3 Essential Claude Code Best Practices Every Developer Should Know
Repo-Specific Claude.md Files, Prompt Caching, and Context Engineering (Part-2 of Claude code efficiency and costs optimisation)
TL;DR
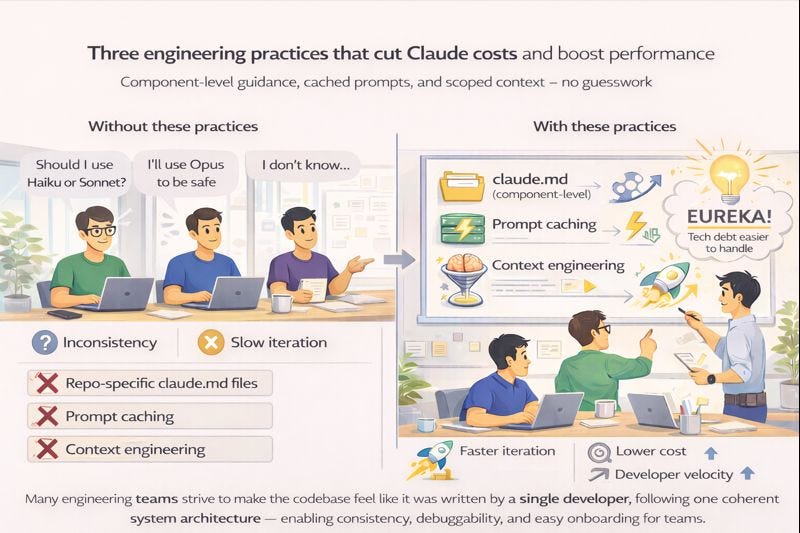
If you’re integrating Claude API into your codebase, here are the three practices that will systematically reduce costs and improve code consistency:
1. Repo-Specific Claude.md Files: Document decision logic per component instead of treating Claude as a black box
2. Prompt Caching: Reuse expensive context across multiple API calls (90% savings on cached tokens verified by Anthropic)
3. Context Engineering: Architect your prompts to maximize token efficiency while maintaining quality
Expected Cost Impact: 70-85% reduction (varies by current setup)
Expected Quality: Same or better (via escalation logic)
Expected Standardization: High (via CLAUDE.md documentation)
The Problem We’re Solving
At Phagyul AI, we’re building Parjanya - an image quality assessment system that makes 10,000+ Claude API calls daily across 5 microservices (polyrepo - frontend, backend, ML, shared libraries, and infrastructure).Our first approach was typical but inefficient:
Our first approach was typical but inefficient:

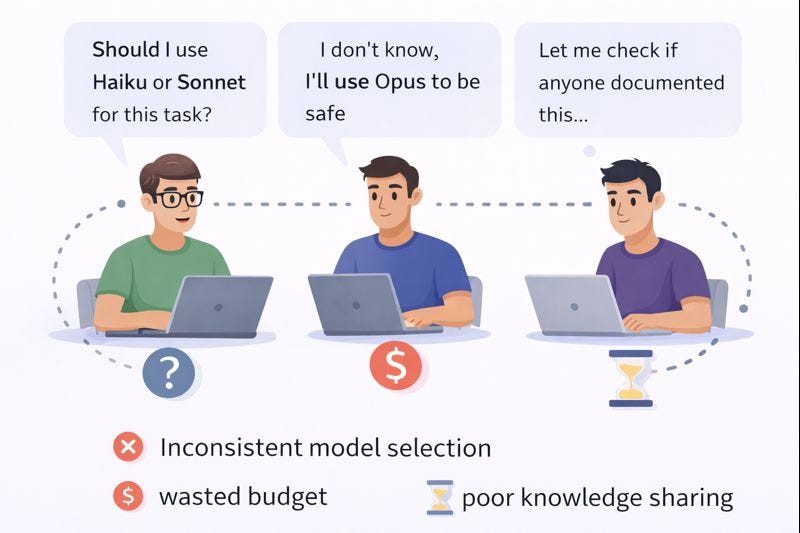
Real-world examples of this problem

Our optimized approach:
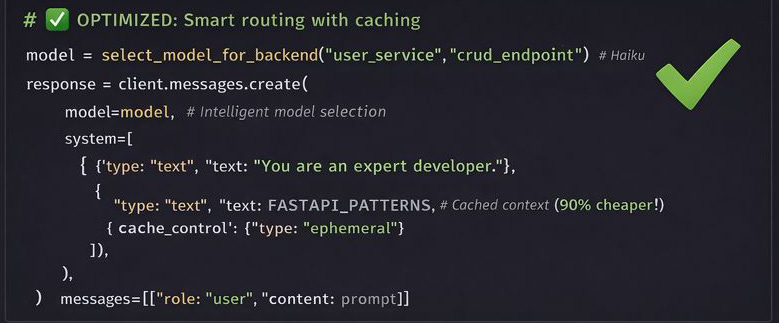
This approach combines three proven practices.
