Cloud Bills as Lagging Indicators of Design Debt


Most teams first meet cloud cost as a surprise.
The reflex is familiar: AWS is getting expensive. But that framing is too shallow to be useful. Cloud platforms are not mysterious in how they bill. They charge for what is consumed, and they do so with predictable rules. The real mystery is why the consumption pattern often looks irrational only after the bill arrives.
The answer is time.
Cloud bills are not leading indicators. They are lagging indicators. They reveal what the system has been doing for weeks or months after the design decision was made. By the time cost becomes visible, the architectural cause is already buried beneath new work, new releases, and new assumptions.
That is why cloud cost is better understood as a signal of design debt.
And in ML infrastructure, that debt is rarely singular. It usually appears in three forms at once: infra debts, context debts, and AI debts. Each one hides differently. Each one compounds differently. And each one demands a different kind of correction.
The First Debt: Infra Debt
Infra debt is the most visible kind of debt because it eventually shows up directly in the bill.
It begins with missing guardrails. A team enables S3 versioning to protect against accidental deletion, but no lifecycle policy is added. Logs are useful during development, so DEBUG logging continues into production. CloudWatch retention is left at default. Idle resources stay alive because nobody encoded expiration into the system.

None of these choices is obviously wrong in isolation. In fact, each one is defensible at the moment it is made. Versioning improves safety. DEBUG helps troubleshooting. Extra endpoints help experimentation. The mistake is not the decision itself. The mistake is the decision without a boundary.
That is what makes infra debt so common. It is created by omissions, not dramatic failures. A retention policy was not defined. A lifecycle rule was not added. A default was not set.
The cost curve is then slow and silent. Storage grows. Logs accumulate. Compute idles. Bills rise before teams notice the pattern.
This is why infra debt is the easiest debt to understand and the easiest to prevent. It belongs in infrastructure-as-code, in template defaults, and in policy enforcement. The goal is not to eliminate flexibility. The goal is to make the safe path the default path.
When that does not happen, cloud bills become the receipt of missing guardrails.
The Second Debt: Context Debt
Context debt is less visible, but often more dangerous.
It does not begin with storage or logs. It begins with assumptions. A team believes it understands the system, but the understanding is incomplete, undocumented, or no longer shared. The architecture starts drifting away from the mental model that originally justified it.
The Graviton example is a good one. On paper, ARM-based infrastructure promises savings. In practice, that promise depends on compatibility across Python wheels, native libraries, build pipelines, container images, CI runners, and fallback logic. A team that assumes “Graviton will work everywhere” without checking those dependencies is not making a cost optimization. It is making a context assumption.

That assumption can fail quietly at first. A wheel does not compile. A container image behaves differently. A CI job passes on one architecture and fails on another. The team then either falls back to x86, overprovisions for safety, or spends time debugging a problem that should have been discovered earlier.
That is context debt.
Unlike infra debt, context debt cannot be fixed by setting a lifecycle rule. It requires documentation, explicit trade-off decisions, shared ownership, and a memory of why the system is shaped the way it is. It is the debt of forgotten rationale.
This debt matters because cloud cost is often not caused by inefficient compute alone. It is caused by teams repeatedly paying for architectural uncertainty. When people no longer share the same model of the system, they build cautiously, duplicate resources, or choose the most conservative option available. Cost rises because confidence falls.
Context debt is where engineering and organizational memory collide.
The Third Debt: AI Debt
AI debt is the most compounding form of debt because it changes over time even when the system appears stable.
ML systems drift. Data changes. Labels shift. Models degrade. A pipeline that performed well last quarter may begin losing accuracy this quarter without any obvious operational failure. The system still runs. The endpoints still respond. The logs still look normal. But the model’s relationship to reality has weakened.
That is where AI debt begins.
