validators).
Prompt caching: cache by model+context_version+input_hash so long static context does not repeat tokens.
Quick checks
Lint: no prompt > X tokens without a valid reason.
CI: ensure PRs reference existing context components; fail if new ad-hoc system messages appear.
Cost Debt → visibility, hard budgets, and caching
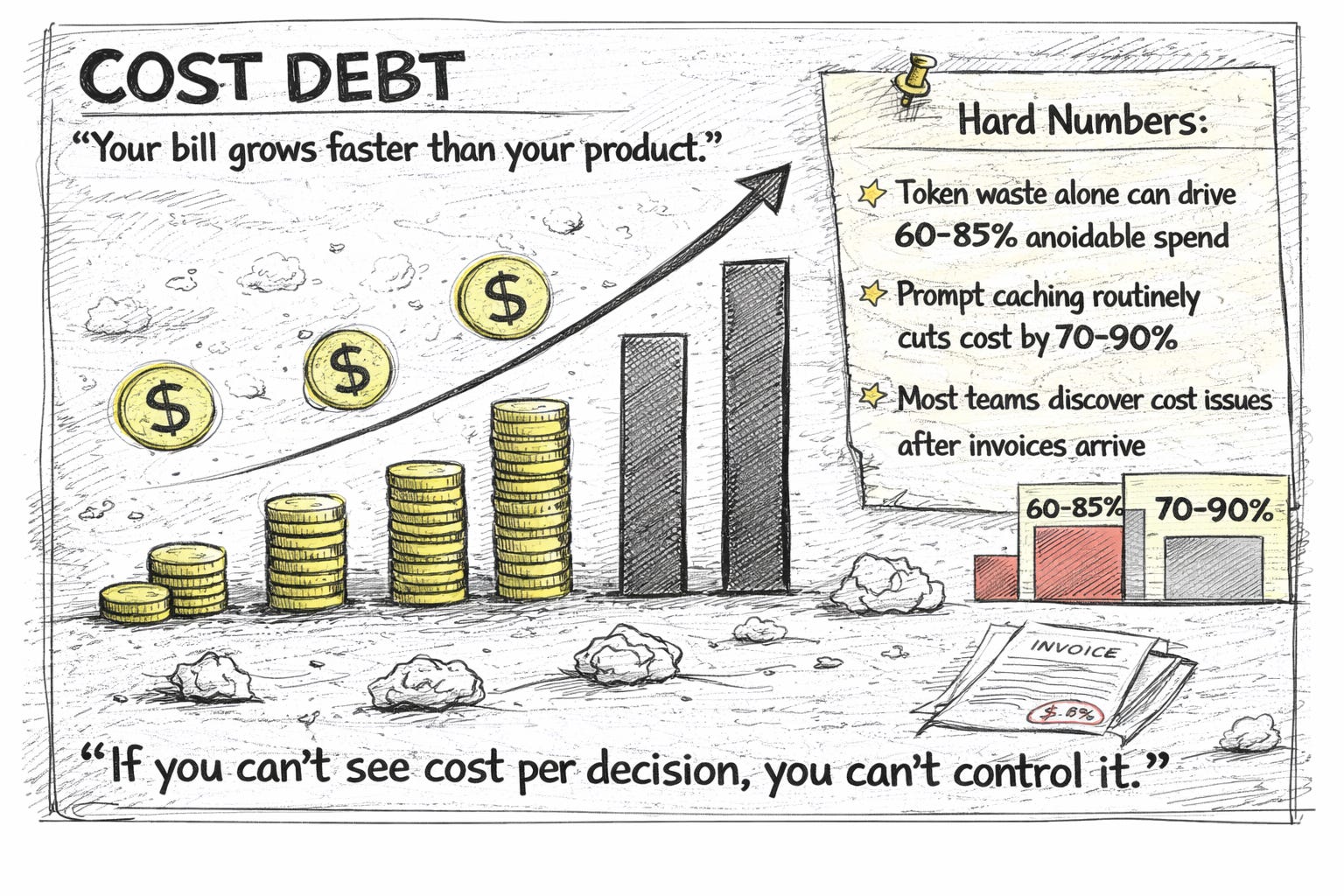
What to do
Instrument cost per decision: estimate/record model+tokens and attribute to feature/tenant.
Add prompt caching for idempotent requests with well-defined TTLs.
Set per-endpoint token budgets and alarms for runaway requests.
How the three practices help
Repo-specific Claude.md: defines budgets, caching policy, and cache keys.
Prompt caching: primary lever to reduce repeated spend (70–90% for many workflows).
Context engineering: move static content to cached components or to external retrieval layers.
Quick checks
Dashboard: cost per endpoint, cache hit rate, cost-per-decision trend.
Alert: any endpoint > budget for 24h triggers review.
Quality Debt → verification, confidence, and triage rules

What to do
Add automated verification steps after generation (schema/required-fields, checksum, simple heuristics).
Surface confidence signals (model provenance, verification pass/fail).