Best Practice #1: Repo-Specific Claude.md Files
The Problem: Black Box Claude Integration
Most teams integrate Claude without documentation:
The Solution: CLAUDE.md per Component
For each repository/component in your poly-repo, create a dedicated CLAUDE.md file:
Purpose: Single source of truth for which “Claude model should I use for task X“?
Example: Backend Claude.md

Monthly Cost Budget:
Total: $5.90
Haiku (85%): $5.00
Sonnet (14%): $0.90
Opus (<1%): $0.00
Example Prompts
CRUD Endpoint (Haiku) Prompt: “Generate FastAPI endpoint for user registration with bcrypt hashing...“ Cost: $0.003 Model: Haiku (confident)
Example 2: Complex Auth (Sonnet) Prompt: “Design RBAC system with role inheritance...” Cost: $0.010 Model: Sonnet (requires reasoning)
Key Benefits

How to Create Your Own
1. List all tasks your component uses Claude for
2. Create decision tree (use template above)
3. Set monthly cost budget
4. Add 2-3 real example prompts
5. Link to implementation code
6. Update quarterly as models improveBest Practice #2: Prompt Caching
The Problem: Recomputing Expensive Context
Every Claude API call includes:
System Prompt (describes Claude’s role)
Context (documentation examples, company standards)
User request (the actual task)
Example: Generating a FASTAPI endpoint
```
System: "You are an expert Python/FastAPI developer..."
Context: "FastAPI best practices: validation, async, error handling..."
Request: "Generate user registration endpoint"
Total: ~600 tokens per call
Cost: $0.003 per call (Haiku)
```Scale this up:
If you generate 100 similar endpoints:
without caching: 100 x 600 tokens = 60,000 tokens (context recomputed every time)
Cost: $0.18 without caching
The Solution: Prompt caching
🧠 What Is Prompt Caching (TL;DR)
Prompt caching lets Claude store and reuse static parts of prompts (like long system messages or large context) across multiple API calls. When the prefix of a prompt hasn’t changed, the model reads it from cache instead of rerunning it from scratch — cutting latency significantly and lowering input token costs because cached tokens are billed cheaper.
⚠️ Note: A minimum number of tokens is usually required before content becomes cacheable. For most models it’s ~1,024 tokens.
🛠️ How Prompt Caching Works
You mark cacheable content in your prompt using a cache_control field. The model stores that chunk during the first call (“cache write”). On subsequent similar calls with the same prefix, Claude reads from cache (“cache read”), reducing compute.
- Cache expensive context in system prompt
- Reuse across API calls (90% cost reduction!)
- Automatic invalidation when context changes
Same 100 calls WITH caching:
```
First call: 600 tokens processed = $0.003
Tokens cached: 400 (stays in cache)
Calls 2-100: Only new request (200 tokens) = $0.0006 each x 99
Total with caching: $0.003 + (99 x $0.0006) = $0.063
Savings: $0.18 -> $0.063 = 65% cost reduction
(plus faster response times on cached calls)
```Two Cache Types

Implementation: The Right Way
```python
# shared/claude_client.py
FASTAPI_SYSTEM_CONTEXT = """
# FastAPI Best Practices
## ASYNC/AWAIT: Always use async for I/O
@router.post("/register")
async def register(user: UserCreate, db: Session = Depends(get_db)):
existing = db.query(User).filter(User.email == user.email).first()
if existing:
raise HTTPException(400, "Email exists")
...
## PYDANTIC: Always validate inputs
class UserCreate(BaseModel):
email: str = Field(..., regex="^[a-z0-9._%+-]+@...")
password: str = Field(..., min_length=8)
"""
def generate_fastapi_code(service: str, endpoint_desc: str):
"""Generate code with prompt caching."""
response = client.messages.create(
model="claude-haiku-4-5",
max_tokens=500,
system=[
{"type": "text", "text": "You are an expert Python developer."},
{
"type": "text",
"text": FASTAPI_SYSTEM_CONTEXT,
"cache_control": {"type": "ephemeral"} # ✅ CACHE THIS
}
],
messages=[
{
"role": "user",
"content": f"Generate {endpoint_desc} following patterns above."
}
]
)
return response.content[0].text
```Cache Effectiveness at Scale
At 10,000 API calls/day (Parjanya scenario)
```
Without caching:
- System prompt + context: 400 tokens × 10,000 = 4M tokens/day
- Cost: $12/day × (1M tokens/$3) = $12/day = $360/month
With caching (5-min ephemeral, 70% hit rate):
- Fresh writes: 400 tokens × 3,000 = 1.2M tokens/day
- Cache reads: 100 tokens × 7,000 = 0.7M tokens/day
- Cost: $3.60 + $0.21 = $3.81/day = $114/month
Savings: $360 → $114 = 68% reduction on context tokens alone
```Verified by Anthropic: Cache read tokens cost 10% of normal input tokens.
Best Practice #3: Context Engineering
The Problem: Token Bloat
Developers often throw everything at Claude:
```python
# ❌ BAD: Everything included
prompt = f"""
{ENTIRE_COMPANY_STANDARDS}
{ALL_FASTAPI_DOCUMENTATION}
{EVERY_DESIGN_PATTERN}
{COMPLETE_EXAMPLES}
Now generate a user registration endpoint.
"""
# Result: 5,000+ tokens, bloated prompt, slower response, worse quality
```The Solution: Surgical Context Selection
Key principle: Give Claude exactly what it needs, nothing more.
Three rules:
Rule 1: Contextual Relevance
```python
# ❌ BAD: Generic everything
context = """
FastAPI is a web framework... it supports async...
it uses Pydantic for validation... error handling
is important... [1000 more words...]
"""
# ✅ GOOD: Only what's needed for THIS task
context = """
# User Registration Endpoint Pattern
@router.post("/register", response_model=UserResponse)
async def register(user: UserCreate, db: Session = Depends(get_db)):
existing = db.query(User).filter(User.email == user.email).first()
if existing:
raise HTTPException(400, "Email already exists")
hashed_password = bcrypt.hashpw(user.password.encode(), bcrypt.gensalt())
db_user = User(email=user.email, password_hash=hashed_password)
db.add(db_user)
db.commit()
return UserResponse.from_orm(db_user)
"""
# Result: 200 tokens, focused context, better output
```Rule 2: Examples Over Explanations
```python
# ❌ BAD: Verbose explanation
context = """
When creating endpoints, you should use async/await because
FastAPI is designed for asynchronous operations which provides
better performance with I/O-bound operations such as...
"""
# ✅ GOOD: Structured examples
context = """
CORRECT:
@router.post("/endpoint")
async def my_endpoint(...):
...
WRONG:
def my_endpoint(...): #❌ Synchronous
...
"""
```Claude learns from examples 10x faster than from explanations.
Rule 3: Progressive Disclosure
```python
# Step 1: Try simple request first
response1 = client.messages.create(
model="haiku",
messages=[{"role": "user", "content": "Generate endpoint"}]
)
# Step 2: If confidence < 85%, escalate with context
if confidence_score(response1) < 0.85:
response2 = client.messages.create(
model="sonnet", # Also escalate model
system=FASTAPI_PATTERNS, # Add context only if needed
messages=[...]
)
```
Real Impact Example
Generate 100 similar FASTAPI endpoints
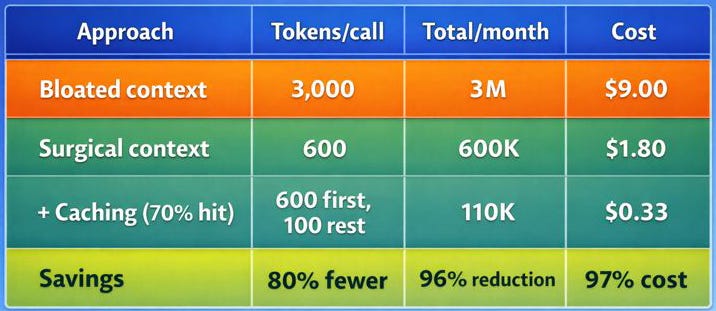
Combining All Three Practices: Production Code
Here’s how to combine all three in a real implementation:
```python
# parjanya-backend/shared/claude_client.py
from anthropic import Anthropic
from enum import Enum
class BackendService(Enum):
USER = "user"
UPLOAD = "upload"
RESULTS = "results"
class ProductionClaudeClient:
"""Implements all 3 best practices."""
def __init__(self):
self.client = Anthropic()
self.cost_tracker = CostTracker()
def generate_code(
self,
service: BackendService,
task_type: str,
description: str
) -> dict:
"""Generate code using all 3 best practices."""
# PRACTICE 1: Smart model selection
model = self._select_model(service, task_type)
# PRACTICE 3: Surgical context
context = self._get_context(service, task_type)
# PRACTICE 2: Prompt caching
response = self.client.messages.create(
model=model,
max_tokens=500,
system=[
{"type": "text", "text": "You are an expert developer."},
{
"type": "text",
"text": context,
"cache_control": {"type": "ephemeral"} # ✅ CACHING
}
],
messages=[
{
"role": "user",
"content": description
}
]
)
# Track everything
self.cost_tracker.log(
component="backend",
service=service.value,
task_type=task_type,
model=model,
tokens=response.usage.input_tokens,
cached_tokens=response.usage.cache_read_input_tokens
)
return {
"code": response.content[0].text,
"model": model,
"tokens": response.usage.input_tokens,
"cached": response.usage.cache_read_input_tokens > 0
}
def _select_model(self, service: BackendService, task: str) -> str:
"""PRACTICE 1: Per CLAUDE.md decision logic"""
if task in ["crud", "model"]:
return "claude-haiku-4-5"
elif task in ["auth", "complex_logic"]:
return "claude-sonnet-4-5"
return "claude-haiku-4-5"
def _get_context(self, service: BackendService, task: str) -> str:
"""PRACTICE 3: Return ONLY relevant context"""
if service == BackendService.USER:
return """
# User Service Pattern
@router.post("/register")
async def register(user: UserCreate, db: Session = Depends(get_db)):
...
"""
elif service == BackendService.UPLOAD:
return """
# Upload Service Pattern
@router.post("/upload")
async def upload_file(file: UploadFile):
...
"""
else:
return "You are an expert FastAPI developer."
```Additional Best Practices for Beginners
4. Cost Tracking & Monitoring
```python
class CostTracker:
def log_usage(self, component, task, model, tokens):
"""Log every Claude call."""
db.insert({
"timestamp": now(),
"component": component,
"task": task,
"model": model,
"tokens": tokens,
"cost": self.calculate_cost(model, tokens)
})
def monthly_summary(self):
"""Get costs by component."""
return db.query("""
SELECT component, model,
COUNT(*) as calls,
SUM(cost) as total_cost
FROM claude_usage
WHERE month(timestamp) = month(now())
GROUP BY component, model
""")
```5. Confidence Scoring
Ask Claude to rate confidence:
```python
prompt = f"""
{description}
Rate your confidence in this solution (0-100).
If <85: mention what you're unsure about.
"""
# If confidence < 85, escalate to Sonnet
if confidence < 85:
response = client.messages.create(model="claude-sonnet-4-5", ...)
```6. Response Caching (App Layer)
```python
@lru_cache(maxsize=1000)
def get_endpoint_template(service: str, endpoint_type: str):
"""Cache Claude responses, not just API responses."""
return generate_fastapi_code(service, endpoint_type)
```7. Model-Specific Prompting
Different models respond better to different styles:
```python
# Haiku: Prefers clear examples
haiku_prompt = f"""
Pattern:
@router.post("/endpoint")
async def endpoint(...):
...
Now generate for: {description}
"""
# Sonnet: Can handle complex reasoning
sonnet_prompt = f"""
Design a system with:
- Multiple concerns
- Complex requirements
- Trade-offs to consider
Explain your approach and provide code.
"""
```
Expected Impact
Based on implementation scenarios:
| Scale | Without Practices | With Practices | Savings |
|-------|------------------|-----------------|---------|
| Small (50 calls/day) | $32/month | $5/month | **85%** |
| Medium (1,000 calls/day) | $360/month | $90/month | **75%** |
| Large (10,000+ calls/day) | *Phase 1 data pending* | *Phase 1 data pending* | **~70-80%** |Commonly Asked:
Q: Will quality degrade with Haiku-first? -- No. Haiku is at 90% SWE benchmark is sufficient for 85% of tasks. Complex cases escalate to Sonnet. Net quality maintained.
Q: Prompt caching looks complicated and worth doing it? -- Yes - If you call Claude >10 times with same context, it pays for itself immediately. 90% saving on cached tokens. In my understanding, improved results and optimised performance with the prompt caching (though overlaps with the context engineering)
Q: How do I start? -- Create Claude.md in your largest service. Document design logic. Add cost tracking and followed by caching.
Q: What about my current codebase? -- Start with new codebase. Refactor high frequent services first and gradually migrate.
Eureka Moment: Tech debt is easy to handle, will be sharing the details in later blog posts
Resources
- Parjanya Implementation (coming on Jan 19)