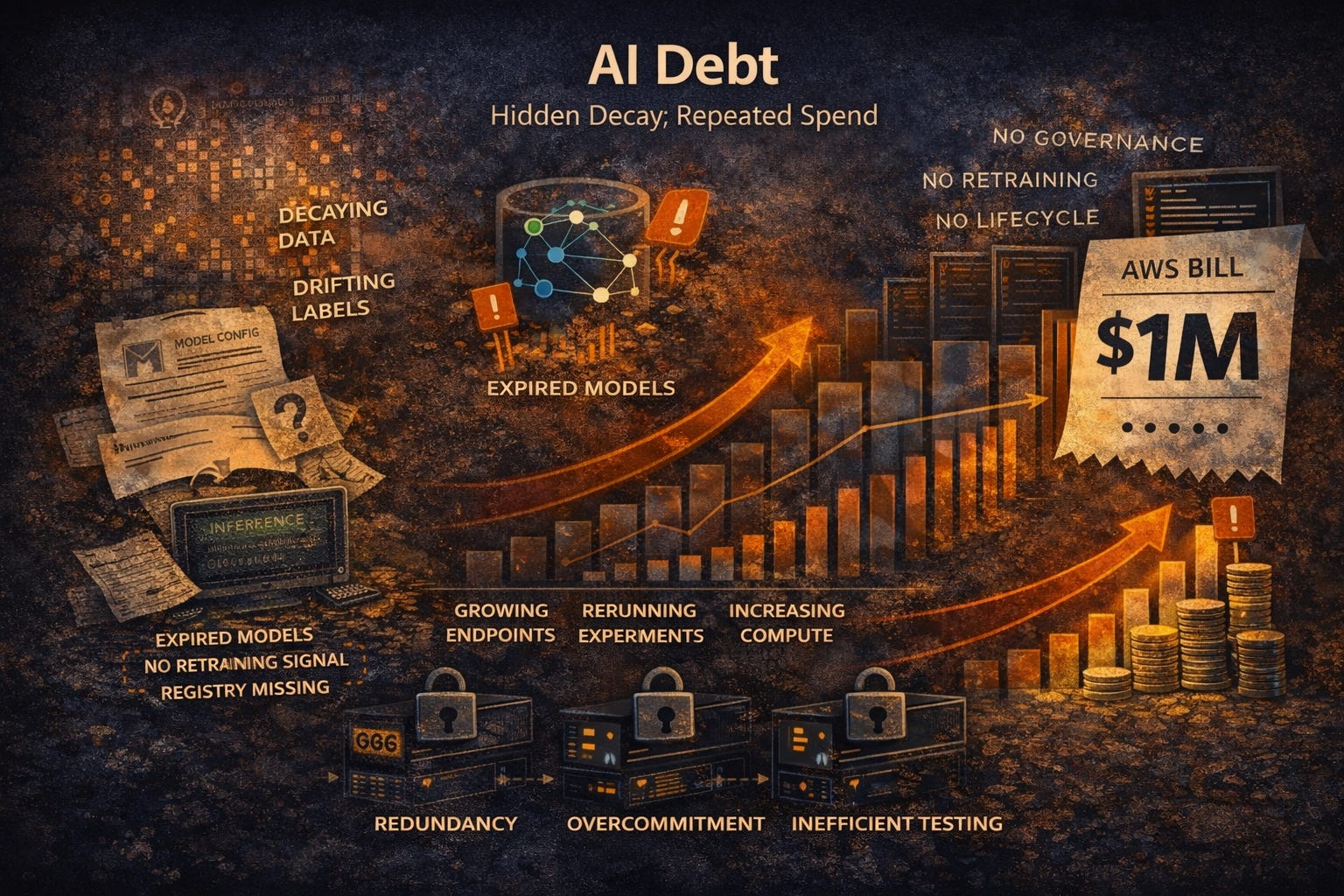
It includes data debt, model debt, and configuration debt. Data debt appears when training data is stale, incomplete, or insufficiently versioned. Model debt appears when there is no clear registry, no retraining signal, and no disciplined lifecycle. Configuration debt appears when inference pipelines become too complex, too wide, or too fragmented to reason about.
The financial impact is not always immediate. Sometimes the team compensates by increasing compute. Sometimes they add more endpoints. Sometimes they rerun experiments more often because confidence in the current model declines. Cost rises as a side effect of trying to keep the system trustworthy.
This is why AI debt is especially expensive. It does not merely create infrastructure spend. It creates repeated spend in response to lifecycle failure.
AI systems need more than deployment. They need governance, monitoring, versioning, and retraining discipline. Without that, the bill does not just reflect compute. It reflects the hidden cost of model decay.
Parjanya 2.0 and the Shape of the Debts
The Parjanya 2.0 work made these debt types visible in practice in the first month of production before the public launch.