Route low-confidence or high-impact outputs to a human-in-the-loop workflow.
How the three practices help
Repo-specific Claude.md: documents acceptance criteria and QA checks.
Context engineering: include verification prompts or include required-field checks as part of the context.
Prompt caching: only cache outputs that pass verification and tag cache entries with verification metadata.
Quick checks
Metric: fraction of outputs that pass automated verify().
Metric: human-review hours per 1k outputs.
Knowledge Debt → living docs and onboarding

What to do
Create and enforce repo/component Claude.md files as the single source of truth for each service: model defaults, context components, caching keys, costs, QA checks, owners.
Add onboarding steps that require reading Claude.md and running a local sample.
Require PR updates to Claude.md when any prompt, routing rule, or cache policy changes.
How the three practices help
Repo-specific Claude.md: converts tribal knowledge into searchable, versioned artifacts.
Context engineering: clean, composable components make documentation concise and teachable.
Prompt caching: observable metrics help new hires validate behavior quickly.
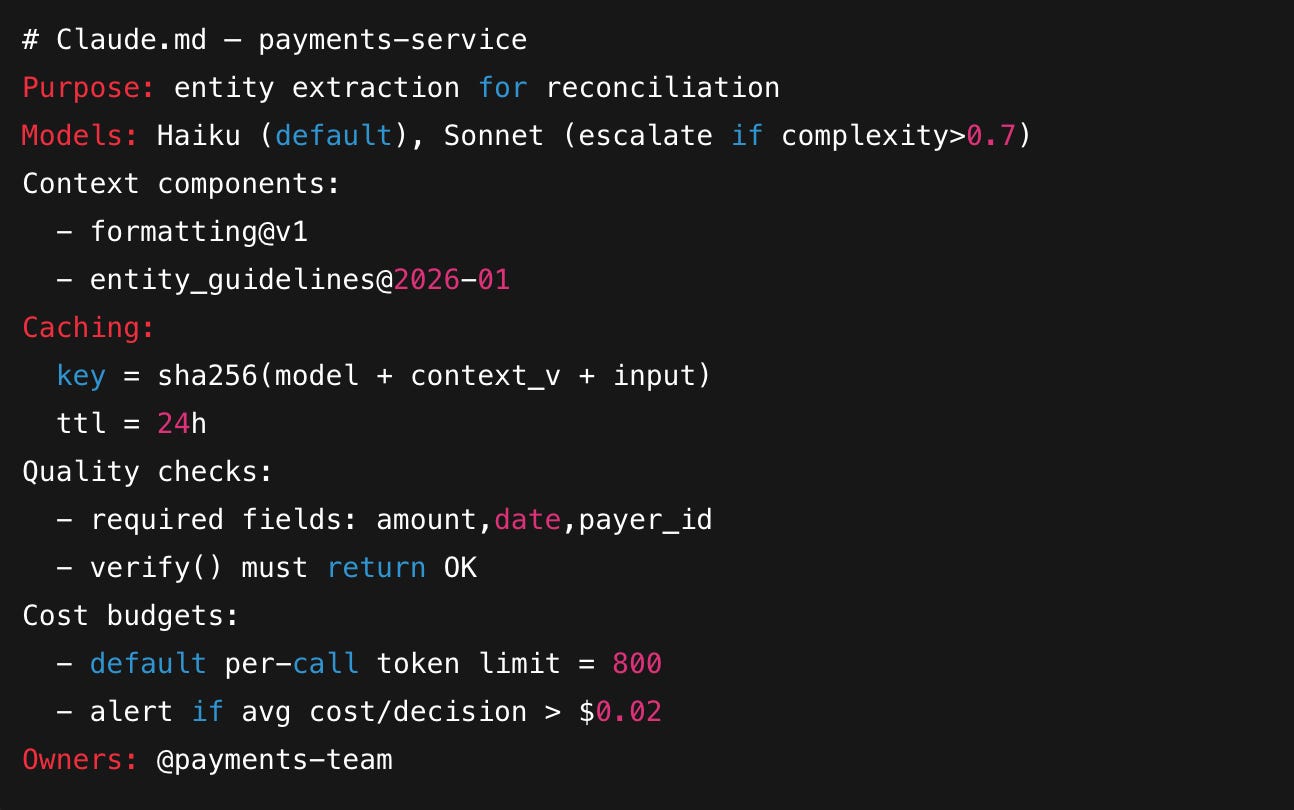
AI debt compounds quickly because it touches cost, product quality, and team bandwidth. The antidote is systematic: encode decisions, standardize context, make costs visible, automate basic quality checks, and document decisions as living artifacts. Using repo/component Claude.md, prompt caching, and context engineering transforms one-off prompt hacks into maintainable systems that scale.
Start small: pick one endpoint, add a Claude.md, instrument cost + quality, and ship. Measure results. Then expand. If you want, I’ll draft a Claude.md template tailored to one of your services (give me the service name and one example prompt) or produce a PR checklist you can drop into your repo.