S3 versioning was enabled to protect checkpoint uploads, but expiration was not configured, so old versions accumulated. That was infra debt. CloudWatch logs were verbose because DEBUG was convenient during development, but the logging policy was never tightened for production. That was infra debt again. Graviton was treated as a simple optimization, but dependency compatibility had not been fully validated. That was context debt. SageMaker endpoints were created for experimentation and then forgotten. That was a mix of infra debt and AI debt, because the experimental infrastructure had no lifecycle discipline.
The point of the case study is not that AWS behaved badly. AWS behaved exactly as designed.
The point is that the system behaved exactly as the team allowed it to behave.
That is what design debt means. The bill is not the cause. The bill is the evidence.
Designing Guardrails Instead of Chasing Bills
Once these debts are understood, the response becomes clearer.
The solution is not to chase lower cloud bills as a separate exercise. That often turns into cleanup theater. Delete a few things. Reduce a few logs. Switch a few instances. The bill improves temporarily, but the pattern remains.
The better approach is to design guardrails.
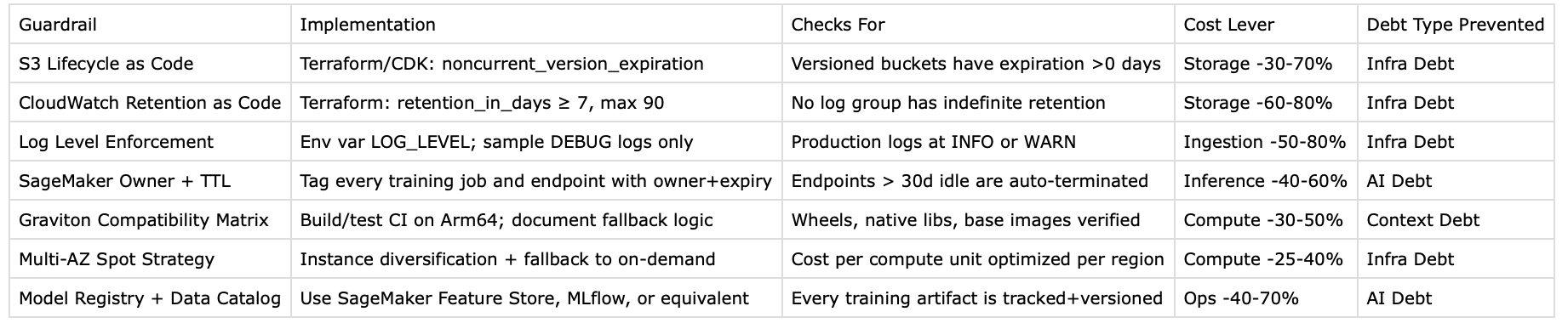
Guardrails make cost-aware behaviour the default. Versioned S3 buckets get lifecycle policies by template, not by memory. Log groups get retention defined by policy, not by hope. Production logging defaults to INFO, not DEBUG. Endpoint ownership is tagged, expiration is explicit, and idle resources can be terminated automatically. ARM migration is treated as a compatibility project, not a migration slogan. ML models are registered, versioned, and monitored as living assets rather than static artifacts.
This is the crucial shift: cost control stops being reactive once the system itself carries the discipline.
That is what sustainable ML infrastructure looks like. Not a promise of cheaper cloud, but a design where cloud cost is structurally constrained.
The Operating Lesson
If there is one lesson across infra debts, context debts, and AI debts, it is this:
Cloud bills are delayed signals of system intent.
They tell you what your system actually did after the memory of the decision has faded. They show whether your guardrails were real, whether your assumptions were valid, and whether your ML lifecycle was under control.
That is why the right question is not “Why is AWS so expensive?”
The right question is:
Which debts are we carrying into production, and which ones are we choosing not to see yet?
That question changes the conversation from billing to design. From cost reduction to system maturity. From cleanup to prevention.
And once you see cloud bills that way, you stop treating them as a nuisance. You start treating them as architecture feedback.
That is the real value of the receipt.
Additional metrics

Further Reading
My work:
Why We Could Only Use AWS Graviton for 1 of Our 4 ML Lambdas
The Silent Storage Bomb: What S3 Versioning Doesn’t Tell You
External resources: